Заявляя, что китайская оценка превосходит GPT-4, Baichuan Intelligent выпускает Baichuan 3, большую модель с более чем 100 миллиардами параметров.
Стартапы крупных моделей, базирующиеся в Цинхуа, снова набирают сотрудников.
29 января компания Baichuan Intelligence, основанная основателем Sogou Ван Сяочуанем (бакалавр Университета Цинхуа), официально выпустила Baichuan 3, большую языковую модель с более чем 100 миллиардами параметров. Эта модель не только хорошо показывает себя во множестве авторитетных тестов, но и превосходит GPT-4 по китайским показателям.
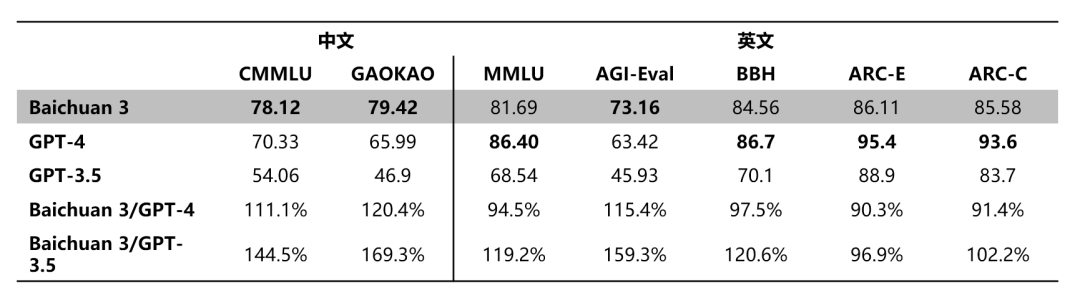
Результаты испытаний показывают, что Baichuan 3 достигает уровня, близкого к 90% GPT-4, в нескольких английских тестах, таких как MMLU. Во многих китайских тестах производительности, таких как CMMLU и GAOKAO, Baichuan 3 находится далеко впереди, с большим отрывом превосходя GPT-3.5, а также превосходя GPT-4 во всех аспектах.
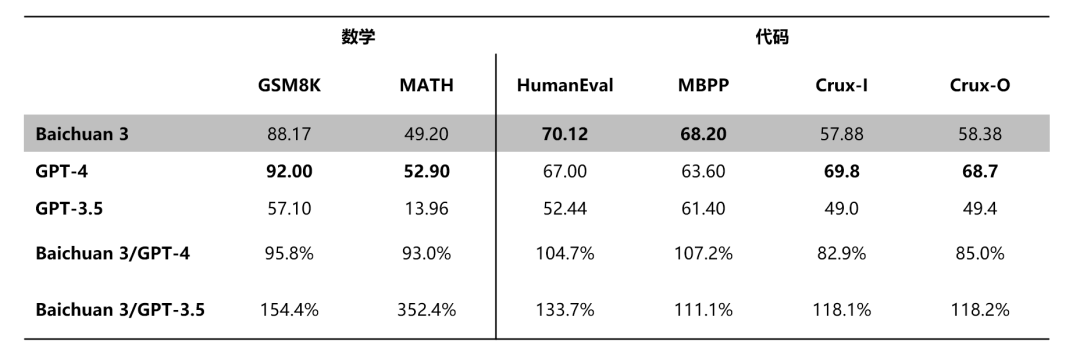
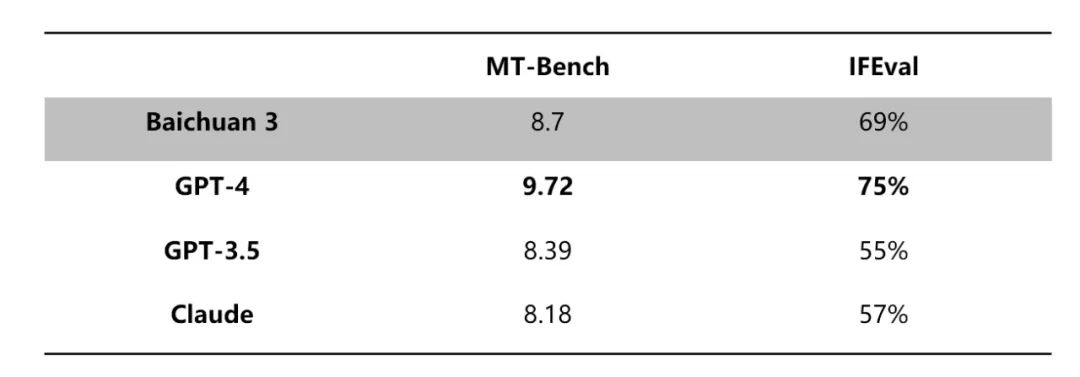
В тестах по математике и спискам кодов, а также при оценке согласованных списков, таких как MT-Bench и IFEval, Baichuan 3 превзошел крупные модели, такие как GPT-3.5 и Claude, а также находится в авангарде отрасли, лишь незначительно уступает ГПТ-4.
ИИ+медицина — ключевая область применения больших моделей. Медицинские проблемы сложны и изменчивы, знания быстро обновляются, а требования к точности высоки, что требует от моделей полной демонстрации мощных возможностей понимания и принятия решений в тексте, изображениях, звуках и т. д.
Поэтому Baichuan Intelligence считает его «жемчужиной» среди крупных моделей.
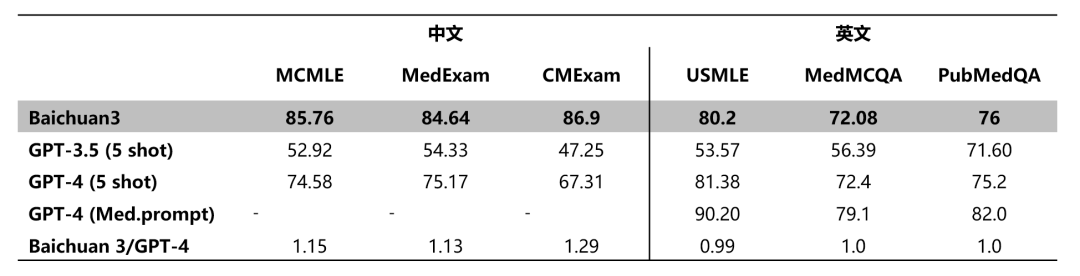
Baichuan 3 прошел обширное обучение и оптимизацию в области медицины, и результаты после обучения также очень значительны. Его производительность в китайских медицинских задачах, таких как MCMLE, MedExam и CMExam, превосходит производительность GPT-4, а его производительность в английских медицинских задачах такие задачи, как USMLE и MedMCQA, также близки к уровню GPT-4, одним махом завоевав титул китайской модели с самыми сильными медицинскими возможностями.
Согласно официальным сообщениям, чтобы усилить обучение в этой области, Baichuan 3 на этапе предварительного обучения модели создал набор медицинских данных из более чем 100 миллиардов токенов, охватывающий все аспекты медицинских знаний от теории до практики, чтобы обеспечить профессионализм и профессионализм. в медицинской сфере.Глубина знаний.
На этапе вывода Baichuan Intelligence оптимизирует подсказки для медицинских знаний, точно описывая задачи и соответствующим образом отбирая образцы, что делает выходные данные модели более точными и логичными.
Семантическое понимание и генерация текста являются основными базовыми возможностями больших моделей и могут рассматриваться как основные основы моделей искусственного интеллекта. Ван Сяочуань однажды заметил, что язык является границей человеческого когнитивного мира.С технической точки зрения воспринимать и понимать язык сложнее, чем изображения и видео.

По его мнению, Ньютон использовал три закона движения, чтобы абстрагировать законы Вселенной в математические выражения, что было большим шагом вперед для человеческого познания. То же самое касается сегодняшних более крупных моделей. Овладение законами языка означает овладение самими знаниями, а также человеческим мышлением, общением и культурой.
Языковая модель подобна атомной бомбе: она может взорвать водородную бомбу. В будущем моделирование будет лучше, и это то, что нам нужно делать в будущем.
Мощные возможности обработки китайского языка в Baichuan 3 — одна из его главных особенностей. Даже сталкиваясь со сложными жанрами, такими как тексты песен со сложным форматом, жесткой структурой и богатыми рифмами, Baichuan 3 может создавать произведения с аккуратным содержанием, хорошо согласованными контрапунктами и гармоничными рифмами.
Официальные лица заявили, что Baichuan 3 сочетает в себе «RLHF&RLAIF» и методы итеративного обучения с подкреплением, чтобы значительно улучшить возможности больших языковых моделей при создании стихов. По сравнению с другими ведущими моделями в отрасли удобство использования его создания увеличено более чем в 5 раз, а его литературные достижения полностью превосходят GPT-4.
▲Ссылка на опыт: https://www.baichuan-ai.com/
Например, во время официальной демонстрации Baichuan 3 попросили создать сенсационную песню о «Gongdou Drama» OpenAI. Ее исполнение на смешанном китайском и английском языках весьма интересно. 
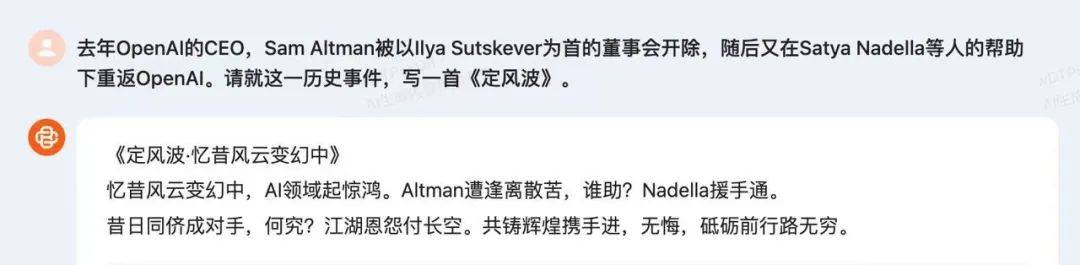
«Защищая бурю · Вспоминая прошлое и меняющуюся бурю»
Оглядываясь назад, можно сказать, что среди перемен можно сказать, что сфера искусственного интеллекта переживает бум. Альтман страдает от разлуки, кто может помочь?Наделла помогает.
Что плохого в том, что бывшие сверстники становятся соперниками? Обиды и обиды мира в небе. Давайте вместе творить великолепие и двигаться вперед рука об руку, без сожалений, и путь вперед бесконечен.
Стоит отметить, что Baichuan Intelligence отличается от других крупных модельных компаний своей концепцией открытого исходного кода. Это можно увидеть в речи Ван Сяочуаня на пресс-конференции Байчуань-2.
Llama 2 Дни модели с открытым исходным кодом прошли. Теперь мы можем получить модель с открытым исходным кодом, которая является более дружелюбной и функциональной, чем Llama, и которая может помочь поддержать развитие всей экосистемы Китая.
Хотя Llama 2 рекламируется как открытый исходный код, на самом деле он доступен только в английской среде. Напротив, серия Baichuan 2 полностью открыта для китайских пользователей и предоставляет бесплатные услуги в китайско-английской двуязычной среде.
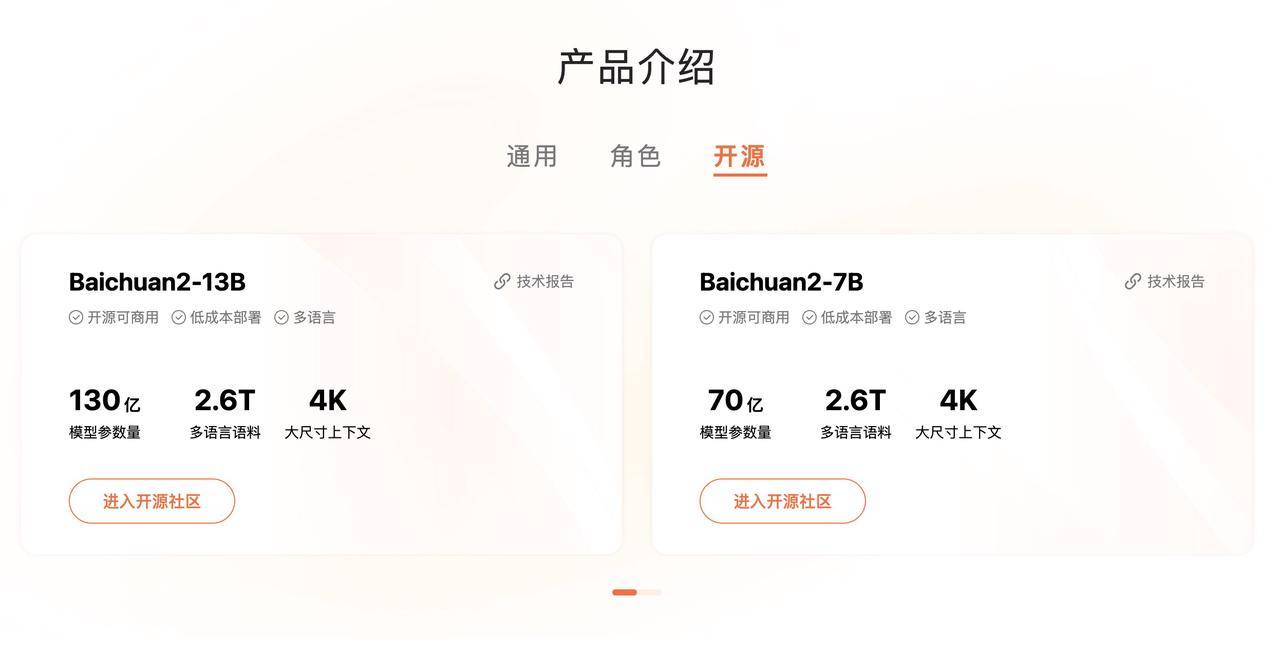
Компания Baichuan Intelligent последовательно открыла исходный код четырех недорогих моделей развертывания, включая Baichuan-7B, Baichuan-13B, Baichuan2-7B и Baichuan2-13B, поддерживая большие модели на китайском и английском языках.
Кроме того, когда СМИ спросили, как добиться того, чтобы модели с открытым исходным кодом и коммерческие модели с закрытым исходным кодом шли рука об руку и быстро повторялись, Чэнь Вэйпэн, соучредитель Baichuan Intelligent Technology, ответил, что это связано с их богатым опытом в области поисковых технологий, который можно быстро перенести и применить к большим моделям.
С технической точки зрения поиск и большие модели имеют много общих технических основ. Например, в ключевом звене обработки данных обучения модели команда провела проверку и оптимизацию данных на основе своего опыта в области поиска, добившись повторной фильтрации и улучшения качества, тем самым обеспечив качественную поддержку данных для модели.
В сентябре прошлого года, говоря о разрыве между отечественными большими моделями и ChatGPT, Ван Сяочуань сделал такое суждение:
GPT-4 постоянно совершенствуется, и недавно они наделали много шума запуском голосовых и графических возможностей. С точки зрения времени, мы думаем, что может потребоваться два или три года, чтобы приблизиться к нынешнему уровню GPT-4.
Конечно, в условиях жесткой конкуренции между крупными моделями недостаточно просто оставаться на стадии исследования технологий. Следующим шагом Baichuan Intelligence является ускорение трансформации технологий в сценарии применения.
Ван Сяочуань неоднократно публично упоминал о «суперприложениях» и даже предсказал, что в этом году в Китае появится несколько суперприложений. И это может стать следующей битвой за большие модели.
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo