Никто точно не знает, как работает динамическое кэширование M3, но у меня есть теория.

Во время мероприятия Apple «Scary Fast» мое внимание привлекла одна особенность, не похожая ни на что другое: динамическое кэширование. Вероятно, как и у большинства людей, смотрящих презентацию, у меня была одна реакция: «Как распределение памяти повышает производительность?»
В основу своего дебюта нового чипа M3 Apple положила «краеугольный камень» функции, которую она называет динамическим кэшированием для графического процессора. Упрощенное объяснение Apple не дает ясного представления о том, что именно делает динамическое кэширование, а тем более о том, как оно повышает производительность графического процессора на M3.
Я углубился в типичные архитектуры графических процессоров и задал несколько прямых вопросов, чтобы выяснить, что такое динамическое кэширование. Вот мое лучшее понимание того, что, несомненно, является самой технически сложной функцией, которую Apple когда-либо предлагала бренду.
Что такое динамическое кэширование?

Динамическое кэширование — это функция, которая позволяет чипам M3 использовать только тот объем памяти, который необходим для конкретной задачи. Вот как Apple описывает это в официальном пресс-релизе: «Динамическое кэширование, в отличие от традиционных графических процессоров, распределяет использование локальной памяти оборудования в реальном времени. При динамическом кэшировании для каждой задачи используется только тот объем памяти, который необходим. Это первая в отрасли технология, прозрачная для разработчиков и являющаяся краеугольным камнем новой архитектуры графического процессора. Это значительно увеличивает среднюю загрузку графического процессора, что значительно повышает производительность самых требовательных профессиональных приложений и игр».
В типичной для Apple манере многие технические аспекты намеренно скрыты, чтобы сосредоточиться на результате. Там достаточно, чтобы уловить суть, не раскрывая секретный соус и не сбивая аудиторию с толку техническим жаргоном. Но общий вывод, похоже, заключается в том, что динамическое кэширование позволяет графическому процессору более эффективно распределять память. Достаточно просто, не так ли? Что ж, до сих пор не совсем понятно, каким образом распределение памяти «увеличивает среднее использование» или «значительно повышает производительность».
Чтобы даже попытаться понять динамическое кэширование, нам придется сделать шаг назад и изучить, как работают графические процессоры. В отличие от процессоров, графические процессоры превосходно справляются с массовыми рабочими нагрузками параллельно. Эти рабочие нагрузки называются шейдерами и представляют собой программы, выполняемые графическим процессором. Чтобы эффективно использовать графический процессор, программам необходимо одновременно выполнять массу шейдеров. Вы хотите использовать как можно больше доступных ядер.
Это приводит к эффекту , который Nvidia называет «хвостом». Загрузка шейдеров выполняется одновременно, а затем наблюдается спад использования, в то время как все больше шейдеров отправляются на выполнение в потоках (или, точнее, в блоках потоков на графическом процессоре). Этот эффект был отражен в презентации Apple, когда она объясняла динамическое кэширование, поскольку загрузка графического процессора резко возросла, прежде чем достичь нижнего предела.
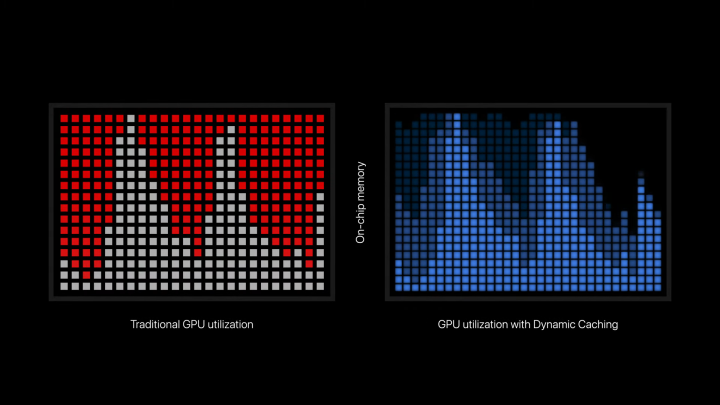
Как это влияет на память? Функции вашего графического процессора считывают инструкции из памяти и записывают выходные данные функции в память. Многим функциям также потребуется несколько раз обращаться к памяти во время выполнения. В отличие от процессора, где задержка памяти через ОЗУ и кэш чрезвычайно важна из-за низкого уровня параллельных функций, задержку памяти на графическом процессоре легче скрыть. Это процессоры с высокой степенью параллельности, поэтому, если некоторые функции копаются в памяти, другие могут выполняться.
Это работает, когда все шейдеры легко выполнить, но требовательные рабочие нагрузки будут иметь очень сложные шейдеры. Когда запланировано выполнение этих шейдеров, будет выделена память, необходимая для их выполнения, даже если она не нужна. Графический процессор распределяет множество своих ресурсов на одну сложную задачу, даже если эти ресурсы пропадут зря. Похоже, что динамическое кэширование — это попытка Apple более эффективно использовать ресурсы, доступные графическому процессору, гарантируя, что для выполнения сложных задач потребуется только то, что им нужно.
Теоретически это должно увеличить среднее использование графического процессора, позволяя выполнять больше задач одновременно, вместо того, чтобы меньший набор ресурсоемких задач поглощал все ресурсы, доступные графическому процессору. Объяснение Apple в первую очередь фокусируется на памяти, создавая впечатление, что само по себе распределение памяти увеличивает производительность. Насколько я понимаю, эффективное распределение позволяет одновременно выполнять больше шейдеров, что затем приведет к увеличению использования и производительности.
Использовано и выделено
Одним из важных аспектов, который является ключом к пониманию моей попытки объяснить динамическое кэширование, является то, как ветвятся шейдеры. Программы, которые выполняет ваш графический процессор, не всегда статичны. Они могут меняться в зависимости от разных условий, что особенно актуально для больших и сложных шейдеров, подобных тем, которые необходимы для трассировки лучей. Этим условным шейдерам необходимо выделять ресурсы для наихудшего сценария, а это означает, что некоторые ресурсы могут быть потрачены впустую.
Вот как Unity объясняет шейдеры с динамическим ветвлением в своей документации: «Для любого типа динамического ветвления графический процессор должен выделить пространство регистров для наихудшего случая. Если одна ветвь намного дороже другой, это означает, что графический процессор тратит впустую регистровое пространство. Это может привести к меньшему количеству параллельных вызовов шейдерной программы, что снижает производительность».
Похоже, что Apple нацелена на этот тип ветвления с помощью динамического кэширования, позволяя графическому процессору использовать только те ресурсы, которые ему необходимы, а не тратить их впустую. Вполне возможно, что эта функция может иметь значение где-то еще, но неясно, где и когда динамическое кэширование сработает, пока графический процессор выполняет свои задачи.
Все еще черный ящик

Конечно, я должен отметить, что все это всего лишь мое понимание, основанное на традиционном функционировании графических процессоров и официальных заявлениях Apple. Apple может со временем опубликовать дополнительную информацию о том, как все это работает, но в конечном итоге технические детали динамического кэширования не имеют значения, если Apple действительно способна улучшить использование и производительность графического процессора.
В конце концов, динамическое кэширование — это коммерческий термин, обозначающий функцию, которая глубоко заложена в архитектуру графического процессора. Попытка понять это, не будучи разработчиком графических процессоров, неизбежно приведет к заблуждениям и упрощенным объяснениям. Теоретически Apple могла бы просто отказаться от брендинга и позволить архитектуре говорить самой за себя.
Если вы искали более глубокий взгляд на то, что может делать динамическое кэширование в графическом процессоре M3, теперь у вас есть возможное объяснение. Однако важно то, как работает конечный продукт, и нам не придется долго ждать, пока первые устройства Apple M3 станут доступны публике, чтобы мы все могли это узнать. Но, судя по заявленным характеристикам и демонстрациям, которые мы видели до сих пор, он, безусловно, выглядит многообещающе.