За меньшим и более мощным GPT-4o mini будущее моделей искусственного интеллекта больше не значит, что больше — значит лучше.
На прошлой неделе OpenAI выступила лидером, выпустив большой шаг поздно ночью. Выпущенный GPT-4o mini продемонстрировал хорошее представление «победить большого малым», отправив GPT-3.5 Turbo «на пенсию» и даже превзойдя его. это на арене больших моделей LMSYS. Прошел GPT-4.
Что касается большой модели Llama 3.1, выпущенной Meta на этой неделе, то если размер 405B первого эшелона еще ожидается, то версии размера 8B и 70B, которые совершают «маленькие победы над большими», преподносят больше сюрпризов.
И это, возможно, не конец конкурса небольших моделей, а, скорее, новая отправная точка.

Дело не в том, что большие модели недоступны по цене, но маленькие модели более рентабельны.
В огромном мире ИИ о маленьких моделях всегда ходили легенды.
Если посмотреть снаружи, то прошлогодний блокбастер Mistral 7B был назван «лучшей моделью 7B» сразу же после своего выпуска. Он превзошел модель Llama 2 с параметром 13B в нескольких оценочных тестах и превзошел ее в рассуждениях, математике и генерации кода. .
В этом году Microsoft также открыла исходный код самой мощной модели phi-3-mini с малыми параметрами. Хотя количество параметров составляет всего 3,8B, результаты оценки производительности намного превышают уровень той же шкалы параметров и сопоставимы с более крупными моделями, такими как. GPT-3.5 и Сонет Клода-3.
Заглянув внутрь, в начале февраля компания Wall Intelligence запустила MiniCPM, модель параллельного языка с параметрами всего 2B. Она использует меньший размер для достижения более высокой производительности. Ее производительность превосходит популярную французскую модель Mistral-7B, известную как «. Маленькая Сталь. "пистолет".

Не так давно MiniCPM-Llama3-V2.5, имеющий размер параметра всего 8B, превзошел более крупные модели, такие как GPT-4V и Gemini Pro, с точки зрения мультимодальной комплексной производительности и возможностей оптического распознавания символов. Поэтому Стэнфордский университет раскритиковал его. Университетская команда по борьбе с плагиатом.
До прошлой недели OpenAI, которая бомбила поздно ночью, выпустила то, что она описала как «самую мощную и экономичную модель с малыми параметрами» — GPT-4o mini, которая вернула всеобщее внимание к маленькой модели.
С тех пор, как OpenAI втянул мир в воображение генеративного ИИ, от длинных контекстов к изменяющимся параметрам, к агентам, а теперь и к ценовым войнам, развитие внутри страны и за рубежом всегда вращалось вокруг одной логики — оставаться в поле, двигаясь к коммерциализации. . На карточном столе.
Поэтому в поле общественного мнения больше всего бросается в глаза то, что OpenAI, снизившая цены, похоже, вступает в ценовую войну.
Многие люди могут не иметь четкого представления о цене GPT-4o mini. GPT-4o mini стоит 15 центов за 1 миллион входных токенов и 60 центов за 1 миллион выходных токенов, что более чем на 60% дешевле, чем GPT-3.5 Turbo.
Другими словами, GPT-4o mini создает книгу на 2500 страниц всего за 60 центов.

Генеральный директор OpenAI Сэм Альтман также посетовал на X, что по сравнению с GPT-4o mini самая мощная модель двухлетней давности не только имела огромный разрыв в производительности, но и имела стоимость использования, которая была в 100 раз выше, чем сейчас.
В то время как ценовая война за большие модели становится все более ожесточенной, некоторые эффективные и экономичные небольшие модели с открытым исходным кодом с большей вероятностью привлекут внимание рынка. В конце концов, дело не в том, что большие модели нельзя использовать, а в том, что маленькие модели более рентабельны. .
С одной стороны, когда графические процессоры по всему миру распроданы или даже отсутствуют на складе, небольших моделей с открытым исходным кодом с меньшими затратами на обучение и развертывание достаточно, чтобы постепенно одержать верх.
Например, MiniCPM, запущенный Mianbi Intelligence, может добиться резкого снижения затрат на вывод благодаря меньшим параметрам и даже может обеспечить вывод ЦП. Для этого требуется только одна машина для непрерывного обучения параметров и видеокарта для точной настройки параметров. также постоянные улучшения стоимости пространства.
Если вы опытный разработчик, вы даже можете обучить вертикальную модель в юридической сфере, построив небольшую модель самостоятельно, и стоимость вывода может составлять всего одну тысячную от стоимости тонкой настройки большой модели.

Внедрение некоторых приложений «малых моделей» на стороне терминала позволило многим производителям увидеть зарю прибыльности. Например, Facewall Intelligence помогла Народному суду промежуточной инстанции Шэньчжэня запустить судебную систему с использованием искусственного интеллекта, доказав ценность технологии для рынка.
Конечно, правильнее было бы сказать, что изменения, которые мы начнем видеть, — это не переход от больших моделей к маленьким, а переход от одной категории моделей к портфелю моделей, причем выбор правильной модели зависит от от конкретных потребностей организации, сложности задач и имеющихся ресурсов.
С другой стороны, небольшие модели легче развернуть и интегрировать в мобильные устройства, встроенные системы или среды с низким энергопотреблением.
Масштаб параметров небольшой модели относительно невелик, по сравнению с большой моделью, ее потребность в вычислительных ресурсах (таких как вычислительная мощность искусственного интеллекта, память и т. д.) ниже, и она может работать более плавно на конечных устройствах с ограниченными возможностями. Ресурсы. Кроме того, к конечному оборудованию обычно предъявляются более жесткие требования к энергопотреблению, выделению тепла и другим проблемам. Специально разработанные небольшие модели могут лучше адаптироваться к ограничениям конечного оборудования.

Генеральный директор Honor Чжао Мин сказал, что из-за проблем с вычислительной мощностью искусственного интеллекта на стороне клиента параметры могут находиться в диапазоне от 1 до 10 миллиардов. Возможности облачных вычислений в крупных сетевых моделях могут достигать 10–100 миллиардов или даже выше. два. .
Телефон занимает очень ограниченное пространство, не так ли? Он поддерживает 7 миллиардов при ограниченной батарее, ограниченном рассеивании тепла и ограниченной среде хранения. Если вы представляете, что существует так много ограничений, это должно быть самым сложным.
Мы также раскрыли закулисных героев, ответственных за управление смартфонами Apple. Среди них хорошо настроенная маленькая модель 3B, предназначенная для таких задач, как суммирование и полировка. Благодаря адаптеру ее возможности лучше, чем у других. Gemma-7B подходит для работы на мобильных терминалах. В том числе Google также планирует в ближайшие несколько месяцев обновить версию 2B небольшой модели Gemma-2, подходящей для мобильных телефонных терминалов.

Недавно бывший гуру OpenAI Андрей Карпати также высказал мнение, что конкуренция в размерах моделей будет представлять собой «обратную инволюцию», то есть не становится все больше и больше, а кто меньше и гибче.
Почему маленькие модели могут победить большие с помощью маленьких?
Прогноз Андрея Карпати не лишен оснований.
В нашу эпоху, ориентированную на данные, модели быстро становятся больше и сложнее. Большинство очень больших моделей (таких как GPT-4), обученных на огромных данных, фактически используются для запоминания большого количества ненужных деталей, то есть для запоминания информации. наизусть.
Однако точно настроенная модель может даже «выиграть большое с малым» в конкретных задачах, а ее удобство использования сравнимо со многими «сверхбольшими моделями».
Генеральный директор Hugging Face Клем Деланг также предположил, что до 99% случаев использования можно решить с помощью небольших моделей, и предсказал, что 2024 год станет годом малых языковых моделей.
Прежде чем исследовать причины, мы должны сначала популяризировать некоторые научные знания.
В 2020 году OpenAI в своей статье предложила знаменитый закон: закон масштабирования, который означает, что с увеличением размера модели растет и ее производительность. С появлением таких моделей, как GPT-4, постепенно стали проявляться преимущества закона масштабирования.
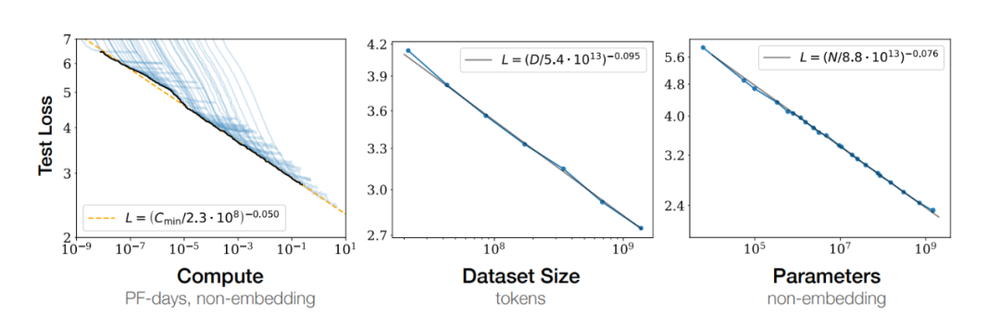
Исследователи и инженеры в области искусственного интеллекта твердо верят, что за счет увеличения количества параметров модели можно еще больше улучшить ее обучаемость и способность к обобщению. Таким образом, мы стали свидетелями скачка масштаба модели от миллиардов параметров до сотен миллиардов и даже к моделям с триллионами параметров.
В мире искусственного интеллекта размер модели — не единственный критерий измерения ее интеллекта.
Напротив, хорошо спроектированная маленькая модель за счет оптимизации алгоритма, улучшения качества данных и применения передовой технологии сжатия часто может показывать производительность, сравнимую или даже лучшую, чем у большой модели при выполнении конкретных задач. Эта стратегия использования малого для достижения больших результатов становится новой тенденцией в области ИИ.
Улучшение качества данных — один из способов победы маленьких моделей над большими.
Сатиш Джаянти, технический директор и соучредитель Coalesce, однажды описал роль данных в моделях:
Если бы LLM существовал в 17 веке, и мы спросили ChatGPT, круглая или плоская Земля, и он ответил, что Земля плоская, это было бы потому, что предоставленные нами данные убедили его в этом. Данные, которые мы предоставляем LLM, и то, как мы их обучаем, напрямую повлияют на его результаты.
Для получения высококачественных результатов большие языковые модели необходимо обучать на высококачественных целевых данных для конкретных тем и областей. Точно так же, как студентам нужны качественные учебники для обучения, магистратурам также нужны качественные источники данных.

Отказавшись от традиционной жестокой эстетики упорного труда для достижения чудес, Лю Чжиюань, постоянный доцент кафедры компьютерных наук Университета Цинхуа и главный научный сотрудник скрытой разведки, недавно предложил закон «лицом к стене» в эпоху больших масштабов. моделей, то есть плотность знаний модели продолжает расти, удваиваясь в среднем каждые восемь месяцев.
Среди них плотность знаний = возможности модели/параметры модели, участвующие в расчете.
Лю Чжиюань ярко объяснил, что если вам зададут 100 вопросов теста IQ, ваш результат будет зависеть не только от того, на сколько вопросов вы ответите правильно, но и от количества нейронов, которые вы используете для ответа на эти вопросы. Чем больше задач вы выполняете с меньшим количеством нейронов, тем выше ваш IQ.
Это именно основная идея, которую передает плотность знаний:
Он состоит из двух элементов. Один элемент — это способность этой модели. Второй элемент — это количество нейронов, необходимое для этой способности, или соответствующее потребление вычислительной мощности.
По сравнению с 175 миллиардами параметров GPT-3, выпущенными OpenAI в 2020 году, в 2024 году был выпущен MiniCPM-2.4B с той же производительностью, но всего с 2,4 миллиардами параметров, что и GPT-3, что увеличило плотность знаний примерно в 86 раз.
Исследование Университета Торонто также показывает, что не все данные необходимы, выявляя высококачественные подмножества из больших наборов данных, которые легче обрабатывать и сохранять всю информацию и разнообразие исходного набора данных.
Даже если до 95% обучающих данных будет удалено, на прогнозирующую эффективность модели в рамках конкретного распределения это может существенно не повлиять.

Самый последний пример — большая модель Meta Llama 3.1.
Когда Meta обучала Llama 3, она передала 15T токенов обучающих данных, но Томас Сиалом, исследователь Meta AI, ответственный за работу после обучения Llama2 и Llama3, сказал: «Текст в Интернете полон бесполезной информации, и обучение основано на эта информация является пустой тратой вычислительных ресурсов.
«В более позднем обучении Ламы 3 нет ответов, написанных вручную… здесь просто используются чисто синтетические данные от Ламы 2».
Кроме того, дистилляция знаний также является одним из важных методов «покорения большого малым».
Под дистилляцией знаний понимается использование большой и сложной «модели учителя» для управления обучением небольшой и простой «модели ученика», которая может передать высокую производительность и превосходную способность к обобщению большой модели более легким, вычислительным моделям меньшего размера, которые стоят дороже. меньше.

После выпуска Llama 3.1 генеральный директор Meta Цукерберг написал длинную статью «ИИ с открытым исходным кодом — это путь вперед», в которой он также подчеркнул важность тонкой настройки и очистки небольших моделей.
Нам необходимо обучать, настраивать и совершенствовать наши собственные модели. Каждая организация имеет разные потребности, которые лучше всего удовлетворяются с помощью моделей, которые обучены или настроены в разных масштабах и на конкретных данных.
Для задач на устройстве и задач классификации требуются небольшие модели, а для более сложных задач — большие модели.
Теперь вы можете взять самые современные модели Llama, продолжить их обучение на собственных данных, а затем отфильтровать их до размера модели, который лучше всего соответствует вашим потребностям, причем ваши данные не будут видны ни нам, ни кому-либо еще.
В отрасли также принято считать, что версии Meta Llama 3.1 8B и 70B перегоняются из сверхбольших чашек. Таким образом, общая производительность значительно улучшена, а эффективность модели также выше.
Или оптимизация архитектуры модели также имеет ключевое значение. Например, первоначальная цель разработки MobileNet — реализовать эффективные модели глубокого обучения на мобильных устройствах.
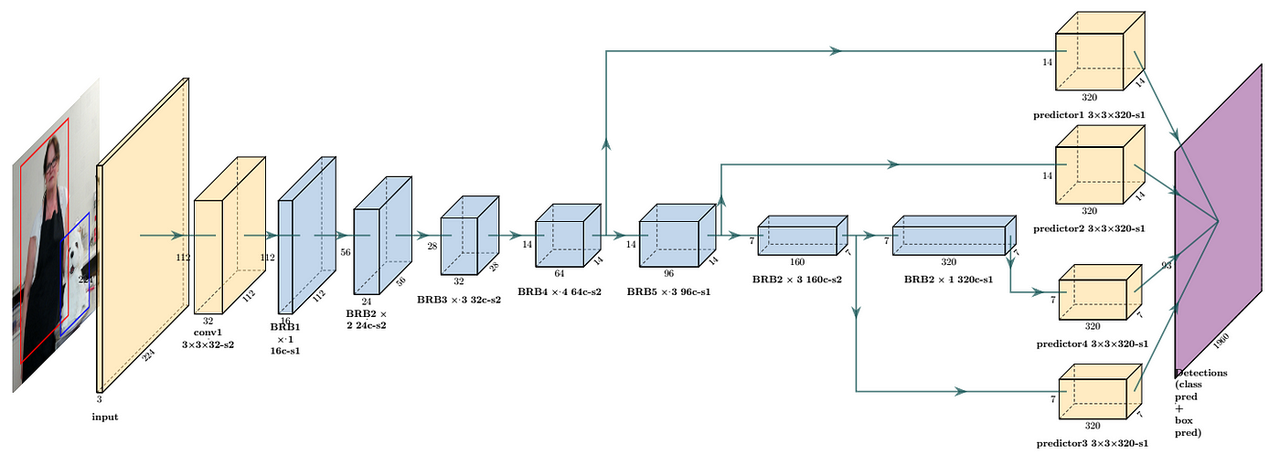
Это значительно уменьшает количество параметров модели за счет отделимой по глубине свертки. По сравнению с ResNet MobileNetV1 уменьшает количество параметров примерно в 8-9 раз.
MobileNet более эффективен в вычислительном отношении из-за меньшего количества параметров. Это особенно важно для сред с ограниченными ресурсами, таких как мобильные устройства, поскольку это может значительно снизить требования к вычислительным ресурсам и хранилищам, не жертвуя при этом слишком большой производительностью.
Несмотря на прогресс, достигнутый на техническом уровне, сама индустрия искусственного интеллекта по-прежнему сталкивается с проблемой долгосрочных инвестиций и высоких затрат, а цикл окупаемости относительно длинный.
По неполной статистике «Daily Economic News», по состоянию на конец апреля этого года в Китае было запущено в общей сложности около 305 крупных моделей, однако по состоянию на 16 мая оставалось еще около 165 крупных моделей, которые еще не вышли на рынок. завершена регистрация.
Основатель Baidu Робин Ли публично раскритиковал существование многих нынешних базовых моделей — это пустая трата ресурсов, и предложил больше использовать ресурсы для изучения возможности объединения моделей с отраслями и разработки следующего потенциального суперприложения.

Это также основная проблема современной индустрии искусственного интеллекта: непропорциональное противоречие между увеличением количества моделей и реализацией практических приложений.
Столкнувшись с этой проблемой, внимание отрасли постепенно переключилось на ускорение применения технологий искусственного интеллекта, а небольшие модели с низкими затратами на развертывание и более высокой эффективностью стали более подходящей точкой прорыва.
Поэтому мы заметили, что начали появляться небольшие модели, ориентированные на конкретные области, например, большие модели для приготовления пищи и большие модели для прямых трансляций. Хотя эти имена могут показаться немного блефовыми, они находятся на правильном пути.
Короче говоря, ИИ в будущем перестанет быть единым огромным существом, а станет более разнообразным и персонализированным. Рост количества маленьких моделей является отражением этой тенденции. Их отличное выполнение конкретных задач доказывает, что «маленькие, но красивые» тоже могут завоевать уважение и признание.
Еще кое-что
Если вы хотите заранее запустить модель на своем iPhone, вы также можете попробовать приложение для iOS под названием «Hugging Chat», запущенное Hugging Face.
Приложение можно загрузить с помощью учетной записи Magic Hemei District App Store, а затем пользователи смогут получить доступ и использовать различные модели с открытым исходным кодом, включая, помимо прочего, Phi 3,
Mixtral, Command R+ и другие модели.
Напоминаем: для лучшего опыта и производительности рекомендуется использовать последнюю версию iPhone Pro последнего поколения.
Ссылка для скачивания: https://apps.apple.com/us/app/huggingchat/id6476778843.
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo