Догоняя GPT-4o, самая мощная модель Llama 3.1 405B в одночасье стала богом, Цукерберг: открытый исходный код ведет новую эру
Только сейчас Meta выпустила модель Llama 3.1, как и планировалось.
Проще говоря, недавно выпущенная Llama 3.1 405B — это самая мощная модель Meta на сегодняшний день. Это также самая мощная большая модель с открытым исходным кодом в мире, а также самая мощная большая модель в мире.
С сегодняшнего дня нет необходимости спорить о достоинствах больших моделей с открытым исходным кодом и больших моделей с закрытым исходным кодом, потому что Llama 3.1 405B с неопровержимой силой доказывает, что борьба за маршруты не влияет на конечную техническую мощь.
Сначала подведу итог характеристик модели Llama 3.1:
- Содержит три размера: 8 байт, 70 байт и 405 байт, максимальный контекст увеличен до 128 КБ, поддерживает несколько языков, имеет отличную производительность генерации кода, а также обладает сложными возможностями рассуждения и навыками использования инструментов.
- Судя по результатам бенчмарк-тестов, Llama 3.1 превзошла GPT-4 0125, конкурируя с GPT-4o и Claude 3.5.
- Предоставляя открытые/бесплатные веса и код модели, лицензия позволяет пользователям точно настраивать, превращать модель в другие формы и поддерживать развертывание где угодно.
- Предоставляет API-интерфейс Llama Stack для облегчения интегрированного использования и поддерживает координацию нескольких компонентов, включая вызов внешних инструментов.
Прилагаю адрес загрузки модели:
https://huggingface.co/meta-llama
https://llama.meta.com/

Сверхбольшая чашка достигает вершины самой мощной модели в мире, а чашки среднего и большого размера таят в себе сюрпризы.
Выпущенная на этот раз модель Llama 3.1 доступна в трёх размерах: 8B, 70B и 405B.
Судя по результатам тестов, сверхбольшой Llama 3.1 405B может выдерживать все нагрузки GPT-3.5 Turbo, а результаты большинства тестов превосходят GPT-4 0125.
Перед лицом самой мощной большой модели GPT-4o с закрытым исходным кодом, ранее выпущенной OpenAI, и Claude 3.5 Sonnet первого уровня, Super Cup все еще может бороться. Даже исходя из бумажных параметров, можно сказать, что Llama 3.1. 405B отмечает открытый исходный код. Впервые большие модели догнали большие модели с закрытым исходным кодом.
Говоря конкретно о результатах тестов, Llama 3.1 405B набрал 98,1 балла в тесте NIH/Multi-needle. Хотя он не так хорош, как GPT-4o, он также показывает, что его способность обрабатывать сложную информацию идеальна.
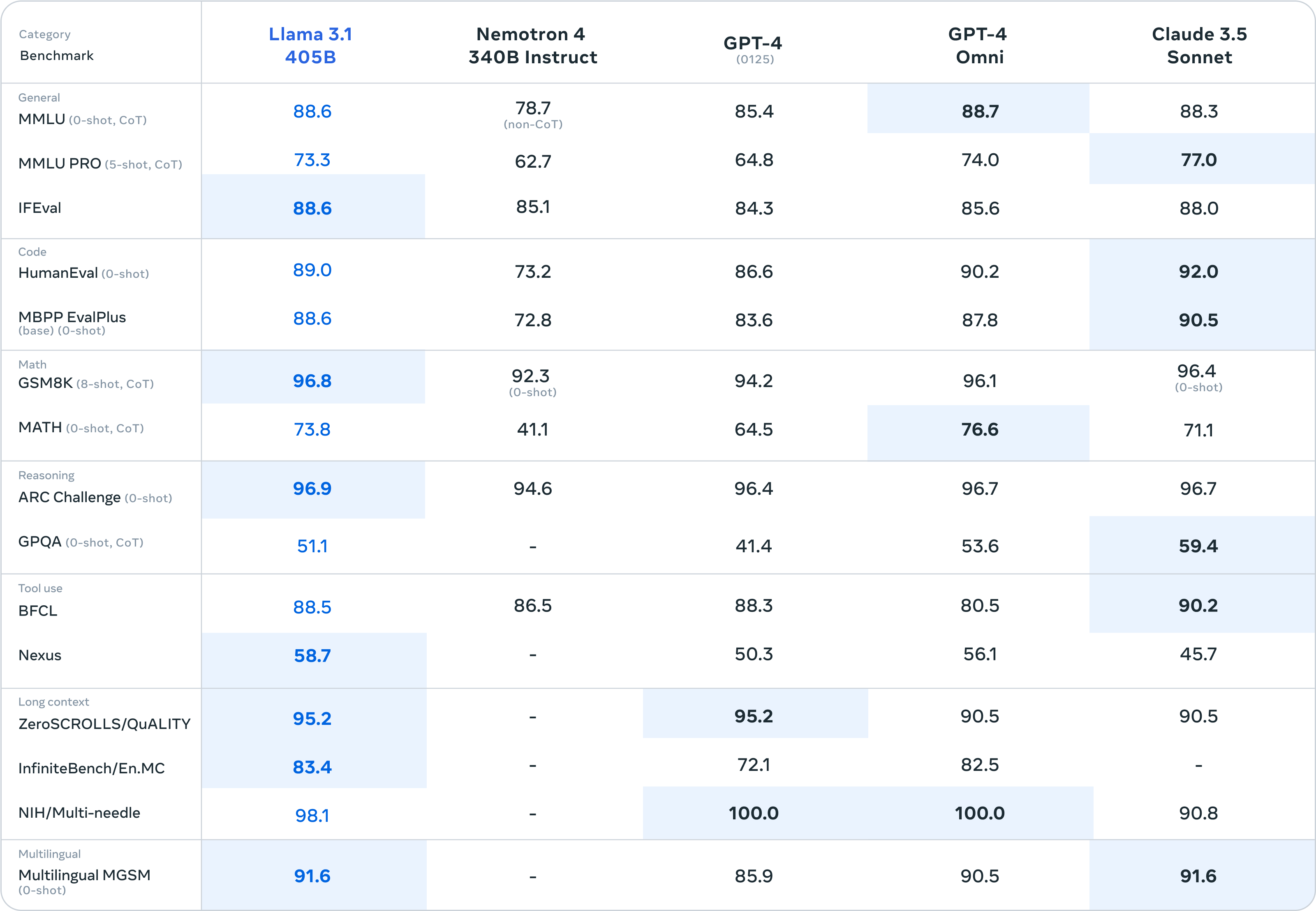
А Llama 3.1 405B набрала 95,2 балла по тесту ZeroSCROLLS/QUALITY, что также означает, что она обладает высокой способностью интегрировать большие объемы текстовой информации. Эти результаты показывают, что модель LLaMA3.1 405B превосходно обрабатывает длинные тексты и подходит для обработки длинных текстов. Сосредоточение внимания на LLM в RAG. Для разработчиков приложений искусственного интеллекта производительность весьма удобна.
Особое беспокойство вызывает то, что Human-Eval в основном отвечает за тестирование способности модели понимать и генерировать код, а также решать абстрактную логику, а Llama 3.1 405B также имеет небольшое преимущество в конкуренции с другими большими моделями.
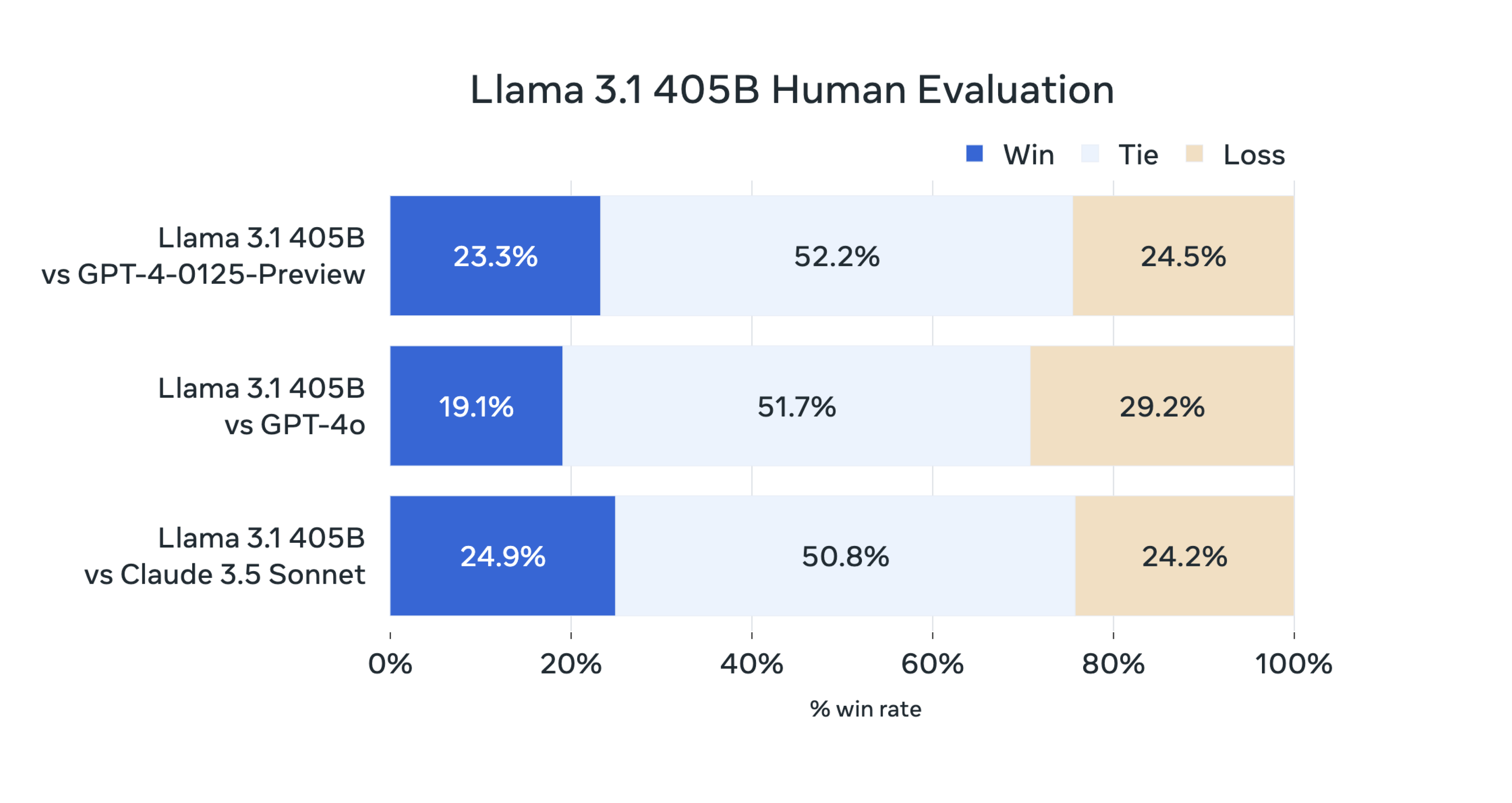
В дополнение к основному блюду «Лама 3.1 405B» гарниры «Лама 3.1 8В» и «Лама 3.1 70В» также демонстрируют «маленькие победы над большими».
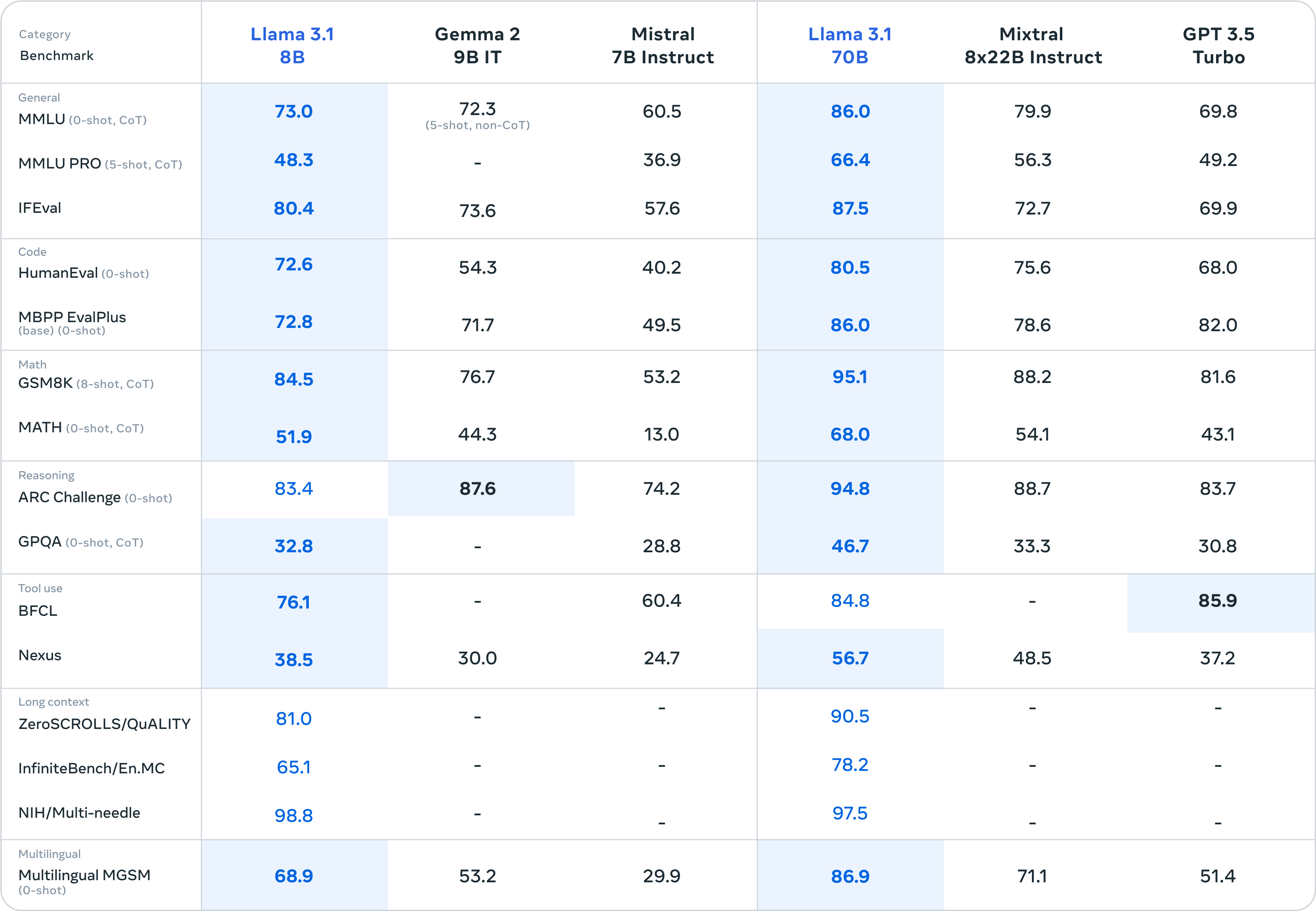
Судя по результатам бенчмарк-тестов, Llama 3.1 8B практически разгромила Gemma 2 9B 1T и Mistral 7B Instruct. Общая производительность даже значительно улучшилась, чем у Llama 3 8B. Llama 3.1 70B может даже превзойти GPT-3.5 Turbo и модель Mixtral 8x7B с отличными характеристиками.
Согласно официальному сообщению, в этом выпуске исследовательская группа Llama оценила производительность модели на более чем 150 наборах контрольных данных, охватывающих несколько языков, а также провела большое количество ручных оценок.
Окончательный вывод таков:
Наша флагманская модель конкурирует с лучшими базовыми моделями, такими как GPT-4, GPT-4o и Claude 3.5 Sonnet, при выполнении множества задач. В то же время наша маленькая модель также показывает конкурентоспособность по сравнению с закрытыми и открытыми моделями с аналогичным количеством параметров.
Как сделана Лама 3.1 405Б
Так как же обучается Llama 3.1 405B?
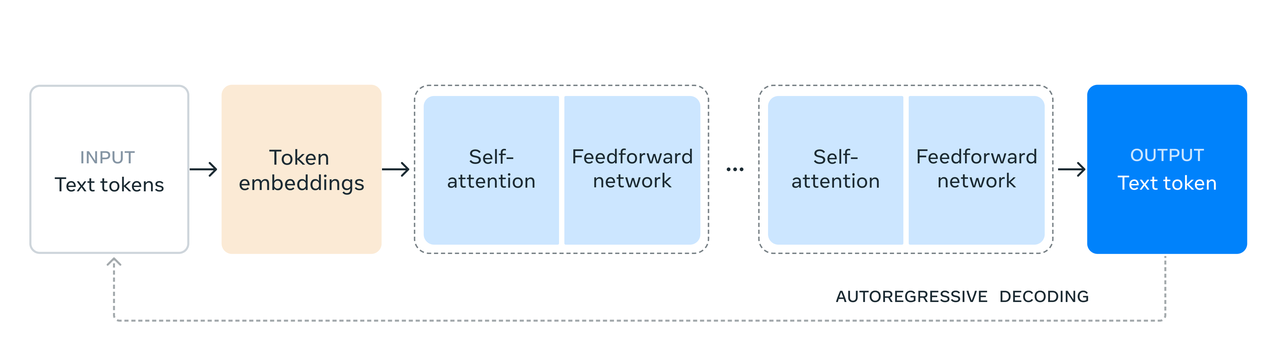
Согласно официальному блогу, Llama 3.1 405B, являющаяся крупнейшей моделью Meta на сегодняшний день, использует для обучения более 15 триллионов токенов.
Чтобы добиться обучения такого масштаба и достичь ожидаемых результатов за короткое время, исследовательская группа также оптимизировала весь стек обучения и обучила более чем 16 000 графических процессоров H100. Это также первая модель Llama, обученная в таком большом масштабе. .
Команда также внесла некоторые оптимизации в процесс обучения, сосредоточив внимание на том, чтобы процесс разработки модели был масштабируемым и простым:
- Вместо гибридной экспертной модели была выбрана стандартная архитектура модели Трансформатора декодера с незначительными изменениями, чтобы максимизировать стабильность обучения.
- Используется итеративная процедура постобучения, использующая контролируемую точную настройку и прямую оптимизацию предпочтений на каждом этапе. Это позволяет исследовательской группе создавать синтетические данные высочайшего качества для каждого раунда и улучшать производительность каждой функции.
- По сравнению со старой версией модели Ламы исследовательская группа улучшила количество и качество данных, используемых для предварительного и постобучения, в том числе разработала более широкий конвейер предварительной обработки и управления данными предварительного обучения, а также разработала дополнительные строгие методы обеспечения качества и фильтрации данных после обучения.
Представители Meta заявили, что под влиянием Закона о масштабировании новая флагманская модель превзошла по производительности меньшие модели, обученные с использованием того же метода.
Исследовательская группа также использовала модель параметров 405B для улучшения качества небольших моделей после обучения.
Чтобы поддержать массовое производство моделей масштаба 405B, исследовательская группа квантовала модель с 16-битной (BF16) точности до 8-битной (FP8). Это эффективно сократило необходимые вычислительные ресурсы и позволило запустить модель. на одном серверном узле.
Есть также некоторые детали, которые стоит изучить в Llama 3.1 405B, например, ее конструкция, ориентированная на практичность и безопасность, позволяющая лучше понимать и выполнять инструкции пользователя.
С помощью таких методов, как контролируемая точная настройка, выборка отклонения и прямая оптимизация предпочтений, на основе предварительно обученной модели выполняются несколько этапов согласования для построения модели чата. Llama 3.1 405B также может более точно адаптироваться к конкретным сценариям использования. и потребности пользователей, улучшая производительность реальных приложений.
Стоит отметить, что исследовательская группа Llama использует генерацию синтетических данных для создания подавляющего большинства примеров SFT, а это означает, что они полагаются не на реальные данные, а на алгоритмически сгенерированные данные для обучения модели.
Кроме того, исследовательская группа продолжает улучшать качество синтезированных данных посредством многочисленных итеративных процессов. Чтобы обеспечить высокое качество синтетических данных, исследовательская группа использовала различные методы обработки данных для фильтрации и оптимизации данных.
Благодаря этим методам команда может масштабировать объем данных для точной настройки так, чтобы их можно было не только применять к одной функции, но и использовать в нескольких функциях, повышая применимость и гибкость модели.
Проще говоря, применение этой технологии генерации и обработки синтетических данных заключается в создании большого количества высококачественных обучающих данных, что помогает улучшить способность к обобщению и точность модели.
Будучи сторонником модели с открытым исходным кодом, Meta также продемонстрировала искренность в отношении «вспомогательных средств» модели Llama.
- Являясь частью системы искусственного интеллекта, модель Llama поддерживает координацию нескольких компонентов, включая вызов внешних инструментов.
- Публикуйте справочные системы и примеры приложений с открытым исходным кодом, поощряйте участие и сотрудничество сообщества, а также определяйте интерфейсы компонентов.
- Обеспечьте совместимость компонентов цепочки инструментов и приложений-агентов через стандартизированный интерфейс «Llama Stack».
- После выпуска модели для разработчиков открываются все расширенные функции, включая расширенные рабочие процессы, такие как генерация синтетических данных.
- Llama 3.1 405B поставляется с подарочным набором встроенных инструментов, включая ключевые проекты, упрощающие процесс от разработки до развертывания.
Стоит отметить, что в новом соглашении об открытом исходном коде Meta больше не запрещает использовать Llama 3 для улучшения других моделей, включая самую сильную Llama 3.1 405B, настоящего доброго человека с открытым исходным кодом.
Прилагается адрес 92-страничного отчета о дипломной подготовке:
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
Новая эра во главе с открытым исходным кодом
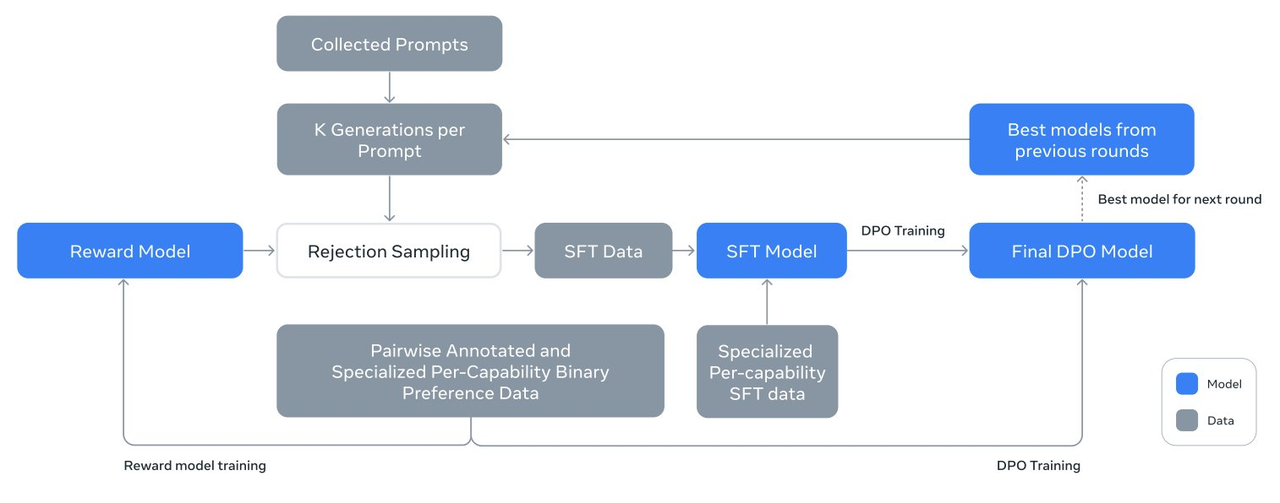
Пользователь сети @ZHOZHO672070 также быстро протестировал ответы Llama 3.1 405B Instruct FP8 на два классических вопроса в Hugging Chat.
К сожалению, Llama 3.1 405B столкнулась с переворотом в решении задачи «кто больше, 9,11 или 9,9», но после повторной попытки дала правильный ответ. Что касается аннотации пиньинь «Я поймал это», ее производительность также приемлема.
Пользователи сети использовали модель Llama 3.1, чтобы быстро создать и развернуть чат-бота менее чем за 10 минут.
Кроме того, внутренний научный сотрудник Llama @astonzhangAZ также сообщил на X, что его исследовательская группа в настоящее время рассматривает возможность интеграции функций изображения, видео и голоса в Llama 3.
Споры между открытым исходным кодом и закрытым исходным кодом продолжаются и в эпоху больших моделей, но сегодняшний выпуск новой модели Meta Llama 3.1 положил конец этим спорам.
Meta официально заявила: «До сих пор крупномасштабные языковые модели с открытым исходным кодом в основном отставали от закрытых моделей с точки зрения функциональности и производительности. Теперь мы вступаем в новую эру, возглавляемую открытым исходным кодом».
Рождение Meta Llama 3.1 405B доказывает одно. Способность модели заключается не в открытии или закрытии, а в вложении ресурсов, людей и команд, стоящих за ней, и т. д. Мета может выбрать открытый исходный код из-за многих факторов. но всегда найдутся люди, несущие этот флаг.
Будучи первым гигантом, воспользовавшимся ситуацией, Meta также получила титул первой SOTA, превзошедшей самую сильную большую модель с закрытым исходным кодом.

Генеральный директор Meta Цукерберг написал в опубликованной сегодня длинной статье «ИИ с открытым исходным кодом — путь вперед»:
«Начиная со следующего года мы ожидаем, что будущая Llama станет самой передовой в отрасли. Но до этого Llama уже лидирует в области открытого исходного кода, возможности модификации и экономической эффективности».
Модели ИИ с открытым исходным кодом не могут превзойти закрытый исходный код или из-за технического равенства, чтобы они не стали средством получения прибыли для нескольких людей, или из-за надежды на то, что каждый подольет топливо к процветанию ИИ. экосистема.
Вот как Цукерберг описал свое видение в конце своего длинного поста:
Я считаю, что версия Llama 3.1 станет поворотным моментом в отрасли, и большинство разработчиков начнут переходить в основном на использование технологий с открытым исходным кодом. Я с нетерпением жду продолжения этой тенденции… Вместе мы стремимся использовать преимущества ИИ. всем во всем мире.
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo