Как подсчитать уникальные значения в Excel
Наборы данных в Excel часто содержат одно и то же значение несколько раз в столбце. Иногда может быть полезно узнать, сколько уникальных значений находится в столбце. Например, если вы управляете магазином и имеете электронную таблицу всех ваших транзакций, вы можете захотеть определить, сколько у вас уникальных клиентов, а не подсчитывать каждую транзакцию.
Это можно сделать, подсчитав уникальные значения в Excel, используя методы, о которых мы поговорим ниже.
Удалить повторяющиеся данные из столбца
Быстрый и грязный способ подсчета уникальных значений в Excel – удалить дубликаты и посмотреть, сколько записей осталось. Это хороший вариант, если вам нужен быстрый ответ и не нужно отслеживать результат.
Скопируйте данные на новый лист (чтобы случайно не удалить нужные данные). Выберите значения или столбец, из которого вы хотите удалить повторяющиеся значения. В разделе Data Tools на вкладке Data выберите Remove Duplicates . Это удаляет все повторяющиеся данные и оставляет только уникальные значения.

Тот же процесс работает, если информация разделена между двумя столбцами. Разница в том, что вам нужно выбрать оба столбца. В нашем примере у нас есть столбец для имени и второй для фамилии.
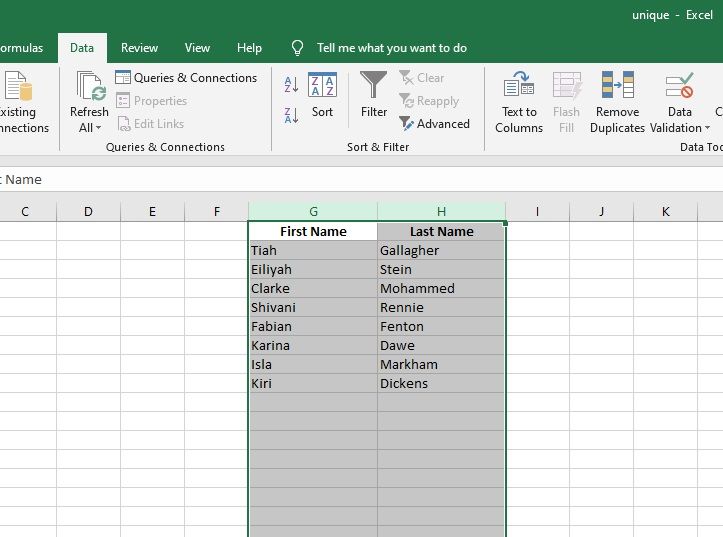
Если вы хотите отслеживать количество уникальных значений, лучше вместо этого написать формулу. Ниже мы покажем вам, как это сделать.
Подсчет уникальных значений с помощью формулы Excel
Чтобы подсчитывать только уникальные значения, нам нужно объединить несколько функций Excel. Сначала нам нужно проверить, не является ли каждое значение дубликатом, а затем подсчитать оставшиеся записи. Нам также нужно использовать функцию массива.
Если вы просто ищете ответ, используйте эту формулу, заменяя каждый экземпляр A2: A13 ячейками, которые вы хотите использовать:
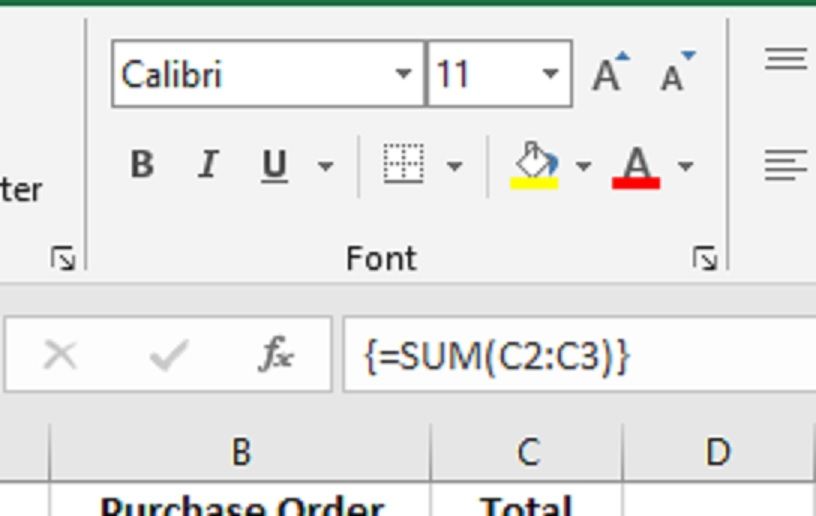
{=SUM(IF(FREQUENCY(MATCH(A2:A13, A2:A13, 0), MATCH(A2:A13, A2:A13, 0)) >0, 1))}Как мы туда попали, немного сложнее. Поэтому, если вы хотите понять, почему эта формула работает, ниже мы разберем ее по частям.
Объяснение функции массива
Давайте сначала начнем с объяснения того, что такое массив. Массив – это одна переменная, которая содержит несколько значений. Это похоже на одновременное обращение к кучке ячеек Excel вместо обращения к каждой ячейке по отдельности.
С нашей точки зрения, это странное различие. Если мы скажем формуле, чтобы она смотрела на ячейки A2: A13 в обычном режиме или в виде массива, данные для нас выглядят одинаково. Разница в том, как Excel обрабатывает данные за кулисами. Это настолько тонкая разница, что новейшие версии Excel больше не делают различий между ними, хотя старые версии это делают.
Для наших целей более важно знать, как мы можем использовать массивы. Если у вас установлена последняя версия Excel, она автоматически сохраняет данные в виде массива, когда это более эффективно. Если у вас более старая версия, когда вы закончите писать формулу, нажмите Ctrl + Shift + Enter . Как только вы это сделаете, формула будет окружена фигурными скобками, чтобы показать, что она находится в режиме массива.
Знакомство с функцией FREQUENCY
Функция ЧАСТОТА сообщает нам, сколько раз число появляется в списке. Это замечательно, если вы работаете с числами, но наш список – текст. Чтобы использовать эту функцию, мы должны сначала найти способ преобразовать наш текст в числа.
Если вы пытаетесь подсчитать уникальные значения в списке чисел, вы можете пропустить следующий шаг.
Использование функции ПОИСКПОЗ
Функция ПОИСКПОЗ возвращает позицию первого вхождения значения. Мы можем использовать это для преобразования нашего списка имен в числовые значения. Ему необходимо знать три части информации:
- Какую ценность вы ищете?
- Какой набор данных вы проверяете?
- Вы ищете значения выше, ниже или равные целевому значению?
В нашем примере мы хотим найти каждое имя наших клиентов в нашей электронной таблице Exel, чтобы увидеть, появляется ли их точное имя снова в другом месте.
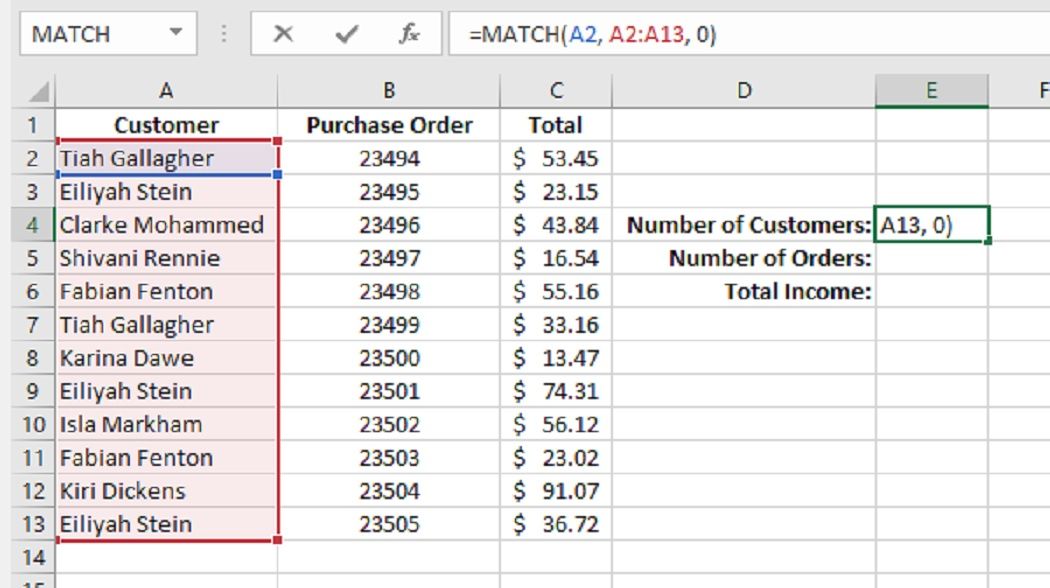
В приведенном выше примере мы ищем в нашем списке (A2: A13) Тиа Галлахер (A2) и хотим получить точное совпадение. 0 в последнем поле указывает, что это должно быть точное совпадение. Наш результат говорит нам, где в списке имя появилось первым. В данном случае это было первое имя, поэтому результат равен 1.
Проблема в том, что мы заинтересованы во всех наших клиентах, а не только в Тиа. Но если мы попытаемся найти A2: A13 вместо A2, мы получим ошибку. Вот здесь и пригодятся функции массива. Первый параметр может принимать только одну переменную, иначе он вернет ошибку. Но с массивами обращаются как с единственной переменной.
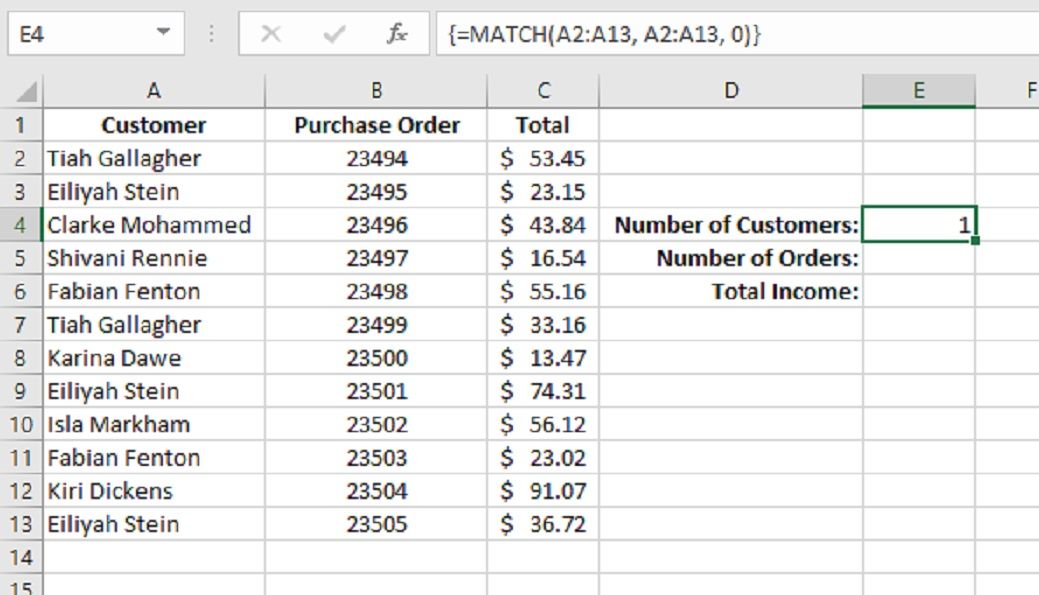
Теперь наша функция сообщает Excel, что нужно проверять совпадения для всего массива. Но подождите, наш результат не изменился! Он по-прежнему говорит 1. Что здесь происходит?
Наша функция возвращает массив. Он просматривает каждый элемент в нашем массиве и проверяет совпадения. Результаты всех имен сохраняются в массиве, который возвращается как результат. Поскольку ячейка показывает только одну переменную за раз, она показывает первое значение в массиве.
Вы можете убедиться в этом сами. Если вы измените первый диапазон на A3: A13, результат изменится на 2. Это потому, что имя Eiliyah стоит на втором месте в списке, и теперь это значение сохраняется первым в массиве. Если вы измените первый диапазон на A7: A13, вы снова получите 1, потому что имя Тиа впервые появляется в первой позиции проверяемого набора данных.
Использование функции ЧАСТОТА
Теперь, когда мы изменили имена на числовые значения, мы можем использовать функцию ЧАСТОТА. Подобно MATCH, он требует поиска цели и набора данных для проверки. Также, как и в случае с MATCH, мы не хотим искать только одно значение, мы хотим, чтобы функция проверяла каждый элемент в нашем списке.
Целью, которую мы хотим, чтобы функция FREQUENCY проверяла, является каждый элемент в массиве, возвращаемый нашей функцией MATCH. И мы хотим проверить набор данных, возвращаемый функцией MATCH. Таким образом, мы отправляем созданную нами выше функцию MATCH для обоих параметров.
Если вы ищете уникальные числа и пропустили предыдущий шаг, вы должны отправить диапазон чисел в качестве обоих параметров. Для поиска по всем числам в вашем списке вам также потребуется использовать функцию массива, поэтому не забудьте нажать Ctrl + Shift + Enter после ввода формулы, если вы используете старую версию Excel.

Теперь наш результат – 2. И снова наша функция возвращает массив. Он возвращает массив, в котором указано количество появлений каждого уникального значения. В ячейке отображается первое значение в массиве. В этом случае имя Тиа появляется дважды, поэтому возвращается частота 2.
Использование функции ЕСЛИ
Теперь в нашем массиве столько же значений, сколько у нас уникальных значений. Но мы еще не закончили. Нам нужен способ сложить это. Если мы преобразуем все значения в массиве в 1 и просуммируем их, то мы наконец узнаем, сколько уникальных значений у нас есть.
Мы можем создать функцию ЕСЛИ, которая изменяет все значения выше нуля на 1. Тогда все значения будут равны 1.
Для этого мы хотим, чтобы наша функция IF проверяла, больше ли значения в нашем массиве FREQUENCY нуля. Если true, он должен вернуть значение 1. Вы заметите, что теперь первое значение в массиве возвращается как единое целое.
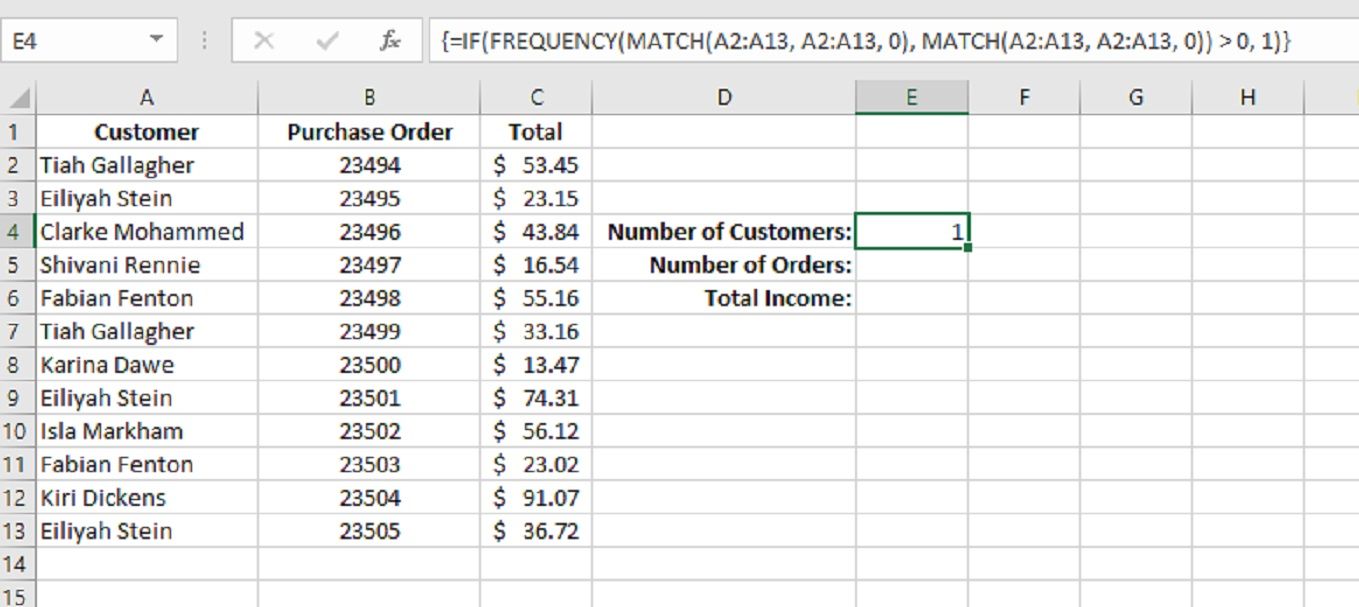
Использование функции СУММ
Мы на последней стадии! Последний шаг – СУММИРОВАТЬ массив.
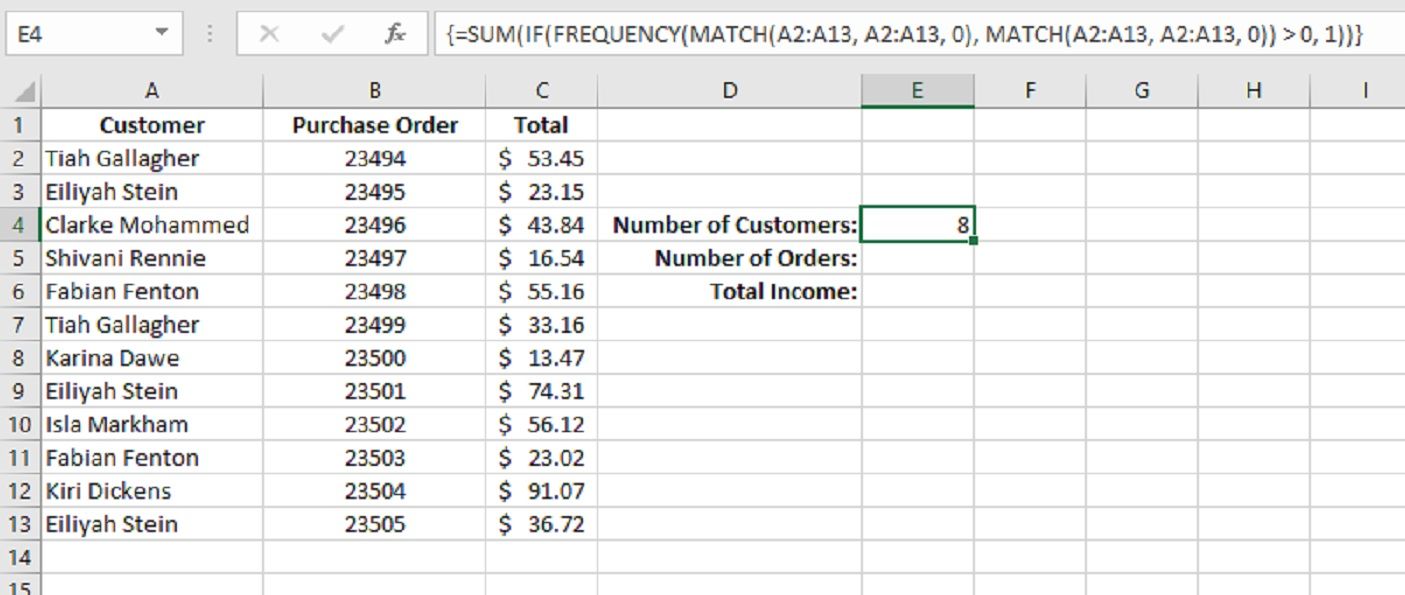
Оберните предыдущую функцию в функцию СУММ. Законченный! Итак, наша окончательная формула:
{=SUM(IF(FREQUENCY(MATCH(A2:A13, A2:A13, 0), MATCH(A2:A13, A2:A13, 0)) >0, 1))}Подсчет уникальных записей в Excel
Это продвинутая функция, требующая больших знаний об Excel. Попытка может быть пугающей. Но после настройки он может быть очень полезным, поэтому, возможно, стоит проработать наше объяснение, чтобы убедиться, что вы его понимаете.
Если вам не нужно так часто подсчитывать уникальные записи, быстрый и грязный совет по удалению повторяющихся значений сработает в крайнем случае!