Модель следующего поколения OpenAI сталкивается с серьезными узкими местами, и бывший главный научный сотрудник раскрывает новый технологический маршрут

Большая языковая модель OpenAI следующего поколения «Орион», возможно, столкнулась с беспрецедентным узким местом.
Как сообщает The Information, внутренние сотрудники OpenAI заявили, что улучшение производительности модели Orion не оправдало ожиданий и что улучшение качества оказалось «намного меньшим», чем при обновлении с GPT-3 до GPT-4.
Кроме того, они заявили, что Orion не более надежен, чем его предшественник GPT-4, при выполнении определенных задач. Хотя у Orion более сильные языковые навыки , он, возможно, не сможет превзойти GPT-4 с точки зрения программирования .

▲Источник изображения: WeeTech
В отчете отмечается, что предложение высококачественных текстов и других данных для обучения сокращается, что затрудняет поиск хороших данных для обучения, тем самым замедляя разработку больших языковых моделей (LLM) в некоторых аспектах.
Мало того, будущее обучение потребует больше вычислительных ресурсов, финансовых ресурсов и даже электроэнергии . Это означает, что стоимость и стоимость разработки и эксплуатации Orion и последующих больших языковых моделей станут дороже.
Ноам Браун, исследователь из OpenAI, недавно заявил на конференции TED AI, что более продвинутые модели могут оказаться « экономически нецелесообразными »:
Действительно ли нам нужно тратить сотни миллиардов или триллионов долларов на обучающие модели? В какой-то момент закон расширения нарушается.
В связи с этим OpenAI создала базовую команду под руководством Ника Райдера, который отвечает за предварительное обучение, чтобы изучить, как бороться с нехваткой обучающих данных и как долго будут действовать законы масштабирования больших моделей.

▲Ноам Браун
Законы масштабирования являются основным предположением в области искусственного интеллекта: пока существует больше данных для обучения и больше вычислительной мощности для облегчения процесса обучения, большие языковые модели могут продолжать улучшать производительность с той же скоростью.
Проще говоря, законы масштабирования описывают взаимосвязь между входными данными (объемом данных, вычислительной мощностью, размером модели) и выходными данными, то есть степень повышения производительности, когда мы вкладываем больше ресурсов в большую языковую модель.
Например, обучение большой языковой модели похоже на сборку автомобиля в мастерской . Первоначально мастерская была небольшой, в ней было всего несколько станков и несколько рабочих. В это время каждая дополнительная машина или рабочий могут существенно увеличить выпуск продукции, поскольку эти новые ресурсы непосредственно преобразуются в увеличение производственных мощностей.
По мере увеличения размера завода прирост производительности каждой дополнительной машины или рабочего начинает уменьшаться. Возможно, управление стало более сложным или координация между работниками стала более сложной.
Когда фабрика достигает определенного масштаба, добавление большего количества машин и рабочих может увеличить выпуск продукции лишь в очень ограниченной степени. В этот момент фабрика может приближаться к пределам земли, энергоснабжения, логистики и т. д., и увеличение затрат больше не может привести к пропорциональному увеличению выпуска продукции .

И в этом заключается дилемма Ориона. По мере увеличения размера модели (аналогично суммированию машин и рабочих) улучшение производительности модели может быть очень очевидным в ранней и среднесрочной перспективе. Но на более позднем этапе, даже если размер модели или объем обучающих данных продолжает увеличиваться, улучшение производительности может становиться все меньше и меньше. Это так называемое « упирание в стену ».
В недавней статье, опубликованной на arXiv, также говорится, что из-за растущего спроса на общедоступные текстовые данные и ограниченного объема существующих данных ожидается, что разработка больших языковых моделей исчерпает имеющиеся ресурсы в период с 2026 по 2032 год. человеческие ресурсы текстовых данных.
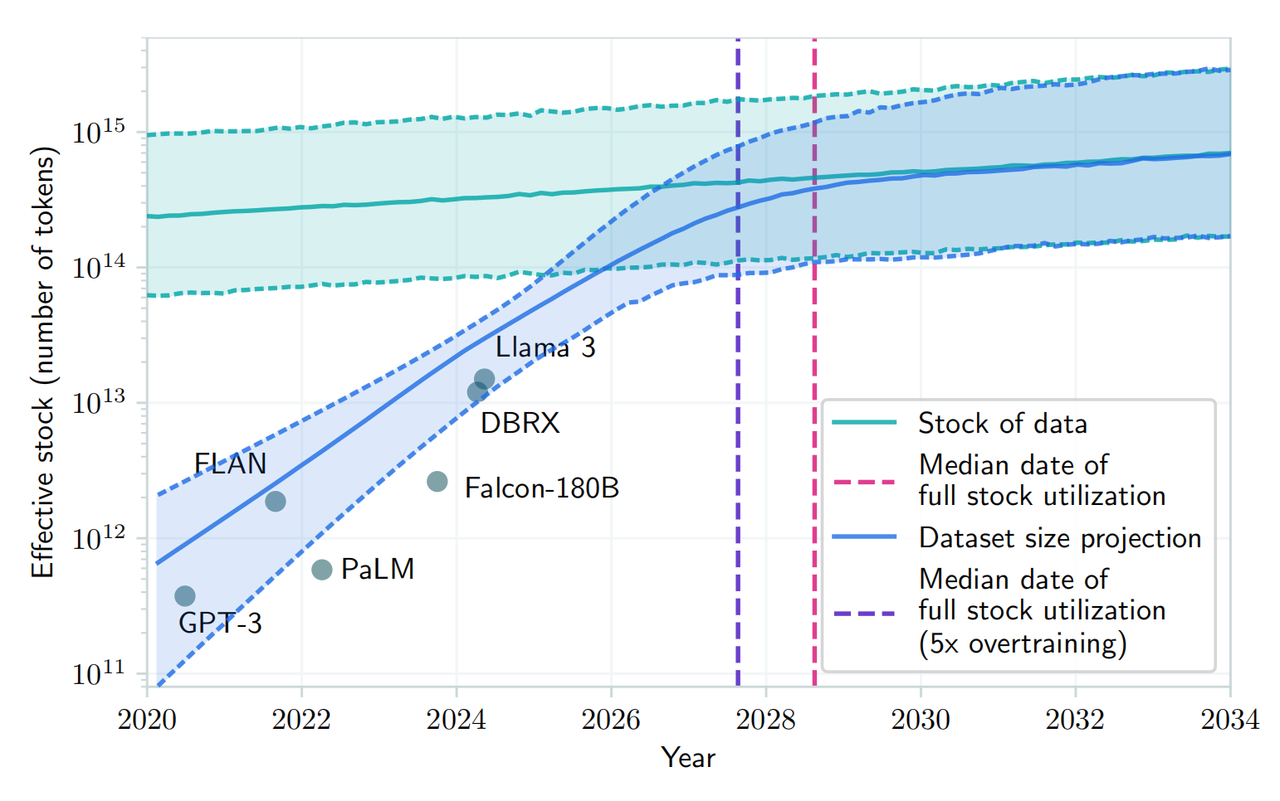
▲Источник изображения: arXiv
Даже несмотря на то, что Норм Браун указывал на «экономические проблемы» будущего обучения моделей, он все же возражал против вышеупомянутой точки зрения. Он считает, что " развитие искусственного интеллекта не замедлится в ближайшее время ".
Исследователи из OpenAI во многом с этим согласны. Они полагают, что, хотя закон расширения модели может замедлиться, на общее развитие ИИ не повлияет оптимизация времени вывода и улучшения после обучения.
Кроме того, генеральные директора Meta Марк Цукерберг, Сэм Альтман из OpenAI и другие разработчики ИИ публично заявили, что они еще не достигли пределов традиционных законов масштабирования и все еще разрабатывают дорогие центры обработки данных для повышения производительности предварительно обученных моделей.

▲Сэм Альтман (Источник: Vanity Fair)
Питер Велиндер, вице-президент по продуктам OpenAI, также заявил в социальных сетях, что «люди недооценивают возможности компьютеров во время тестирования ».
Вычисление во время тестирования (TTC) — это концепция машинного обучения, которая относится к вычислениям, выполняемым при выводе или прогнозировании новых входных данных после развертывания модели. Это отделено от вычислений на этапе обучения модели, где модель изучает закономерности в данных и делает прогнозы.
В традиционных моделях машинного обучения после обучения и развертывания модели обычно не требуется дополнительных вычислений для прогнозирования новых экземпляров данных. Однако в некоторых более сложных моделях, таких как определенные типы моделей глубокого обучения, во время тестирования (т. е. во время вывода) могут потребоваться дополнительные вычисления.
Например, модель «o1», разработанная OpenAI, использует эту модель рассуждения. Фактически, вся индустрия искусственного интеллекта переключает свое внимание на модели, которые улучшают модели после первоначального обучения .

▲Питер Велиндер (Источник: Dagens industri)
В связи с этим Илья Суцкевер, один из сооснователей OpenAI, в недавнем интервью агентству Reuters признал, что с помощью больших объемов неразмеченных данных для обучения моделей искусственного интеллекта пониманию языковых моделей и структур на этапе предварительного обучения улучшение эффекта стабилизировалось .
«2010-е годы были эпохой расширения, а сейчас мы вернулись в эпоху исследований и открытий», — сказал Илья, отметив, что « масштабирование до правильного масштаба важнее, чем когда-либо».
Ожидается, что Орион будет запущен в 2025 году. OpenAI назвала его «Орион» вместо «GPT-5», что может намекать на новую революцию. Хотя временно «трудно родить» из-за теоретических ограничений, мы все еще с нетерпением ждем этого «новорожденного» с новым именем, которое может принести новые возможности большой модели ИИ.
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo