Больше не обманывайтесь локальным развертыванием DeepSeek R1, я помогу вам преодолеть все подводные камни. Включено бесплатное руководство |

Купите это! Воспользуйтесь китайским Новым годом, чтобы выучить его, когда у вас будет время.
В этот весенний фестиваль DeepSeek похож на сома, который волнует сердца бесчисленного количества людей дома и за рубежом. В то время как Кремниевая долина все еще погружена в шок, вызванный DeepSeek, массовая «золотая лихорадка» искусственного интеллекта постепенно проникает в основные отечественные платформы электронной коммерции.
Умные клавиатуры, которые утверждают, что имеют встроенный DeepSeek, продаются почти миллионом в день, а блоггеры продают курсы, на которых можно легко заработать 50 000 в день. Появилось даже 2650 поддельных веб-сайтов, что побудило DeepSeek объявить о чрезвычайной ситуации.

В толпе были встревоженные люди, золотоискатели и еще более выжидающие наблюдатели. Когда у них наконец появилось время успокоиться и испытать этот артефакт ИИ после Дня работников, они получили холодный ответ от DeepSeek R1:
Сервер занят, повторите попытку позже.
Благодаря стратегии DeepSeek с открытым исходным кодом, пока нетерпеливо ждали, руководство по локальному развертыванию DeepSeek R1 быстро стало популярным во всем Интернете и даже стало новым раундом читов с искусственным интеллектом для сбора лука-порея.
Сегодня, не используя 998 или 98, мы дадим вам руководство по локальному развертыванию DeepSeek R1.
Модель искусственного интеллекта DeepSeek только что перевернула раскаленный добела рынок электроэнергии США – Bloomberg
Однако он был развернут, но не полностью.
Хотя многие блоггеры курсов утверждают, что могут легко запустить полноценную версию DeepSeek R1, параметры полнокровной модели R1 достигают 671B, а один только файл модели требует 404 ГБ дискового пространства, а для запуска требуется около 1300 ГБ видеопамяти.
Для обычных игроков без карт условия работы суровые и порог крайне высок. Исходя из этого, мы могли бы также обратить внимание на четыре небольшие модели дистилляции DeepSeek R1, соответствующие Qwen и Llama:
- DeepSeek-R1-Дистилл-Лама-8B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Дистилл-Лама-70Б
Зарубежные блоггеры собрали для вас соответствующие конфигурации. Обратите внимание: пока графический процессор соответствует требованиям к видеопамяти или превосходит их, модель все равно может работать на графическом процессоре с более низкими характеристиками. Но настройка не оптимальна и может потребовать некоторой настройки.
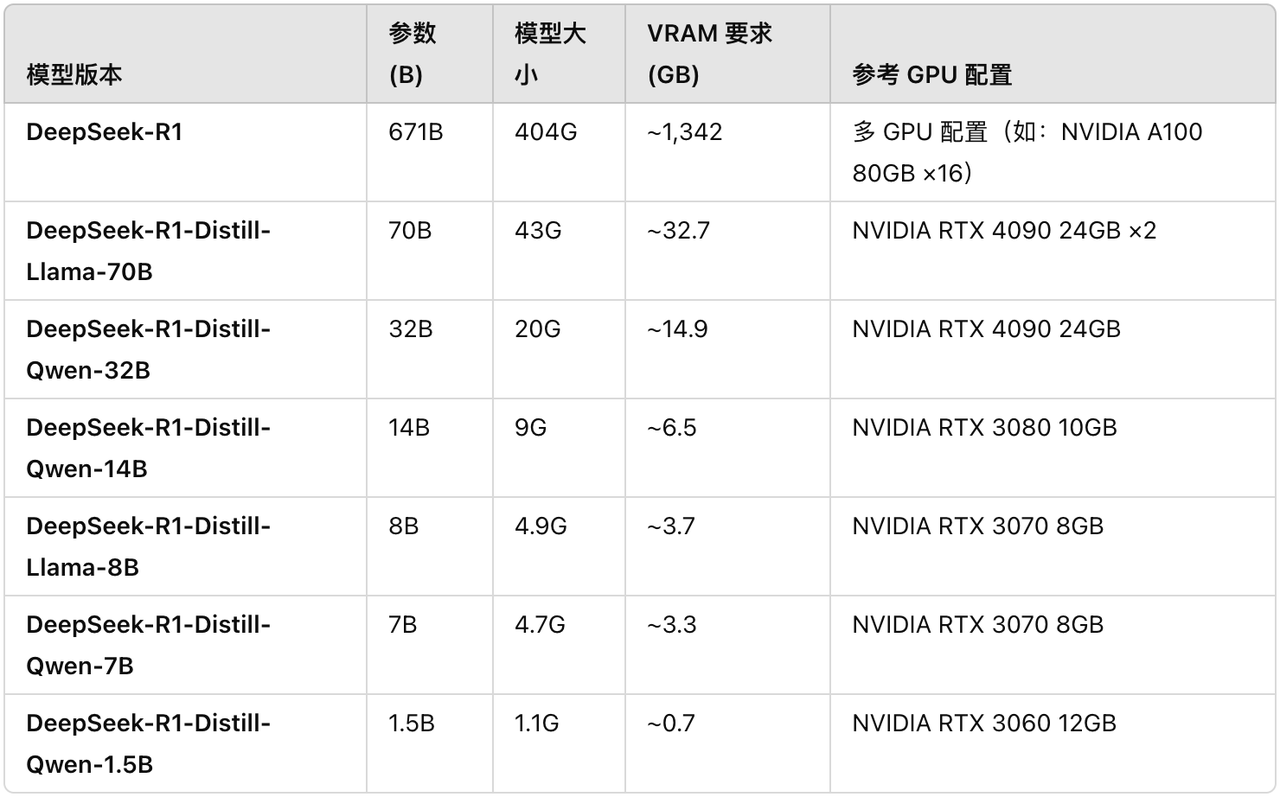
 https://dev.to/askyt/deepseek-r1-671b-complete-hardware-requirements-optimal-deployment-setup-2e48
https://dev.to/askyt/deepseek-r1-671b-complete-hardware-requirements-optimal-deployment-setup-2e48
Локальное развертывание небольшой модели R1, два метода, изучение за один раз
Устройство, которое мы рассматриваем на этот раз, — это Mac Studio M1 Ultra с памятью 128 ГБ. Учебное пособие по основному локальному развертыванию DeepSeek, два метода, вы можете изучить его за один раз.
ЛМ Студия
Первым делом появится минималистичная версия Xiaobai. Загрузите LM Studio по модели персонального компьютера на официальном сайте (lmstudio.ai). Затем для удобства использования рекомендуется нажать в правом нижнем углу, чтобы сменить язык на упрощенный китайский.
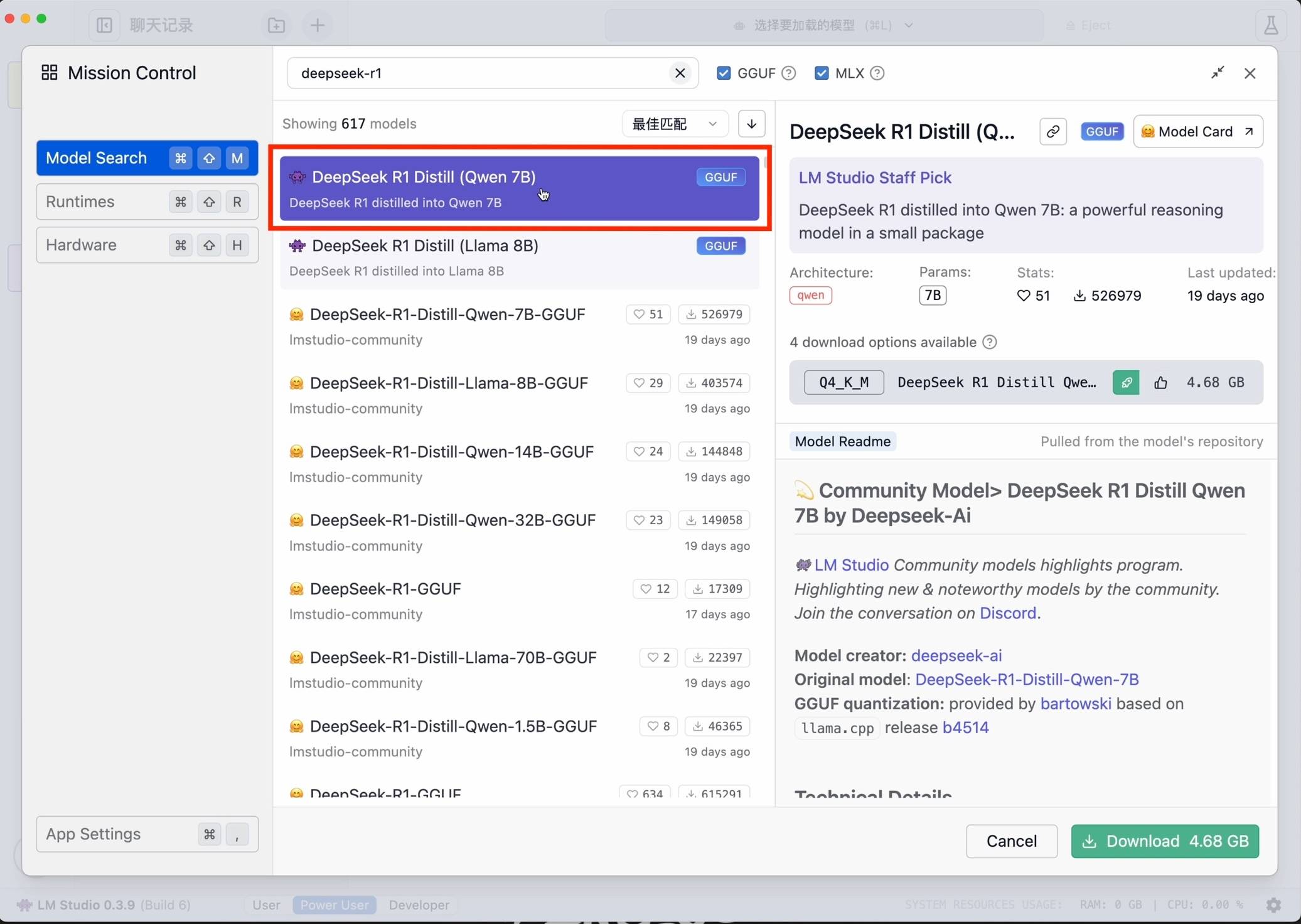
Затем найдите deepseek-r1 и выберите подходящую версию для загрузки. В качестве примера я выбрал в качестве базовой небольшую модель 7B, переработанную из модели Ali Qwen.
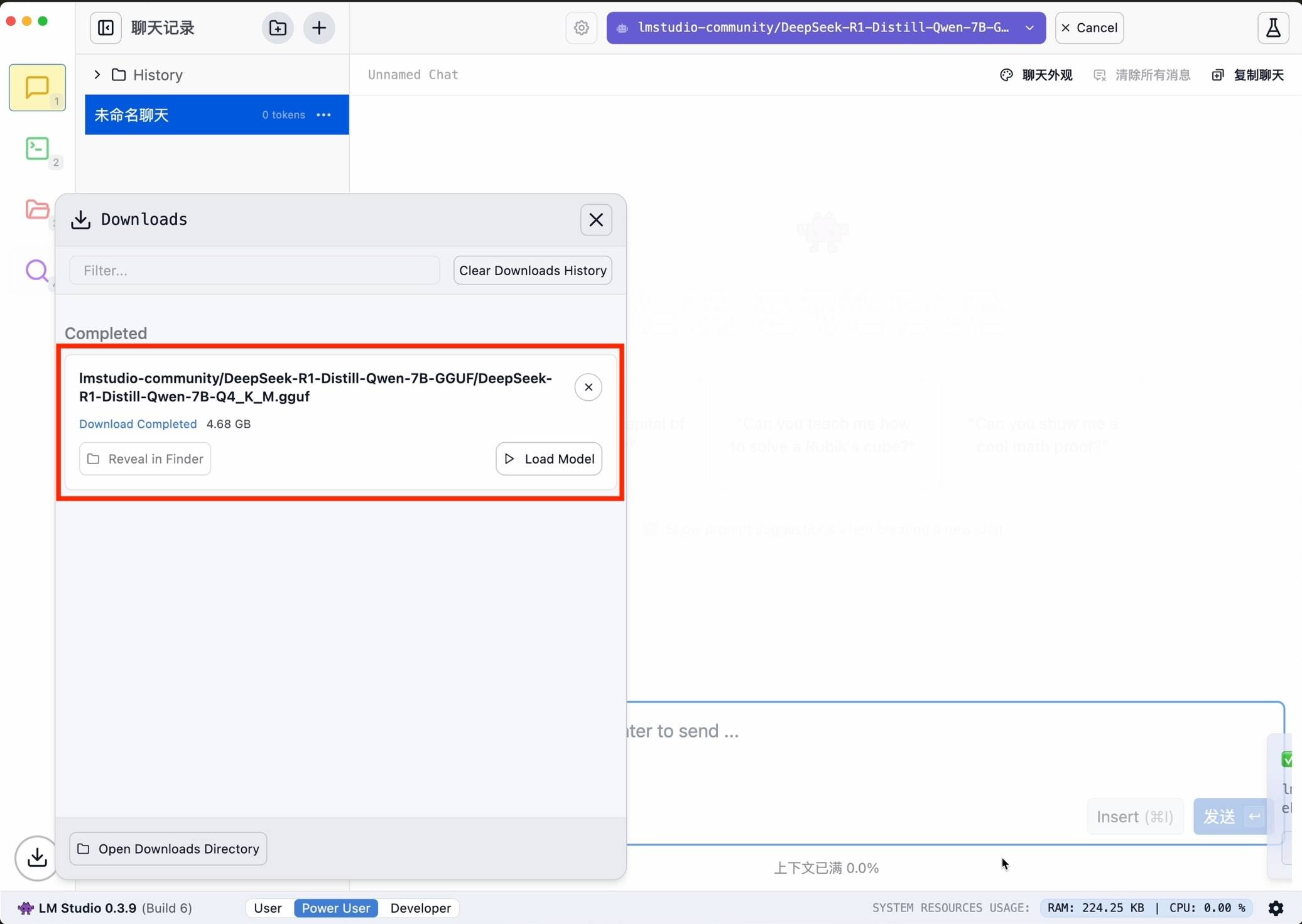
После завершения настройки ее можно запустить одним щелчком мыши.
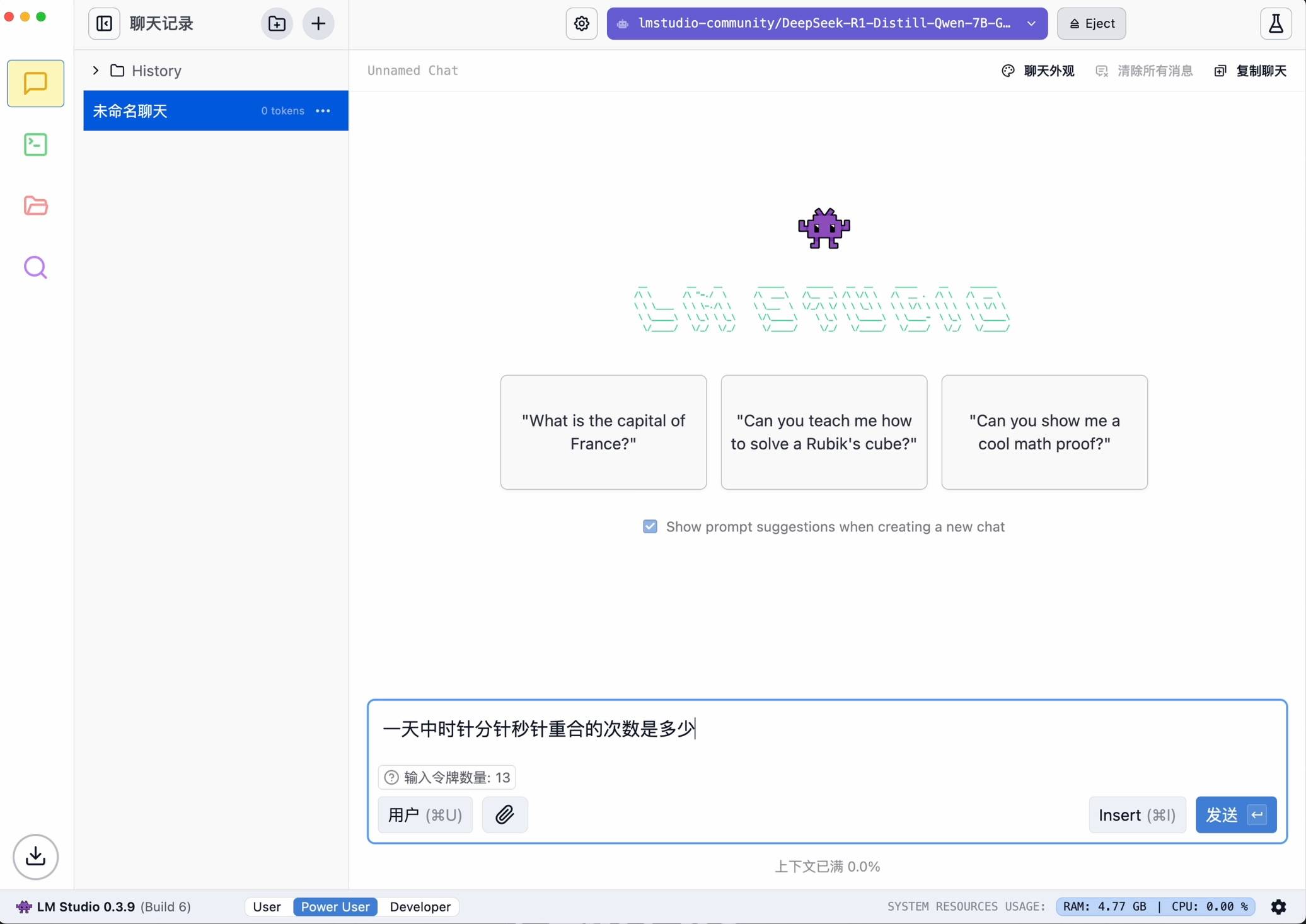
Преимущество использования LM Studio заключается в том, что он не требует кодирования и имеет дружественный интерфейс, но требует высокой производительности при запуске больших моделей, поэтому новичкам больше подходит использование базовых функций.
Оллама
Конечно, мы также подготовили расширенные планы для пользователей, которым нужен более глубокий опыт.
Сначала скачайте и установите Ollama с официального сайта (ollama.com).
После запуска откройте инструмент командной строки. Пользователи Mac используют клавиатуру Command+Пробел, чтобы открыть инструмент «Терминал». Пользователи Windows используют клавиатуру для запуска Win+R и вводят cmd, чтобы открыть инструмент «Командная строка».
Введите кодовую команду (ollama run deepseek-r1:7b) в окне, чтобы начать загрузку. Обратите внимание на ввод статуса на английском языке, проверьте пробелы и тире и введите необходимое название версии после двоеточия.

После завершения настройки вы можете начать разговор в окне командной строки.
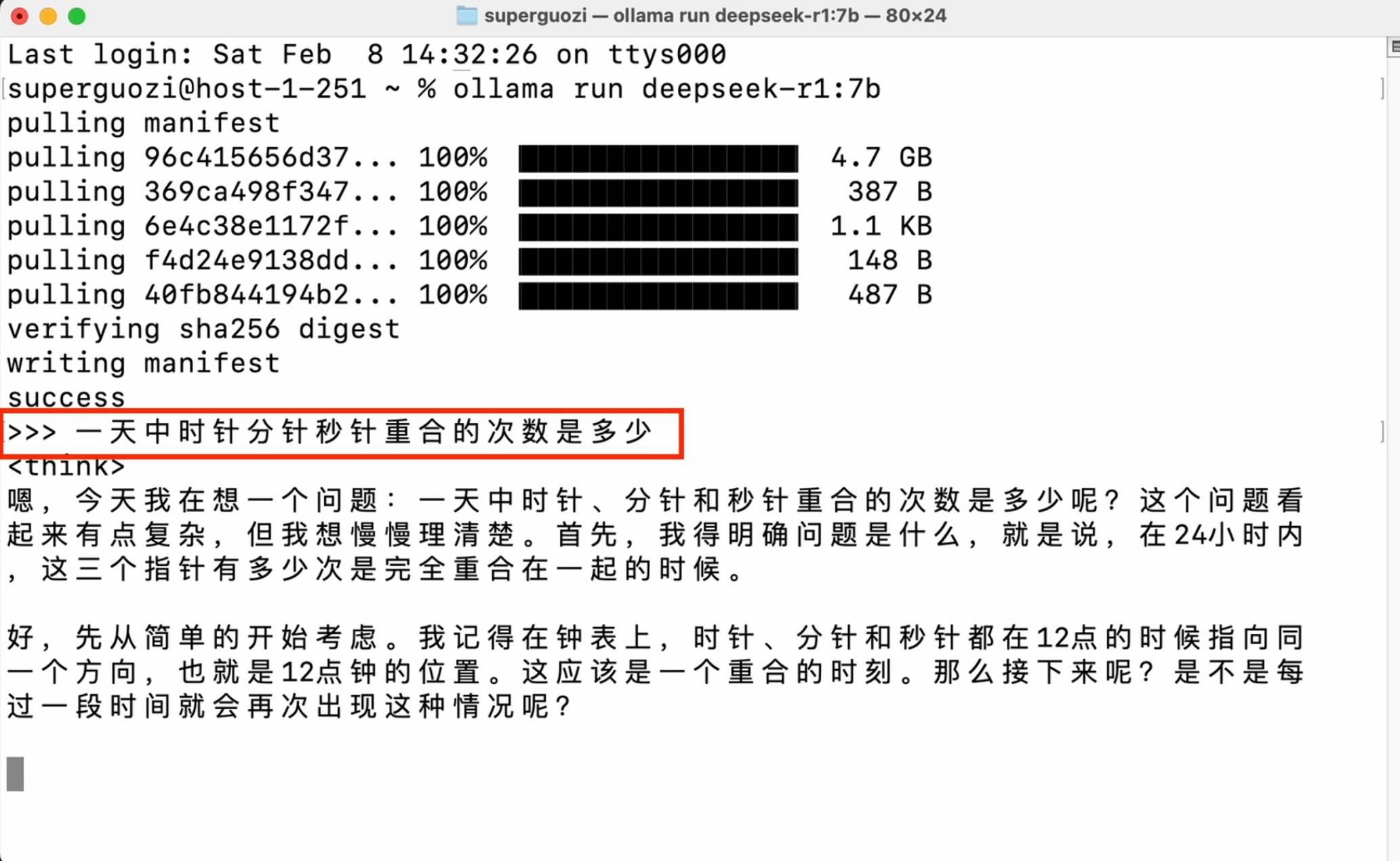
Этот метод имеет очень низкие требования к производительности, но требует знания операций командной строки, а совместимость модели также ограничена. Он больше подходит опытным разработчикам для реализации расширенных операций.
Если вам нужен более красивый интерактивный интерфейс, вы можете также установить плагин в браузере Chrome, найти и установить PageAssist.
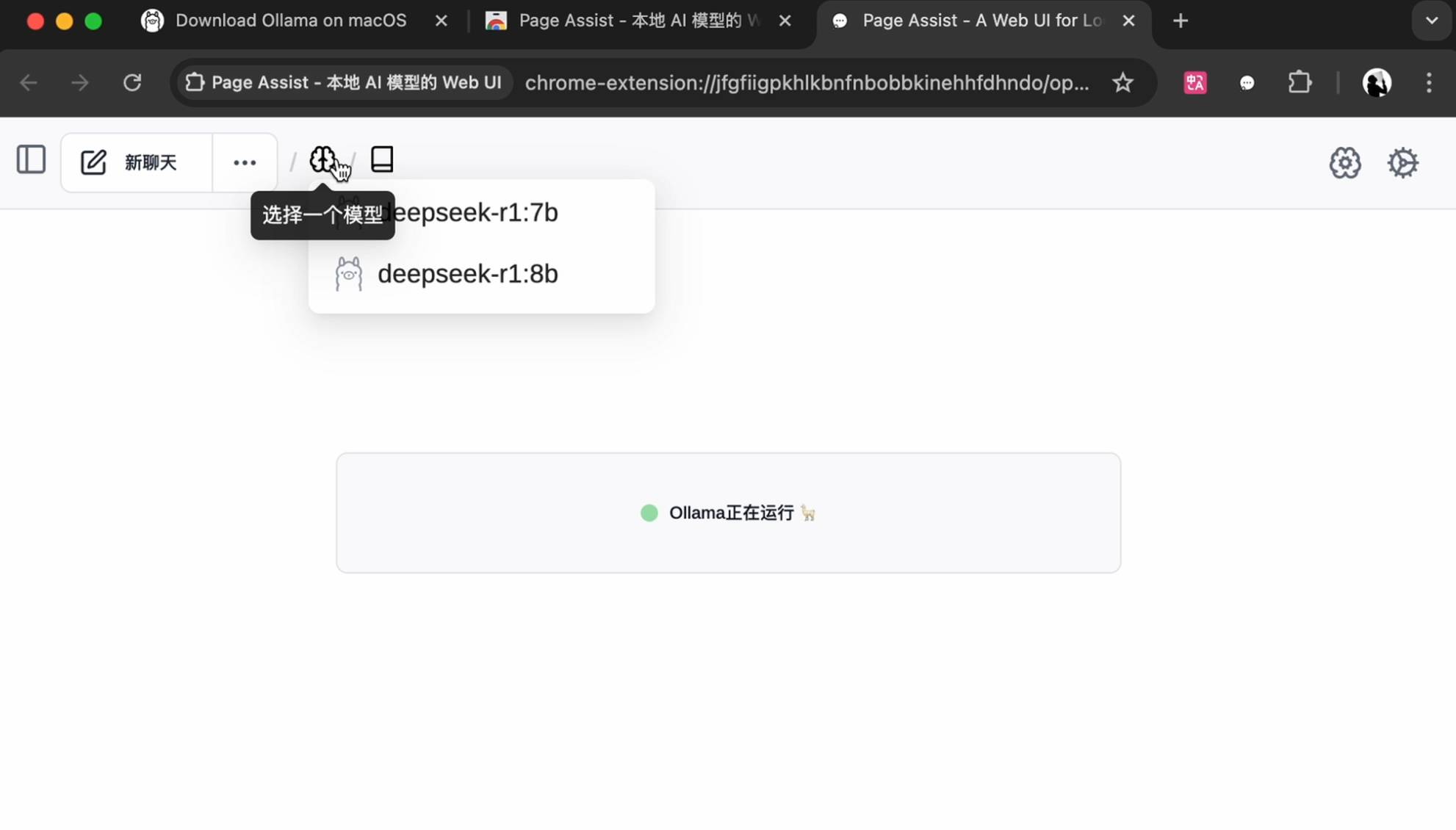
Чтобы начать, выберите локально установленную модель.
Измените язык в настройках в правом верхнем углу, выберите модель на главной странице, чтобы начать разговор, и поддержите базовый поиск в Интернете, и игровой процесс станет более разнообразным.
Если ты можешь бежать, ты можешь бежать, но…
Для этого опыта мы использовали LM Studio.
Благодаря превосходным возможностям оптимизации LM Studio позволяет эффективно работать моделям на оборудовании потребительского уровня. Например, LM Studio поддерживает технологию разгрузки графического процессора, которая позволяет загружать модель в графический процессор блоками для достижения ускорения, когда видеопамять ограничена.
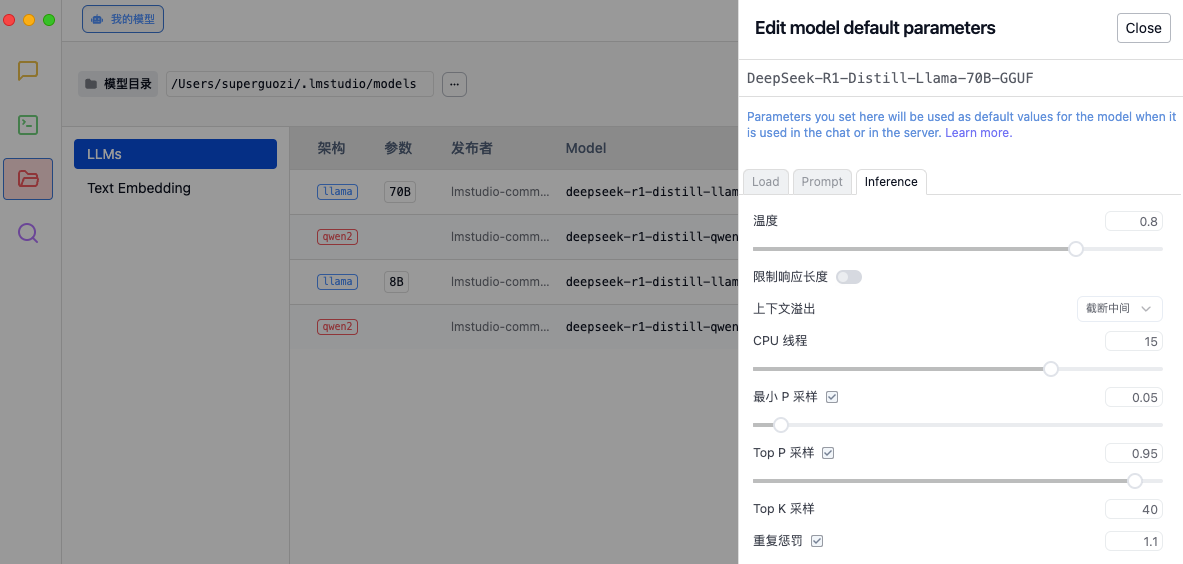
Как и в случае с настройкой гоночного автомобиля, каждый параметр будет влиять на конечную производительность. Прежде чем испытать это, рекомендуется настроить параметры вывода в соответствии с потребностями в настройках LM Studio, чтобы оптимизировать качество генерации модели и распределение вычислительных ресурсов.
- Температура: контролирует случайность генерируемого текста.
- Обработка переполнения контекста: определяет, как обрабатывать слишком длинный ввод.
- Поток ЦП: влияет на скорость генерации и использование ресурсов.
- Стратегия выборки: обеспечьте рациональность и разнообразие сгенерированного текста с помощью нескольких методов выборки и механизмов штрафов.
Исследователь DeepSeek Дая Го поделился своим внутренним руководством по настройке платформы X. Максимальная длина генерации зафиксирована на уровне 32768 токенов, значение температуры поддерживается на уровне 0,6, а значение top-p зафиксировано на уровне 0,95. Каждый тест генерирует 64 образца ответов.
Подробные рекомендации по настройке следующие:
1. Установите температуру в диапазоне 0,5–0,7 (рекомендуемое значение — 0,6), чтобы модель не выдавала бесконечный повторяющийся или бессвязный контент.
2. Избегайте добавления системной подсказки: все инструкции должны быть включены в подсказку пользователя.
3. Для математических вопросов рекомендуется включать в подсказку инструкции, например: «Пожалуйста, рассуждайте поэтапно и поместите окончательный ответ в boxed{}».
4. При оценке эффективности модели рекомендуется провести несколько тестов и усреднить результаты.
5. Кроме того, мы заметили, что модель серии DeepSeek-R1 может обходить режим мышления (т. е. выводить «nn») при ответе на определенные запросы, что может влиять на производительность модели. Чтобы гарантировать, что модель выполняет достаточный вывод, мы рекомендуем заставить модель начинать свой ответ с «n» в начале каждого вывода.
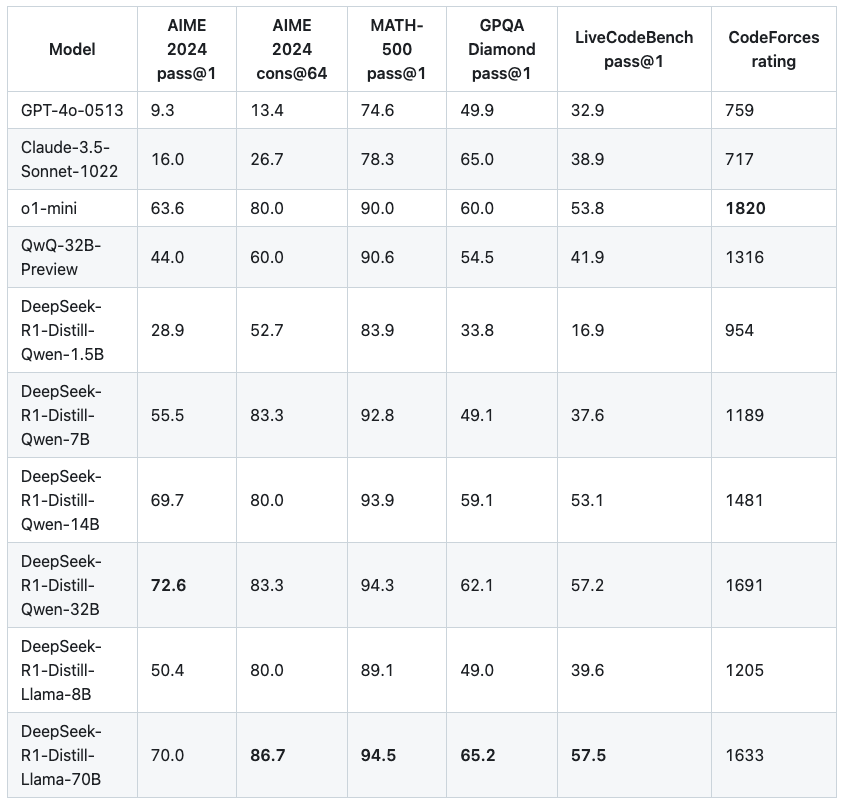
▲Оценка и сравнение модели дистиллированной версии, предоставленной официальным лицом DeepSeek.
Большее количество параметров не обязательно приводит к лучшим результатам. Среди небольших моделей, с которыми мы столкнулись, общий разрыв в прочности между моделями с соседними количествами параметров не является таким иерархическим. Мы также провели несколько простых тестов.
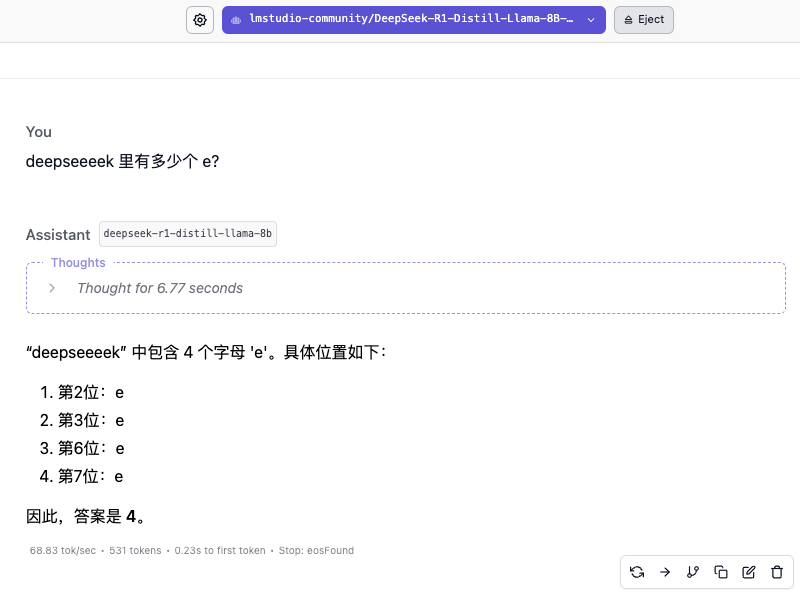

«Сколько е в диксиике?»
Скорость ответа модели 8B очень высокая, в основном достигает 60 токенов/с, но быстрый ответ не означает, что ответ правильный. Небольшая разница может иметь огромное значение. Процесс мышления показывает, что модель больше похожа на ответ на основе слов «DeepSeek» в базе знаний.

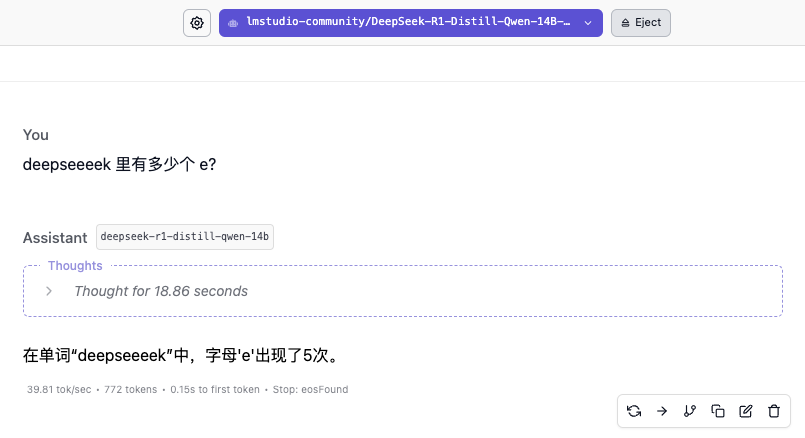
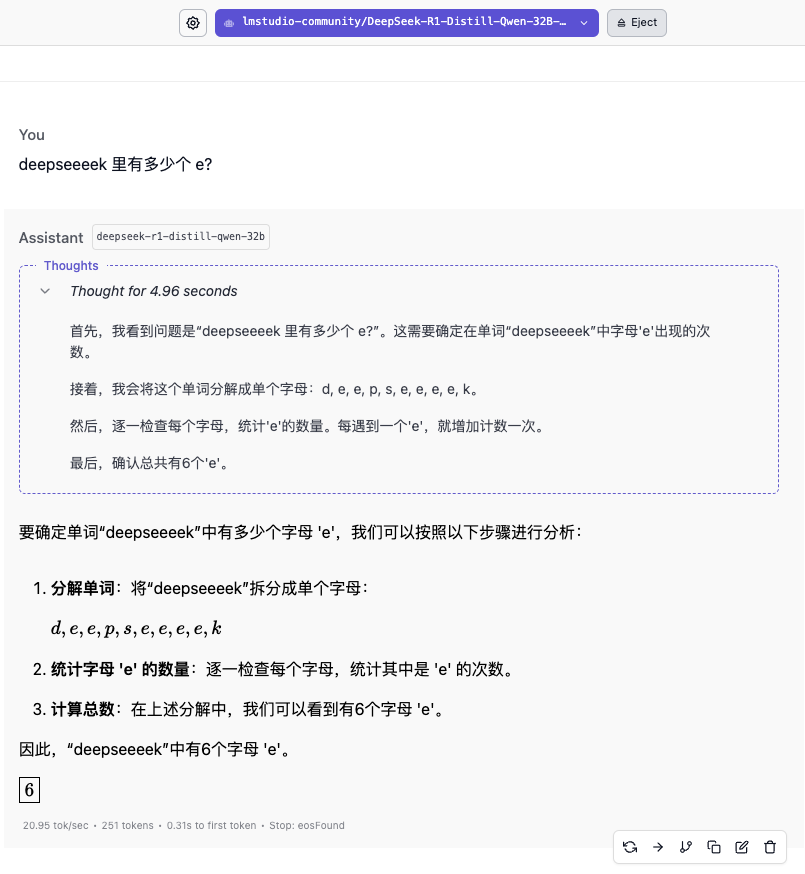
Модель 14B тоже не дала правильного ответа. Только с появлением модели 32B мы наконец увидели надежный ответ. Модель 70B продемонстрировала более осторожные рассуждения, но также дала неправильные ответы.
«Пожалуйста, помогите мне написать версию «Гарри Поттера и философского камня» в пекинской опере».
С точки зрения качества ответов на этот вопрос, 32B и 70B имеют свои преимущества. 32B имеет более совершенный контроль над деталями сцен сценария, тогда как 70B предоставил лист ответов с полными персонажами и законченным сюжетом.

«Кто-то садится на самолет где-то в северном полушарии и пролетает 2000 километров то на восток, то на север, то на запад, то на юг. В конце концов, сможет ли он вернуться в то же место?»
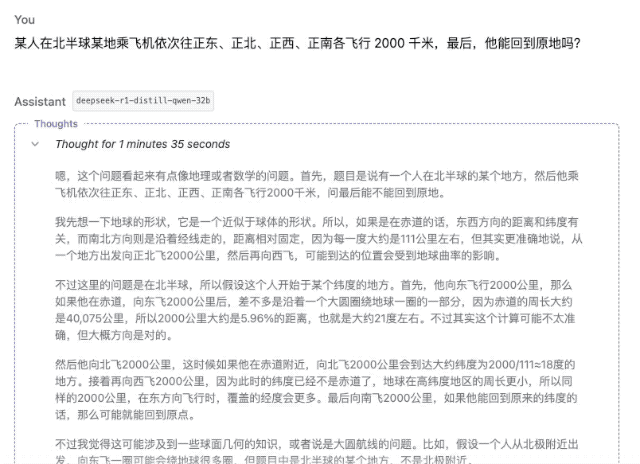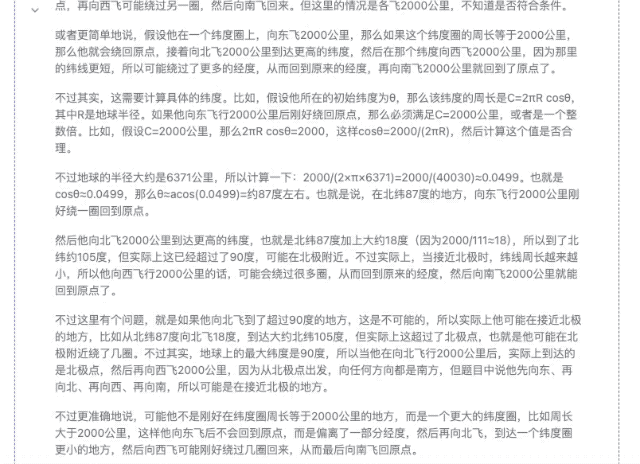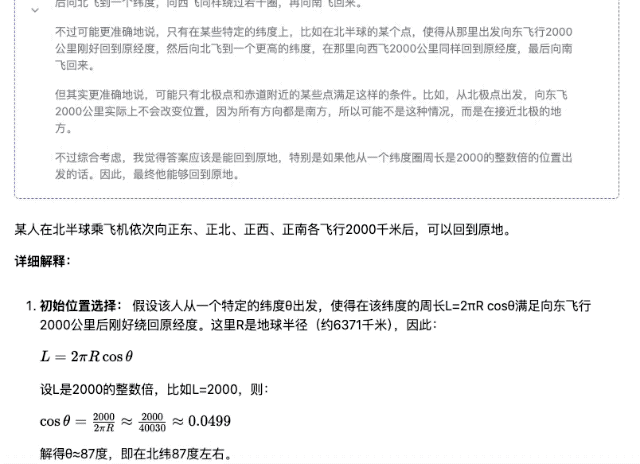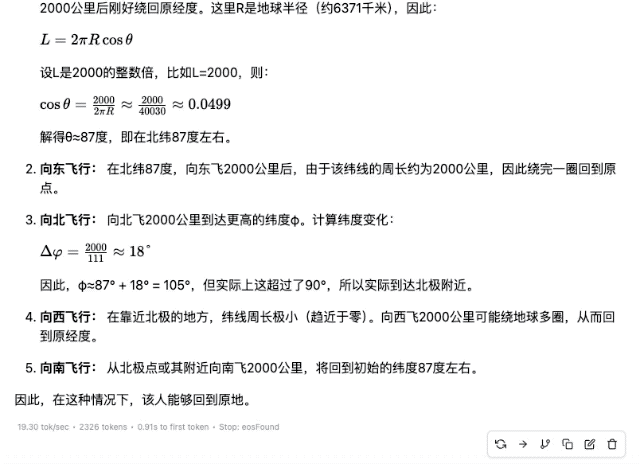
▲ DeepSeek-R1-Distill-Qwen-32B
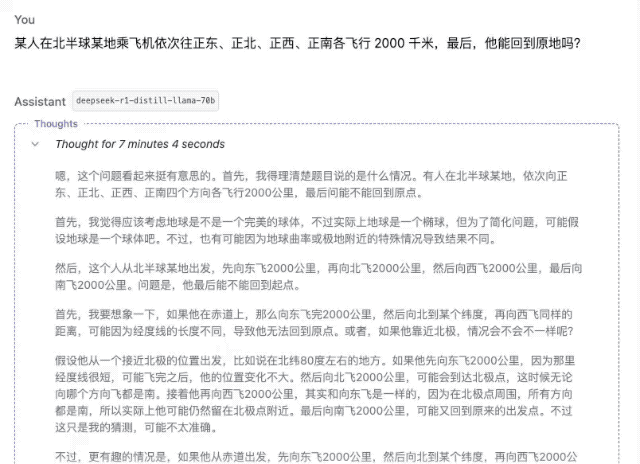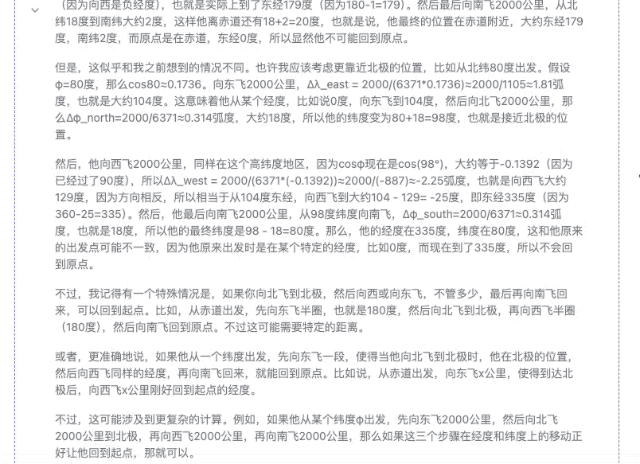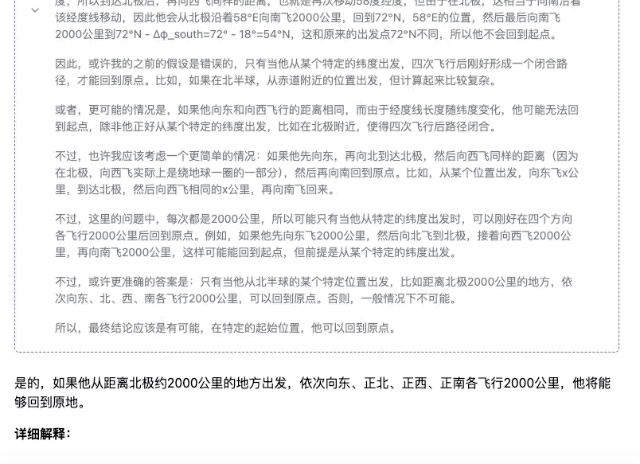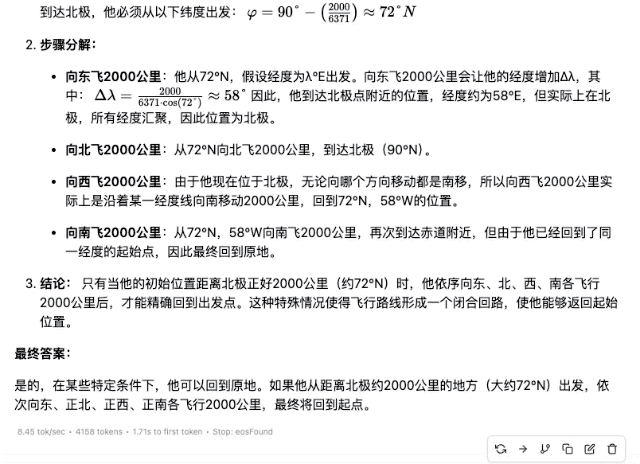
▲DeepSeek-R1-Дистилл-Лама-70B
Конечно, среди этих моделей, чем меньше параметры, тем ниже точность ответа. Даже если процесс мышления будет плавным, последующие ошибки будут допущены из-за недостаточной твердости. В области математических расчетов разница в силе между моделями разной величины будет более очевидной.
Локальное развертывание имеет три основных преимущества: конфиденциальные данные не нужно загружать в облако; их можно беспрепятственно использовать, даже если сеть отключена; плата за вызов API не требуется, что делает выполнение длинных текстовых задач более экономичным. Это особенно подходит для предприятий, разработчиков и пользователей, которые чувствительны к конфиденциальности.
Но отсутствие поддержки Интернета имеет и свои недостатки. Если не снабжать его «информацией» и своевременно не обновлять базу знаний, его уровень информированности также будет стагнировать. Например, если база знаний будет действовать до 2024 года, она не сможет ответить на ваши последние новости об искусственном интеллекте.
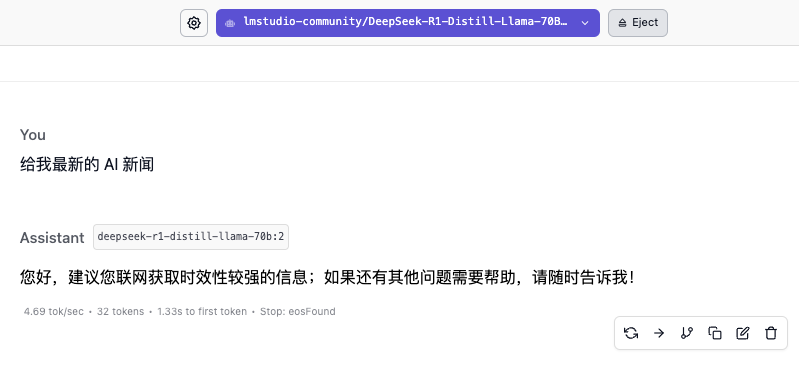
Наиболее часто используемая функция локального развертывания — создание собственной базы знаний. Метод заключается в добавлении этапа развертывания, связанного с Anything LLM, после установки LM Studio.
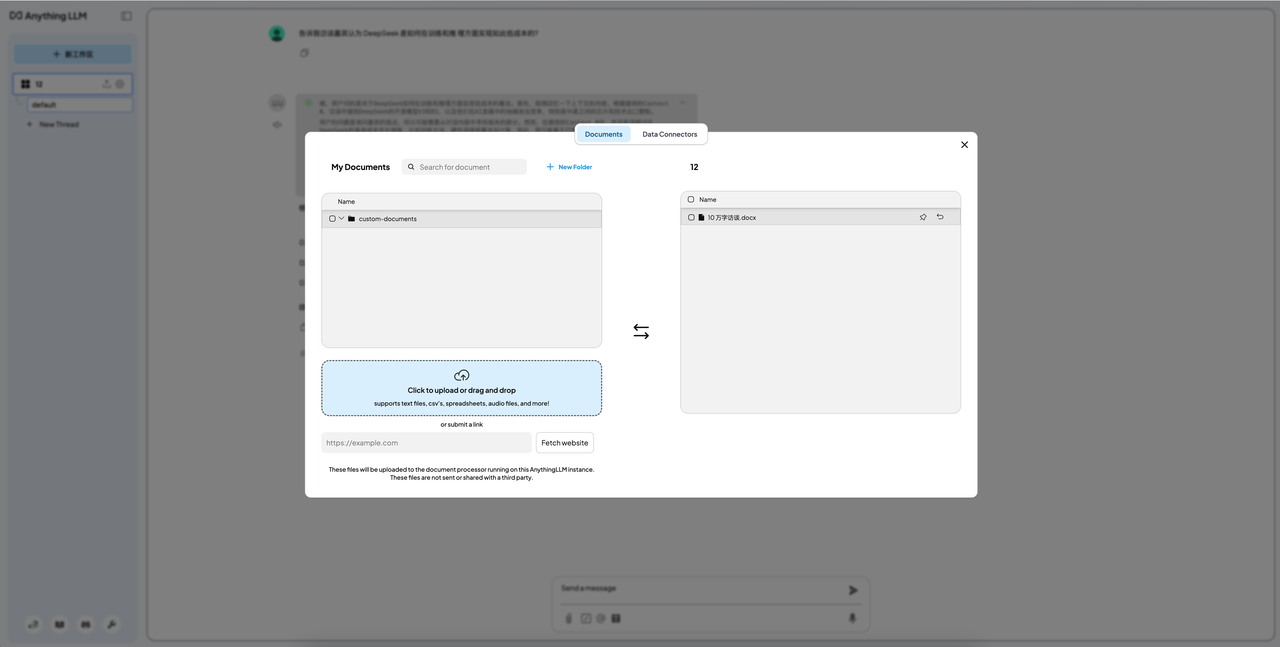
Учитывая эффект и применимость, мы использовали модель 32B в качестве модели связи, и результаты показали, что эффект также был очень общим. Самая большая проблема заключалась в ограничении контекстного окна.
Ввел последовательно статью всего в 4000 слов и статью около 1000 слов. У первого ответ все равно был очень запутанным, а у второго было компетентным. Однако со статьями примерно в 1000 слов было немного бесполезно, так что как игрушка – ладно, а вот продуктивность малоинтересна.

Также следует подчеркнуть, что, с одной стороны, раскрыть рты этих четырех моделей крайне сложно, с другой стороны, мы не рекомендуем вам пытаться «побег из тюрьмы». Хотя существует множество моделей новых версий, которые, как говорят, легко «взломать», мы не рекомендуем случайное развертывание из соображений безопасности и этических соображений.
Однако теперь, когда мы достигли этой точки, мы могли бы также следовать принципу «знать все» и попытаться загрузить и развернуть некоторые небольшие модели, выпущенные по официальным каналам.
Помимо локального развертывания небольших моделей перегонки R1, есть ли убогая комплектация для полнокровной версии R1?
Мэтью Кэрриган, инженер Hugging Face, недавно продемонстрировал аппаратно-программную установку, работающую на полной модели DeepSeek-R1, количественном анализе Q8 и без дистилляции на платформе X, которая стоит примерно 6000 долларов.
Прилагаю ссылку на полную конфигурацию:
https://x.com/carrigmat/status/1884244369907278106
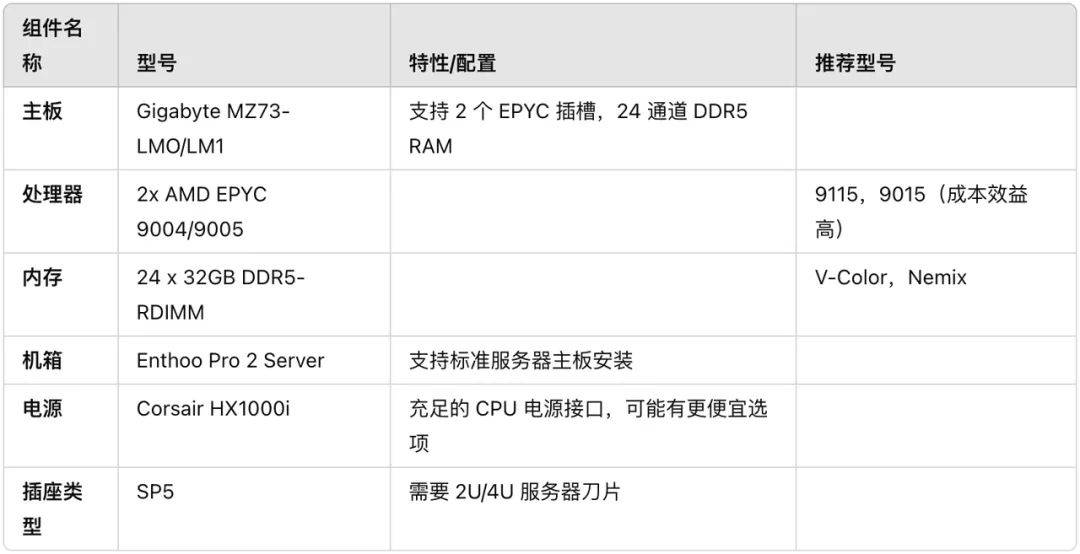
Ближе к дому, так действительно ли нам нужно развертывать очищенную версию DeepSeek R1 локально?
Я предлагаю не думать об этих маленьких моделях R1 как о Теслах. В лучшем случае они больше похожи на Wuling Hongguang. Они могут бегать, но их характеристики сильно отличаются, или у них отсутствуют руки и ноги.
По опыту локального развертывания наиболее часто используемых возможностей пользовательских баз знаний, эффект не является удовлетворительным. Столкнувшись с конкретными проблемами, он не может точно «определить, в чем проблема» или просто придумать ее, и ее точность вызывает беспокойство.
Для подавляющего большинства пользователей лучшим решением является использование официальной версии или сторонней платформы. Это не требует дорогостоящих затрат на оборудование или беспокойства об ограниченной производительности.
Даже после долгой борьбы вы обнаружите, что вместо того, чтобы тратить много времени, энергии и денег на локальное внедрение этих маленьких моделей, лучше хорошо поесть после работы.
Для корпоративных пользователей, разработчиков или пользователей с особыми потребностями в конфиденциальности данных локальное развертывание по-прежнему является вариантом, который стоит рассмотреть, но только если вы понимаете, зачем оно вам нужно и его различные ограничения.
Прикреплены вопросы и ответы Сяобая:
- В: Могу ли я развернуть DeepSeek на обычном компьютере?
Ответ: Полная версия DeepSeek предъявляет более высокие требования к компьютеру. Однако, если вы хотите использовать ее просто для простых операций, вы можете выбрать несколько небольших моделей дистилляции, но вам все равно придется делать все, что в ваших силах. - Вопрос: Что такое дистиллированная версия DeepSeek R1?
Ответ: Упрощенная модель представляет собой «упрощенную» версию с меньшими требованиями к оборудованию и более высокой скоростью работы. - Вопрос: Могу ли я использовать DeepSeek без Интернета?
О: Если вы решите развернуть DeepSeek локально, вы сможете использовать его без Интернета. Если вы используете его через облако или стороннюю платформу, для доступа к нему вам потребуется подключение к Интернету. - Вопрос: Безопасны ли мои личные данные при использовании DeepSeek?
Ответ: Если вы решите развернуть DeepSeek локально, ваши данные не будут загружены в облако, что более безопасно. Если вы используете онлайн-версию, обязательно выберите надежную сервисную платформу для защиты личной жизни.
Автор: Мо Чунюй, Линь
# Добро пожаловать на официальную общедоступную учетную запись WeChat aifaner: aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo