Китайский рейтинг занимает первое место в мире и равен GPT4o в многочисленных слепых тестах. Почему эта большая отечественная модель стала темной лошадкой в мире искусственного интеллекта?

Все как будто у него двигатель V12.
13 числа этого месяца Кай-фу Ли и Zero One Wish выпустили свой второй продукт — модель с закрытым исходным кодом Yi-Large. Менее чем за полмесяца с момента выхода Yi-Large прошла путь от нового поколения, не боящегося тигров, до мощной группы, идущей впереди волн реки Янцзы.
На прошлой неделе загадочная модель под названием «im-also-a-good-gpt2-chatbot» внезапно появилась на арене крупных моделей Chatbot Arena, занимая позиции сразу выше, чем GPT-4-Turbo, Gemini 1.5 Pro, Claude 3 0pus. Лама-3-70б и другие популярные базовые модели от крупнейших мировых производителей.
Эта загадочная модель является тестовой версией GPT-4o. Генеральный директор OpenAI Сэм Альтман также лично сделал репост и процитировал результаты слепого теста LMSYS Arena после выпуска GPT-4o.
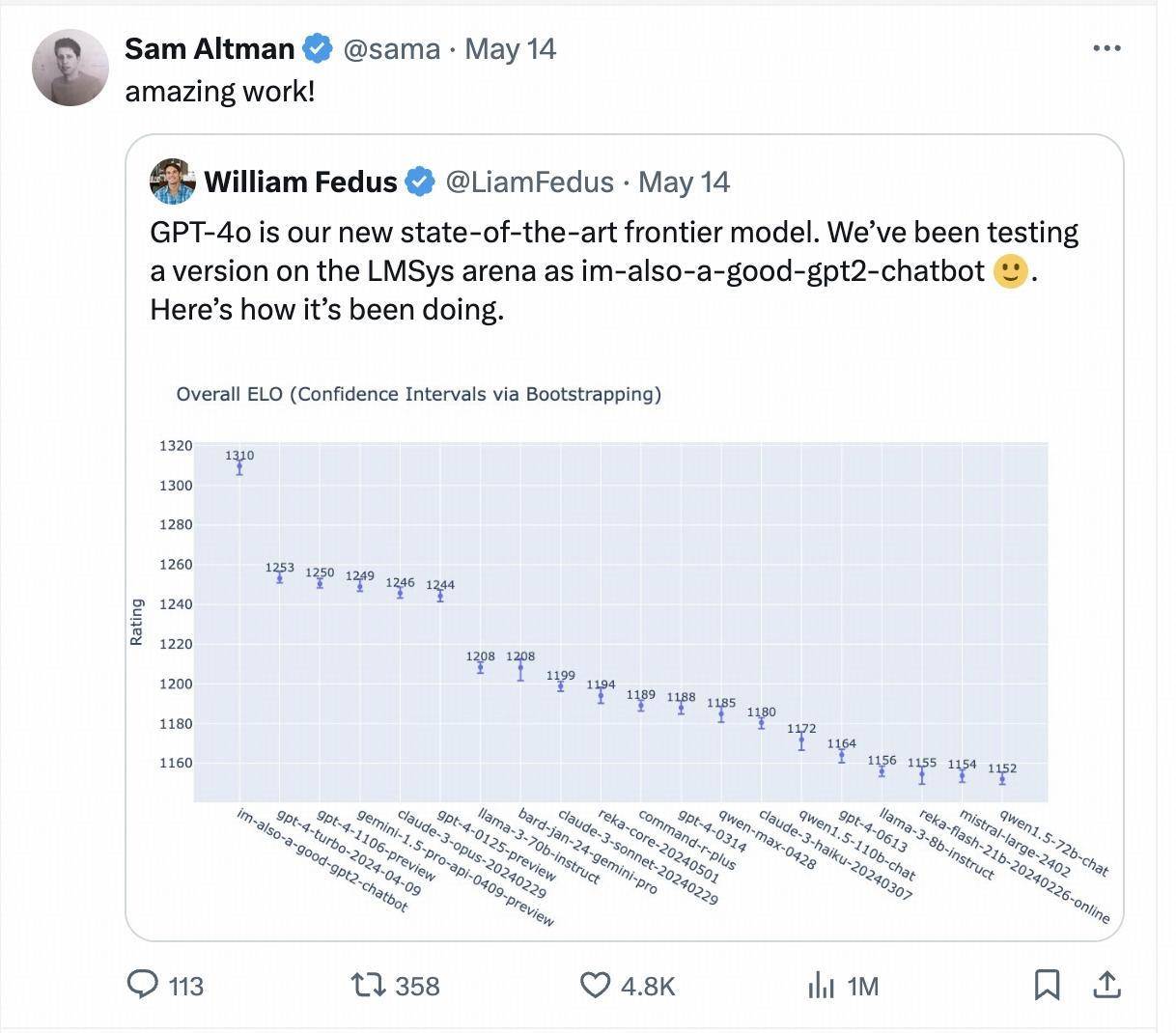
Неделю спустя в последнем обновленном рейтинге снова была инсценирована история «темной лошадки» «я-тоже-хороший-gpt2-чат-бот». На этот раз модель, которая быстро поднялась в рейтинге, была представлена крупным китайским производителем. Модельная компания Zero One Wan Большая модель с закрытым исходным кодом «Yi-Large» с сотнями миллиардов параметров.
