Введение в использование NLTK с Python
Обработка естественного языка – это аспект машинного обучения, который позволяет преобразовывать написанные слова в машинно-понятный язык. Затем такие тексты можно настраивать, и вы можете запускать на них вычислительные алгоритмы по своему усмотрению.
Логика этой увлекательной технологии кажется сложной, но на самом деле это не так. И даже сейчас, хорошо разбираясь в основах программирования на Python, вы можете создать новый текстовый процессор своими руками с помощью набора инструментов естественного языка (NLTK).
Вот как начать работу с Python NLTK.
Что такое НЛТК и как он работает?
Написанный на Python, NLTK имеет множество функций управления строками. Это универсальная библиотека естественного языка с обширным репозиторием моделей для различных приложений на естественном языке.
С помощью NLTK вы можете обрабатывать необработанные тексты и извлекать из них значимые функции. Он также предлагает модели анализа текста, функциональные грамматики и богатые лексические ресурсы для построения полной языковой модели.
Как настроить NLTK
Сначала создайте корневую папку проекта в любом месте вашего ПК. Чтобы начать использовать библиотеку NLTK, откройте свой терминал в корневой папке, которую вы создали ранее, и создайте виртуальную среду .
Затем установите набор инструментов для естественного языка в эту среду с помощью pip :
pip install nltkNLTK, однако, содержит множество наборов данных, которые служат основой для новых моделей естественного языка. Чтобы получить к ним доступ, вам нужно развернуть встроенный загрузчик данных NLTK.
Итак, после успешной установки NLTK откройте файл Python с помощью любого редактора кода.
Затем импортируйте модуль nltk и создайте экземпляр загрузчика данных, используя следующий код:
pip install nltk
nltk.download()Запуск вышеуказанного кода через терминал вызывает графический пользовательский интерфейс для выбора и загрузки пакетов данных. Здесь вам нужно выбрать пакет и нажать кнопку « Загрузить» , чтобы получить его.
Любой загружаемый вами пакет данных попадает в указанный каталог, указанный в поле Download Directory . Вы можете изменить это, если хотите. Но постарайтесь сохранить местоположение по умолчанию на этом уровне.
Примечание. Пакеты данных по умолчанию добавляются к системным переменным. Таким образом, вы можете продолжать использовать их для последующих проектов независимо от того, какую среду Python вы используете.
Как использовать токенизаторы NLTK
В конечном итоге NLTK предлагает обученные модели токенизации для слов и предложений. Используя эти инструменты, вы можете создать список слов из предложения. Или превратите абзац в разумный массив предложений.
Вот пример использования NLTK word_tokenizer :
import nltk
from nltk.tokenize import word_tokenize
word = "This is an example text"
tokenWord = word_tokenizer(word)
print(tokenWord)
Output:
['This', 'is', 'an', 'example', 'text']NLTK также использует предварительно обученный токенизатор предложений под названием PunktSentenceTokenizer . Он работает, разбивая абзац на список предложений.
Давайте посмотрим, как это работает с абзацем из двух предложений:
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
sentence = "This is an example text. This is a tutorial for NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(sentence)
print(tokenized_sentence)
Output:
['This is an example text.', 'This is a tutorial for NLTK']
Вы можете дополнительно токенизировать каждое предложение в массиве, сгенерированном из приведенного выше кода, с помощью word_tokenizer и Python for loop .
Примеры использования NLTK
Итак, хотя мы не можем продемонстрировать все возможные варианты использования NLTK, вот несколько примеров того, как вы можете начать использовать его для решения реальных проблем.
Получите определения слов и их части речи
В NLTK есть модели для определения частей речи, получения подробной семантики и возможного контекстного использования различных слов.
Вы можете использовать модель wordnet для генерации переменных для текста. Затем определите его значение и часть речи.
Например, давайте проверим возможные переменные для "Monkey:"
import nltk
from nltk.corpus import wordnet as wn
print(wn.synsets('monkey'))
Output:
[Synset('monkey.n.01'), Synset('imp.n.02'), Synset('tamper.v.01'), Synset('putter.v.02')]
Приведенный выше код выводит возможные варианты слов или синтаксис и части речи для "Monkey".
Теперь проверьте значение слова «Обезьяна», используя метод определения :
Monkey = wn.synset('monkey.n.01').definition()
Output:
any of various long-tailed primates (excluding the prosimians)Вы можете заменить строку в скобках другими сгенерированными альтернативами, чтобы увидеть, что выводит NLTK.
Модель pos_tag , однако, определяет части речи слова. Вы можете использовать это с word_tokenizer или PunktSentenceTokenizer (), если имеете дело с более длинными абзацами.
Вот как это работает:
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
word = "This is an example text. This is a tutorial on NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(word)
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i)
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN'), ('.', '.')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]Приведенный выше код объединяет каждое токенизированное слово с его речевым тегом в кортеж. Вы можете проверить значение этих тегов на Penn Treebank .
Для более чистого результата вы можете удалить точки в выводе с помощью метода replace () :
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i.replace('.', ''))
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Cleaner output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]Визуализация тенденций в функциях с использованием графика NLTK
Извлечение функций из необработанных текстов часто утомительно и требует много времени. Но вы можете просмотреть наиболее сильные детерминаторы признаков в тексте, используя график тренда частотного распределения NLTK.
Однако NLTK синхронизируется с matplotlib. Вы можете использовать это для просмотра определенной тенденции в ваших данных.
Например, приведенный ниже код сравнивает набор положительных и отрицательных слов на графике распределения, используя их последние два алфавита:
import nltk
from nltk import ConditionalFreqDist
Lists of negative and positive words:
negatives = [
'abnormal', 'abolish', 'abominable',
'abominably', 'abominate','abomination'
]
positives = [
'abound', 'abounds', 'abundance',
'abundant', 'accessable', 'accessible'
]
# Divide the items in each array into labeled tupple pairs
# and combine both arrays:
pos_negData = ([("negative", neg) for neg in negatives]+[("positive", pos) for pos in positives])
# Extract the last two alphabets from from the resulting array:
f = ((pos, i[-2:],) for (pos, i) in pos_negData)
# Create a distribution plot of these alphabets
cfd = ConditionalFreqDist(f)
cfd.plot()График распределения алфавита выглядит так:
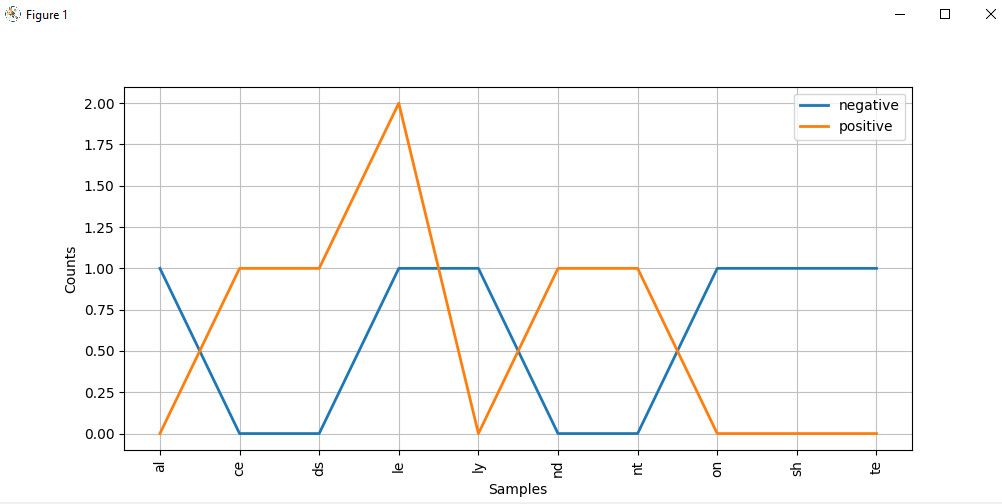
Если внимательно присмотреться к графику, то слова, оканчивающиеся на ce , ds , le , nd и nt , с большей вероятностью могут быть положительными текстами. Но слова, оканчивающиеся на al , ly , on и te , скорее всего, негативные.
Примечание : Хотя мы использовали самообразующиеся данные здесь, вы можете получить доступ к встроенному в наборах данных с использованием своего читателя Corpus, называя их из класса мозолистого из NLTK NLTK годов. Возможно, вы захотите посмотреть документацию по корпусу пакета, чтобы узнать, как вы можете его использовать.
Продолжайте изучать инструментарий обработки естественного языка
С появлением таких технологий, как Alexa, обнаружение спама, чат-боты, анализ настроений и т. Д., Обработка естественного языка, похоже, переходит в неочеловеческую фазу. Хотя в этой статье мы рассмотрели только несколько примеров того, что предлагает NLTK, у этого инструмента есть более сложные приложения, которые выходят за рамки этого руководства.
Прочитав эту статью, вы должны иметь хорошее представление о том, как использовать NLTK на базовом уровне. Все, что вам осталось сделать, это самому применить эти знания на практике!