В последнем рейтинге LMSYS Blind Test Arena Yi-Large, последняя модель Yi-Large со 100 миллиардами параметров, занимает 7-е место в мире и 1-е место среди крупных моделей в Китае, обогнав Llama-3-70B и Claude 3 Sonnet. ; Его китайский рейтинг делит первое место в мире с GPT4o;
Chatbot Arena, выпущенная открытой исследовательской организацией LMSYS Org (Организация больших модельных систем), стала соревнованием между крупными международными компаниями, такими как OpenAI, Anthropic, Google и Meta, а также открыла функцию массового голосования. .
Таким образом, Lingyiwuwu стала единственной крупной китайской модельной компанией, чьи собственные модели вошли в первую десятку общего списка.
В общем списке серия GPT занимает 4 места из 10 лучших. В сортировке по учреждениям 01W01.AI уступает только OpenAI, Google и Anthropic и официально вошла в число лучших в мире крупных корпоративных моделей.
Теперь кажется, что лозунг «Стань №1 в мире» — это не просто лозунг, а становится.
Китайский балл занимает первое место в мире, а «выжигающий мозг» слепой тест — второе в мире.
Результаты слепого тестирования LMSYS Chatboat Arena, которые были обновлены только 20 мая 2024 года по американскому времени, основаны на реальных голосах более 11,7 миллионов пользователей со всего мира, накопленных на данный момент.
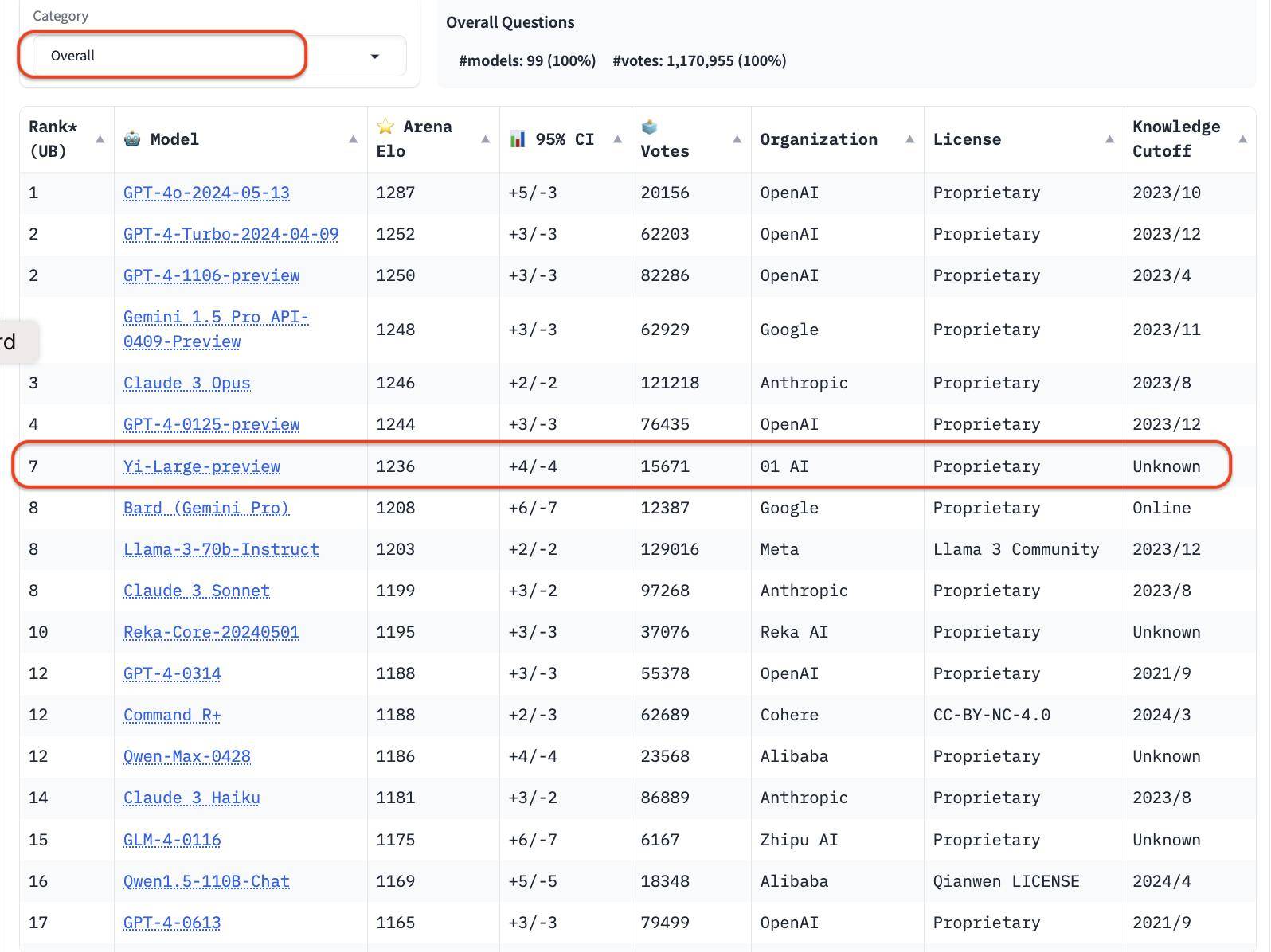
Стоит отметить, что для повышения общего качества запросов Chatbot Arena компания LMSYS также реализовала механизм дедупликации и выдавала список после удаления избыточных запросов.
Этот новый механизм предназначен для устранения чрезмерно повторяющихся запросов пользователя, таких как слишком повторяющееся «Привет», которые могут повлиять на точность рейтинга.
LMSYS публично заявила, что список после удаления избыточных запросов в будущем станет списком по умолчанию.
В общем списке после удаления избыточных запросов рейтинг Elo Yi-Large пошел еще дальше, заняв четвертое место с Claude 3 Opus и GPT-4-0125-preview.
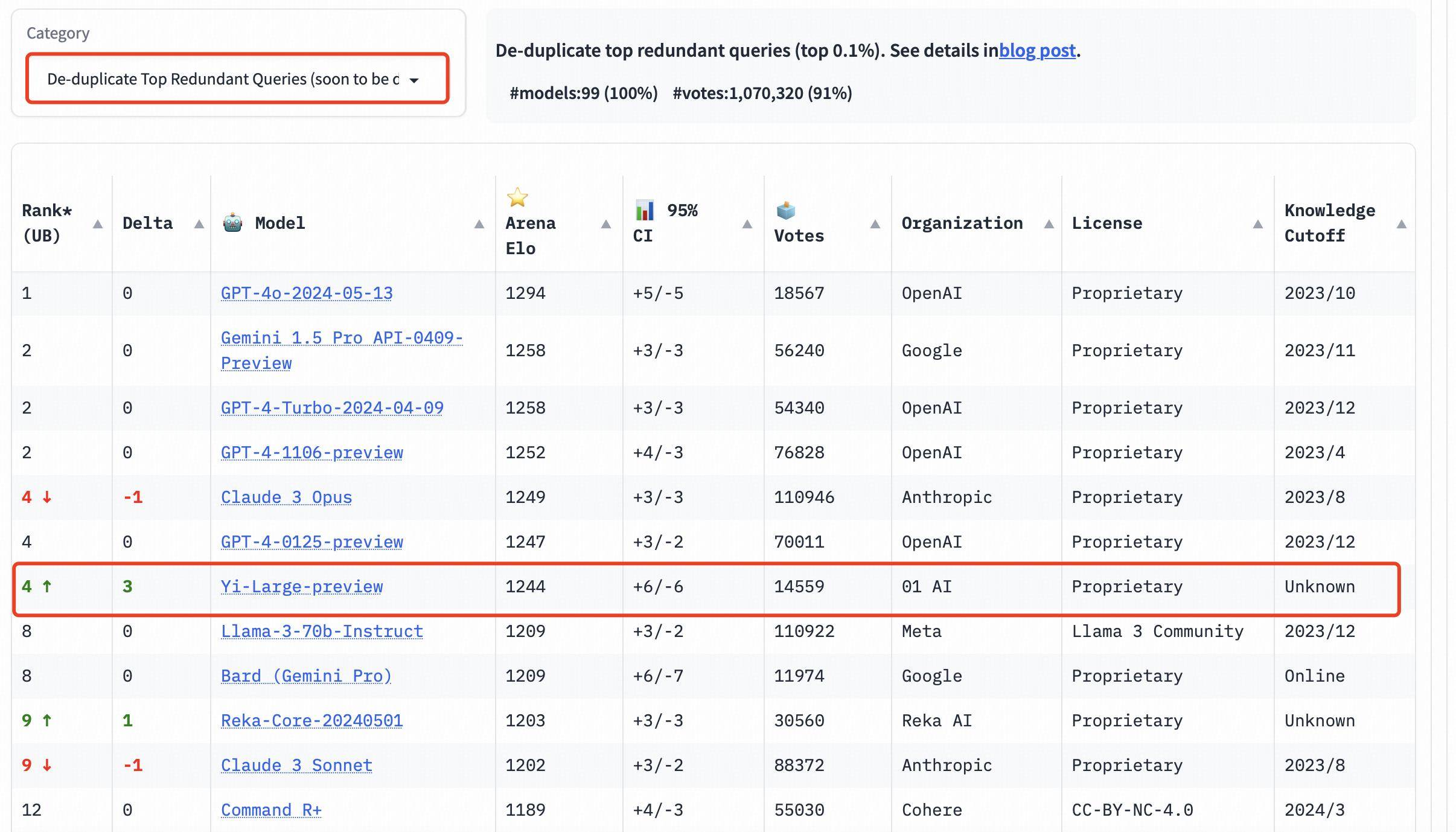
В дополнение к общему списку LMSYS добавила три новые языковые оценки на английском, китайском и французском языках и начала уделять внимание разнообразию глобальных крупных моделей. Yi-Large возглавил список китайских языков, разделив первое место с Qwen-Max, а GLM-4 также показал хорошие результаты в списке китайских языков.
Среди крупных отечественных производителей моделей исключительно хорошие результаты показали Qwen-Max от Alibaba и GLM-4 от Zhipu.
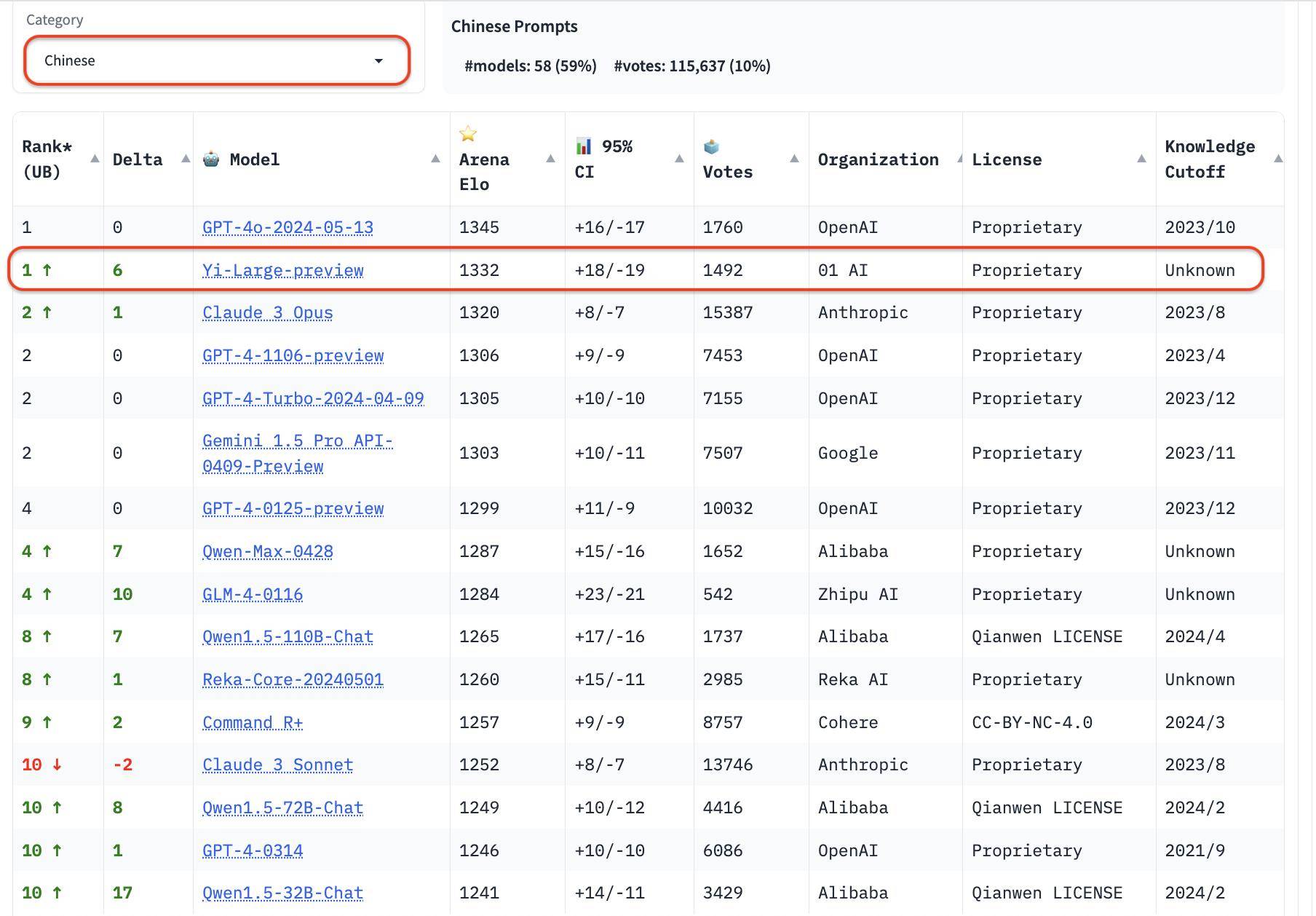
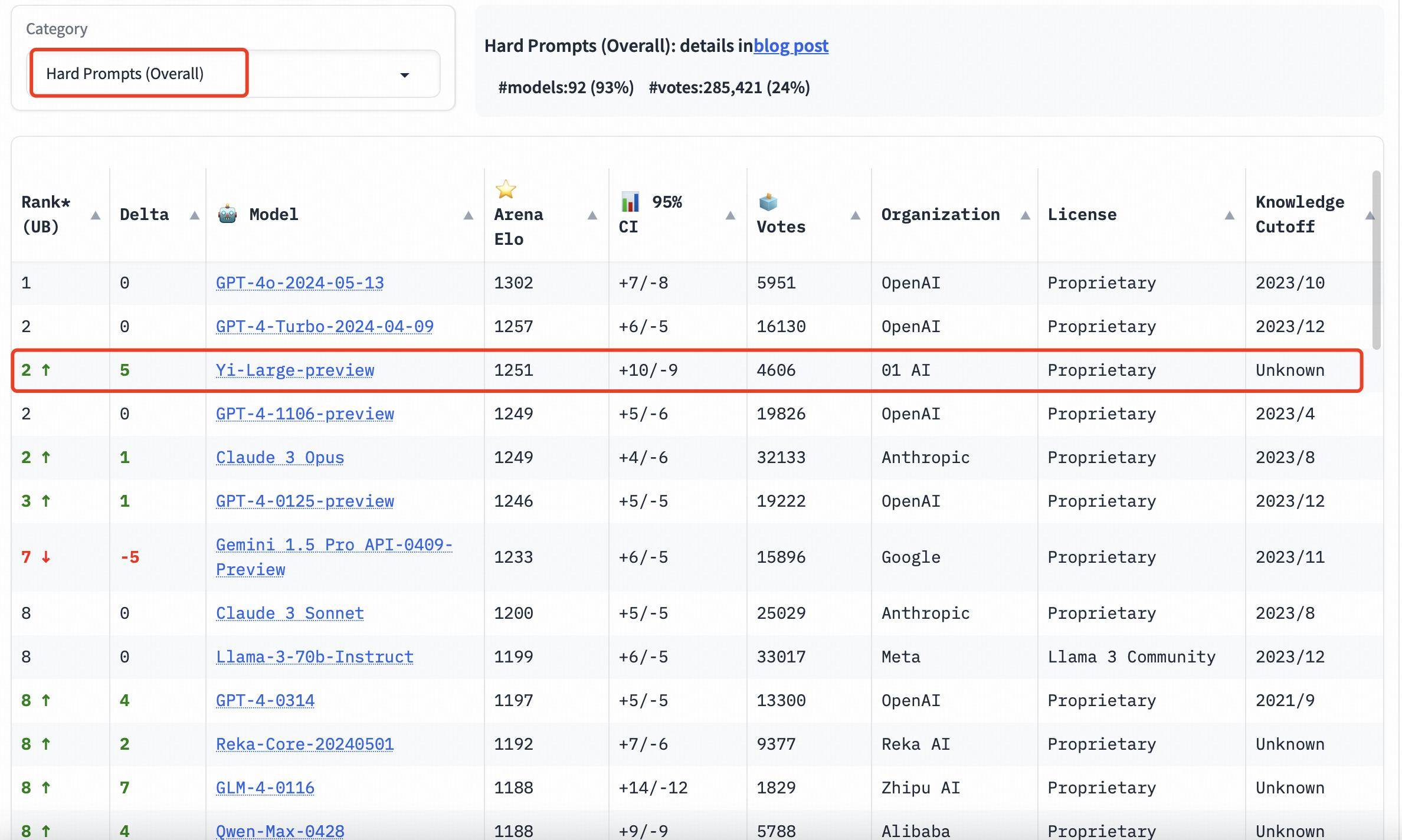
В рейтинге категорий Yi-Large также показывает хорошие результаты. Три оценки способностей к программированию, длинные вопросы и последние «сложные слова-подсказки» представляют собой целевые списки, предоставленные LMSYS. Они известны своим профессионализмом и высокой сложностью. Их можно назвать «самой мозговой» публичной слепотой среди больших моделей. . Измерение.
Три оценки способностей к программированию, длинные вопросы и новейшие «сложные слова-подсказки» являются профессиональными и сложными. Этот тест также известен как «самый мозговой» публичный слепой тест в списке LMSYS.
В рейтинге способностей к программированию (кодирование) показатель Elo Yi-Large превосходит Claude 3 Opus от Anthropic, уступает только GPT-4o и занимает второе место вместе с GPT-4-Turbo и GPT-4;
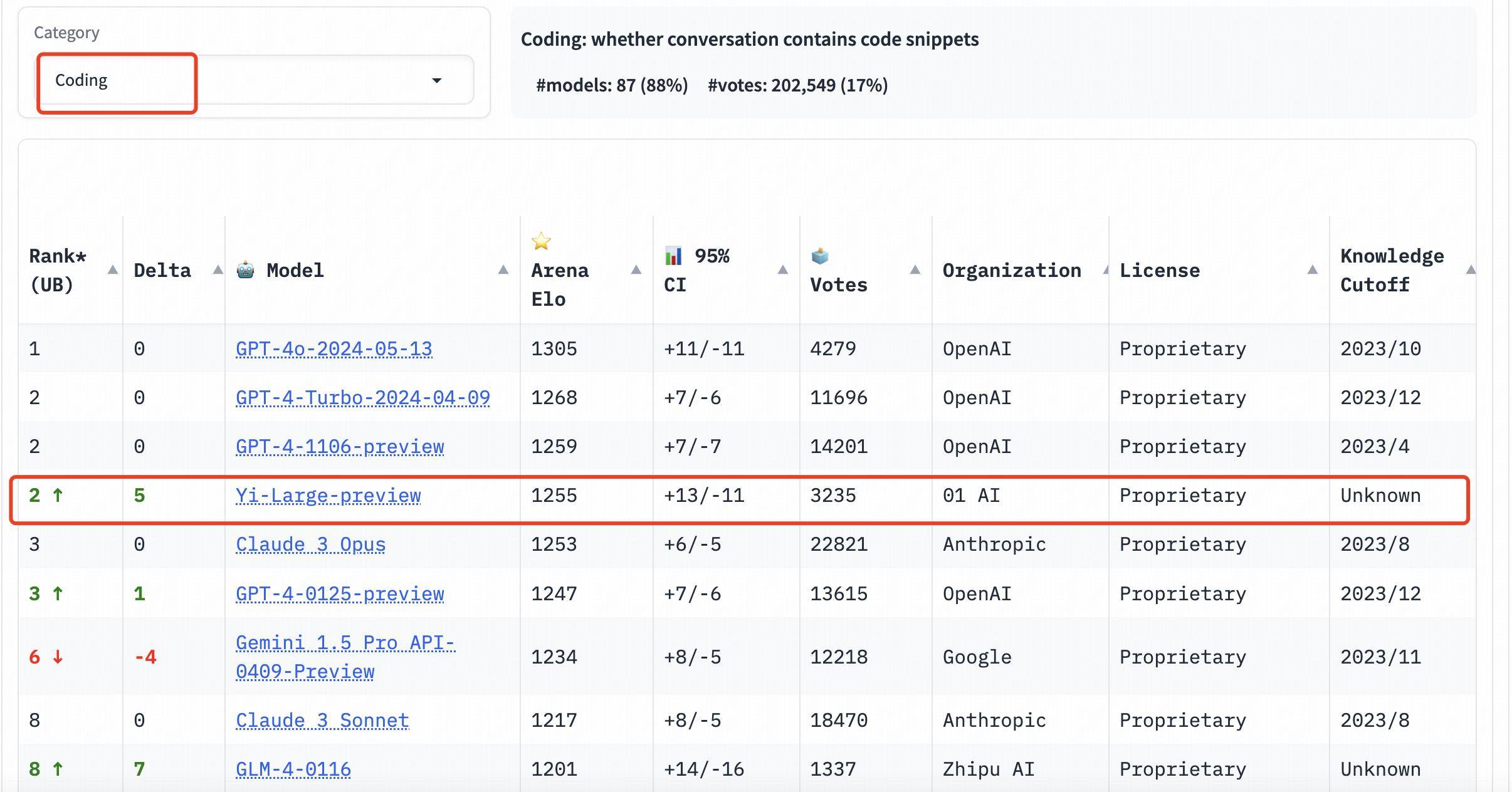
В списке Longer Query Yi-Large также занимает второе место в мире, разделяя GPT-4-Turbo, GPT-4 и Claude 3 Opus;

В списке Hard Prompts Yi-Large делит второе место с GPT-4-Turbo, GPT-4 и Claude 3 Opus.
Используйте научные методы для получения объективных результатов
Как обеспечить объективную и справедливую оценку больших моделей всегда было темой, вызывающей широкую озабоченность в отрасли.
Раньше в отрасли существовали различные методы «перелистывания рейтингов», но они всегда не могли отразить истинные возможности крупных моделей, оставляя желающих разобраться в тумане, а инвесторов в смежных отраслях чесать затылки. .
Chatbot Arena, выпущенная организацией LMSYS, начинает разрушать этот хаос.
Благодаря новому формату «арены» и строгости команды тестировщиков он стал эталоном, признанным в мировой индустрии. Даже OpenAI был анонимно предварительно выпущен и протестирован на LMSYS до официального выпуска GPT-4o.
Андрей Карпати, член команды-основателя OpenAI, даже публично заявил:
Арена чат-ботов — это здорово.
По форме Chatbot Arena опирается на идеи горизонтальной сравнительной оценки эпохи поисковых систем:
- Во-первых, все «входные» модели, загруженные на оценку, случайным образом объединяются в пары и представляются пользователям в виде анонимных моделей;
- Затем реальным пользователям предлагается ввести свои собственные слова-подсказки, и реальные пользователи будут оценивать ответы на две модели продуктов, не зная названия модели;
- Затем на платформе слепого тестирования https://arena.lmsys.org/ большие модели сравниваются попарно, и пользователь самостоятельно вводит вопросы о больших моделях;
- Модель A и Модель B генерируют реальные результаты двух моделей ПК с обеих сторон соответственно. Пользователи могут проголосовать под результатами, чтобы выбрать один из четырех: Модель A лучше/Модель B лучше/Обе равны/Обе не хороши;
- После подачи можно провести следующий раунд ПК.
За счет краудфандинга реальных пользователей для проведения слепого онлайн-тестирования в режиме реального времени и анонимного голосования Chatbot Arena с одной стороны снижает влияние предвзятости, а с другой стороны, в максимально возможной степени избегает возможности ранжирования на основе набора тестов. тем самым повышая объективность конечных результатов.
Chatbot Arena также делает общедоступными все данные голосования пользователей после их очистки и анонимизации.
После сбора данных о голосовании реальных пользователей LMSYS Chatbot Arena также будет использовать систему оценки Elo для количественной оценки производительности модели, дальнейшей оптимизации механизма оценки и стремления объективно отражать силу участников.
В системе подсчета очков Эло каждый участник получает базовый балл, и после каждой игры балл участника корректируется по результатам игры.
Система рассчитает вероятность победы в игре на основе рейтинга участника. Как только игрок с низким счетом победит игрока с высоким результатом, игрок с низким счетом получит больше очков, и наоборот.
Внедряя систему оценки Эло, LMSYS Chatbot Arena в значительной степени обеспечивает объективность и справедливость рейтинга.
Используйте малое, чтобы выиграть большое
На этот раз в Chatbot Arena приняли участие 44 модели, включая как лучшую модель с открытым исходным кодом Llama3-70B, так и модели с закрытым исходным кодом от крупных производителей.
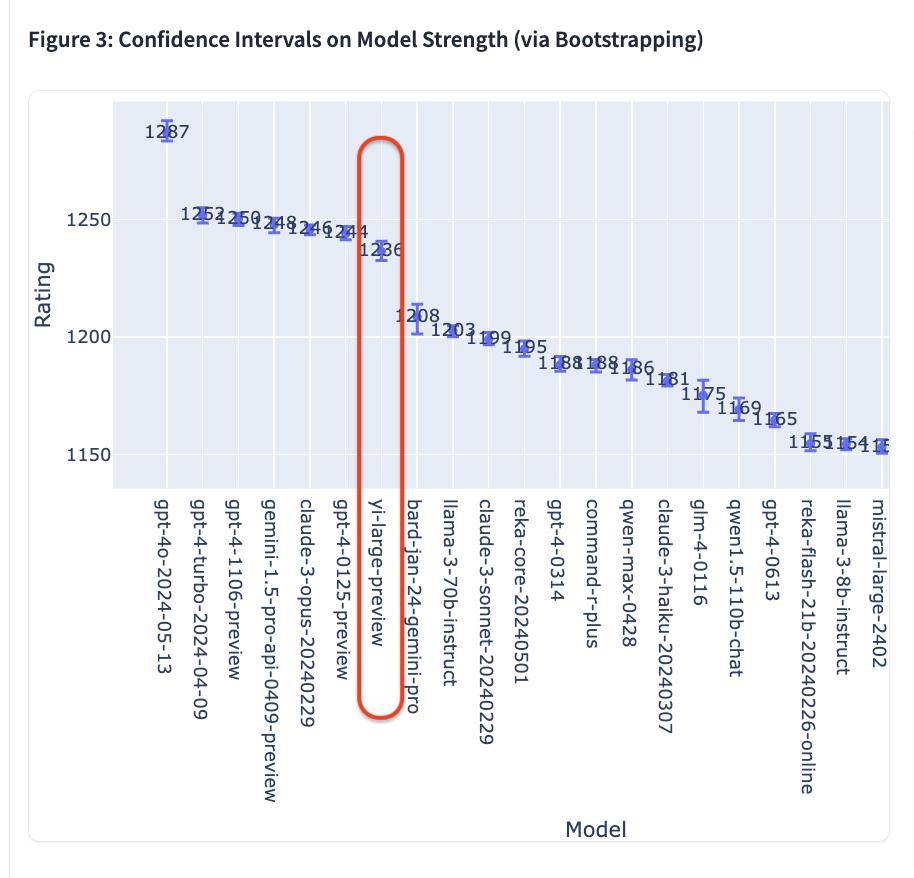
- Судя по последнему баллу Эло, GPT-4o возглавляет список с результатом 1287;
- GPT-4-Turbo, Gemini 1 5 Pro, Claude 3 0pus, Yi-Large и другие модели находятся во втором эшелоне с баллами около 1240;
- Впоследствии баллы Bard (Gemini Pro), Llama-3-70b-Instruct и сонета Claude 3 резко упали примерно до 1200 баллов.
Стоит отметить, что топ-6 моделей принадлежат зарубежным гигантам OpenAI, Google и Anthropic соответственно. Zero-One Wansheng занимает четвертое место в мире, а такие модели, как GPT-4 и Gemini 1.5 Pro, имеют параметры уровня триллиона. является флагманской моделью масштаба, а другие модели также имеют уровень параметров в сотни миллиардов.
Yi-Large «требует малого, чтобы выиграть по-крупному», отставая от него с уровнем параметра всего 100 миллиардов.

Конкурентная разработка крупных моделей ИИ все еще находится на ожесточенной стадии, и «Битва сотен моделей» искусственного интеллекта будет продолжаться. В этой области, где в качестве единиц итерации используются «недели» или даже «дни». наличие относительно справедливой и объективной системы оценки становится особенно важным.
Оценочная платформа, которая постоянно обновляет систему оценки, может не только позволить отраслевым инвесторам видеть истинный статус технологического развития, но также предоставить пользователям право выбирать передовые модели, а также может способствовать здоровому развитию всей индустрии крупных моделей. .
Будь то повторение возможностей своих собственных моделей или ради долгосрочной репутации, крупные производители моделей должны активно участвовать в авторитетных платформах оценки, таких как Chatbot Arena, чтобы доказать свою продукцию с помощью реальных отзывов пользователей и профессиональных механизмов оценки конкурентоспособности.
Напротив, если вас заботят только результаты рейтингов и игнорируют реальный эффект применения модели, разрыв между возможностями модели и рыночным спросом станет более очевидным, и в конечном итоге будет трудно закрепиться в жестком ИИ. рыночная конкуренция.
На волне эпохи искусственного интеллекта, если крупные производители моделей хотят быть отличными или даже первоклассными, им необходимы как минимум два качества:
- Мне приходится проверять себя трижды в день: приобретать опыт посредством прогресса и получать ответы через соревнование;
- Настоящее золото не боится огня: вместо того, чтобы занимать первое место в «диком списке», лучше заглянуть внутрь себя и улучшить свои истинные способности.
Чего стоит ожидать, так это того, что теперь существует группа превосходных отечественных производителей крупномасштабных моделей, которые практичны, инновационны в исследованиях и разработках и могут даже конкурировать с отраслевыми гигантами на международной арене.
Адрес для публичного голосования на арене чат-ботов LMSYS: https://arena.lmsys.org/
Рейтинг рейтинга лидеров чат-бота LMSYS (постоянное обновление): https://chat.lmsys.org/?leaderboard
# Добро пожаловать на официальную общедоступную учетную запись WeChat aifaner: aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo