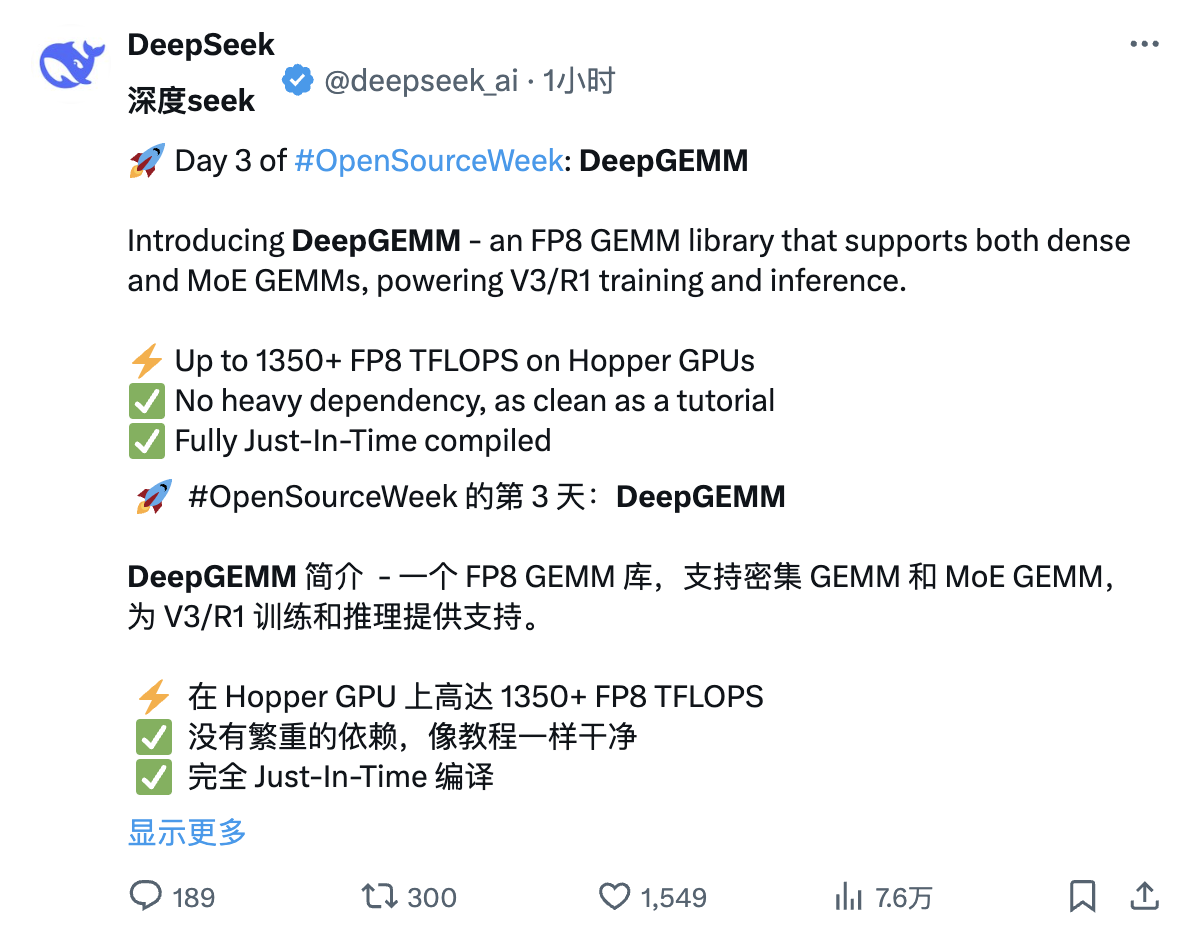
Познакомьтесь с третьей частью проекта с открытым исходным кодом DeepSeek в одной статье. 300 строк кода раскрывают ключ к эффективности вывода V3/R1.

В третий день Недели открытого исходного кода DeepSeek не только представил технологию, но и распространил хорошие новости о том, что R2 уже в пути. Для пользователя видеть библиотеки технологий, выброшенные DeepSeek, и модели, в которых применяются эти технологии, — это не способ стать свидетелем рождения суперзвезды.
Сегодня мы представляем DeepGEMM, библиотеку, предназначенную для чистого и эффективного общего матричного умножения (GEMM) FP8 с возможностями детального масштабирования, как описано в DeepSeek-V3. Он поддерживает обычные и смешанные экспертные (MoE) группы GEMM. Библиотека написана на CUDA и не требует компиляции во время установки. Вместо этого она использует облегченные JIT-модули для компиляции всех ядер во время выполнения.
Я не хочу сказать, что DeepSeek не является мощным инструментом, но из открытого исходного кода за последние три дня видно, что даже если они поддерживаются Magic Square, они не так богаты ресурсами, как крупные компании, и им приходится усердно работать, чтобы сжимать вычислительные ресурсы.
В том числе и в этот раз GeepGEMM по-прежнему не оставляет эту тему. По сравнению с предыдущими технологиями преимуществами DeepGEMM являются:
- Более высокая эффективность: снижение затрат на вычисления и использование памяти за счет FP8 и двухуровневого накопления.
- Гибкое развертывание: JIT-компиляция легко адаптируется и снижает нагрузку на предварительную компиляцию.
- Целевая оптимизация: поддержка MoE и глубокая адаптация к тензорному ядру Хоппера.
- Более простой дизайн: меньше основного кода, избегаются сложные зависимости, легко изучать и оптимизировать.
Эти функции выделяют его среди современных вычислений с искусственным интеллектом, особенно в сценариях, требующих эффективного вывода и низкого энергопотребления .
Создан для современных вычислений с искусственным интеллектом
Более высокая эффективность и более гибкое развертывание — вот основные преимущества DeepGEMM. Базовая логика состоит всего из около 300 строк кода, но она превосходит ядро, настроенное на экспертном уровне, в большинстве размеров матриц. До 1350+ FP8 терафлопс на графических процессорах Hopper.
FP8 — это метод сжатия чисел, который эквивалентен уменьшению чисел, которые изначально требуют 32-битной или 16-битной памяти, в 8-битную память. Точно так же, как вы делаете заметки с помощью стикеров меньшего размера, хотя на каждом листе бумаги можно написать меньше контента, его легче переносить и передавать .
Преимущество этого сжатого расчета в том, что он занимает меньше памяти — задача того же размера требует меньше «записок», а перемещение небольших листов бумаги происходит быстрее, чем больших файлов, поэтому скорость расчета также выше. Но проблема в том, что легко совершать ошибки.
Чтобы решить проблему точности FP8, DeepGEMM использует умный «двухэтапный метод»: использует FP8 для выполнения крупномасштабных умножений, например, с помощью калькулятора для быстрого получения серии результатов. На этом этапе ошибки неизбежны.
Но это не беда, есть второй шаг: высокоточная агрегация. Время от времени эти результаты преобразуются в более точную 32-значную сумму, которую тщательно сверяют с помощью черновой бумаги, чтобы избежать накопления ошибок.
Сначала выполните запуск, а затем пройдите два уровня совокупной проверки ошибок. Благодаря такой конструкции DeepGEMM позволяет моделям искусственного интеллекта более плавно работать на мобильных телефонах, компьютерах и других устройствах, одновременно снижая энергопотребление, что делает их пригодными для более сложных сценариев применения в будущем .

Включая применение JIT-компиляции, это аналогичная идея. JIT-компиляция, полное название — компиляция «точно в срок». На китайском языке ее можно назвать компиляцией «точно в срок», а соответствующая концепция — статическая компиляция.
Обычная программа должна быть написана и скомпилирована перед ее использованием и преобразована в язык, понятный компьютеру. Но JIT-компиляция — это другое дело. Она лишь превращает код в инструкции, которые компьютер может выполнять во время работы программы.
Он может корректировать код на месте в соответствии с условиями вашего компьютера (например, видеокарты NVIDIA Hopper) и адаптировать наиболее подходящие инструкции. Это не так жестко, как предварительная компиляция, поэтому программа может работать более плавно. Соберите только те части, которые вам нужны в данный момент, не теряя времени и места, и сделайте все правильно.
Тензорное ядро Хоппера и JIT-компиляция — лучшие партнеры. JIT-компиляция может генерировать оптимальный код на месте на основе вашей видеокарты Hopper во время выполнения, максимизируя эффективность вычислений тензорного ядра.
DeepGEMM поддерживает обычные GEMM и смешанные экспертные (MoE) GEMM, которые имеют разные вычислительные требования. JIT-компиляция может временно корректировать код в соответствии с характеристиками задачи и напрямую мобилизовать функцию вычисления FP8 или механизма преобразования тензорного ядра, чтобы уменьшить потери и увеличить скорость.
Как описать такой техничный маршрут: тонкий, легкий и острый .
Для большинства разработчиков DeepGEMM можно назвать еще одной хорошей новостью. Ниже представлена информация, относящаяся к развертыванию. Возможно, вы захотите с ней поиграть.
Руководство по развертыванию DeepGEMM
DeepGEMM — это библиотека, оптимизированная для общего умножения матриц (GEMM) FP8 с усовершенствованным механизмом масштабирования и предложенная в DeepSeek-V3. Он поддерживает стандартные GEMM и смешанные экспертные (MoE) группы GEMM. Библиотека написана на CUDA и не требует предварительной компиляции во время установки. Вместо этого все основные функции компилируются во время выполнения с помощью облегченного модуля JIT-компиляции.
В настоящее время DeepGEMM поддерживает только тензорные ядра NVIDIA Hopper. Для решения проблемы недостаточной точности вычислений тензорного ядра FP8 для оптимизации используется технология двухуровневого накопления (бустинга) ядра CUDA. Несмотря на то, что DeepGEMM заимствует некоторые концепции из CUTLASS и CuTe, он не слишком полагается на их шаблоны или математические операции. Вместо этого он стремится к простоте и содержит только одну основную функцию вычислительного ядра с примерно 300 строками кода. Это делает DeepGEMM понятным и простым для понимания справочным ресурсом для изучения методов умножения и оптимизации матриц Hopper FP8.
Несмотря на простоту конструкции, производительность DeepGEMM при работе с различными формами матриц сравнима, а в некоторых случаях даже лучше, чем у профессионально оптимизированных библиотек.
производительность
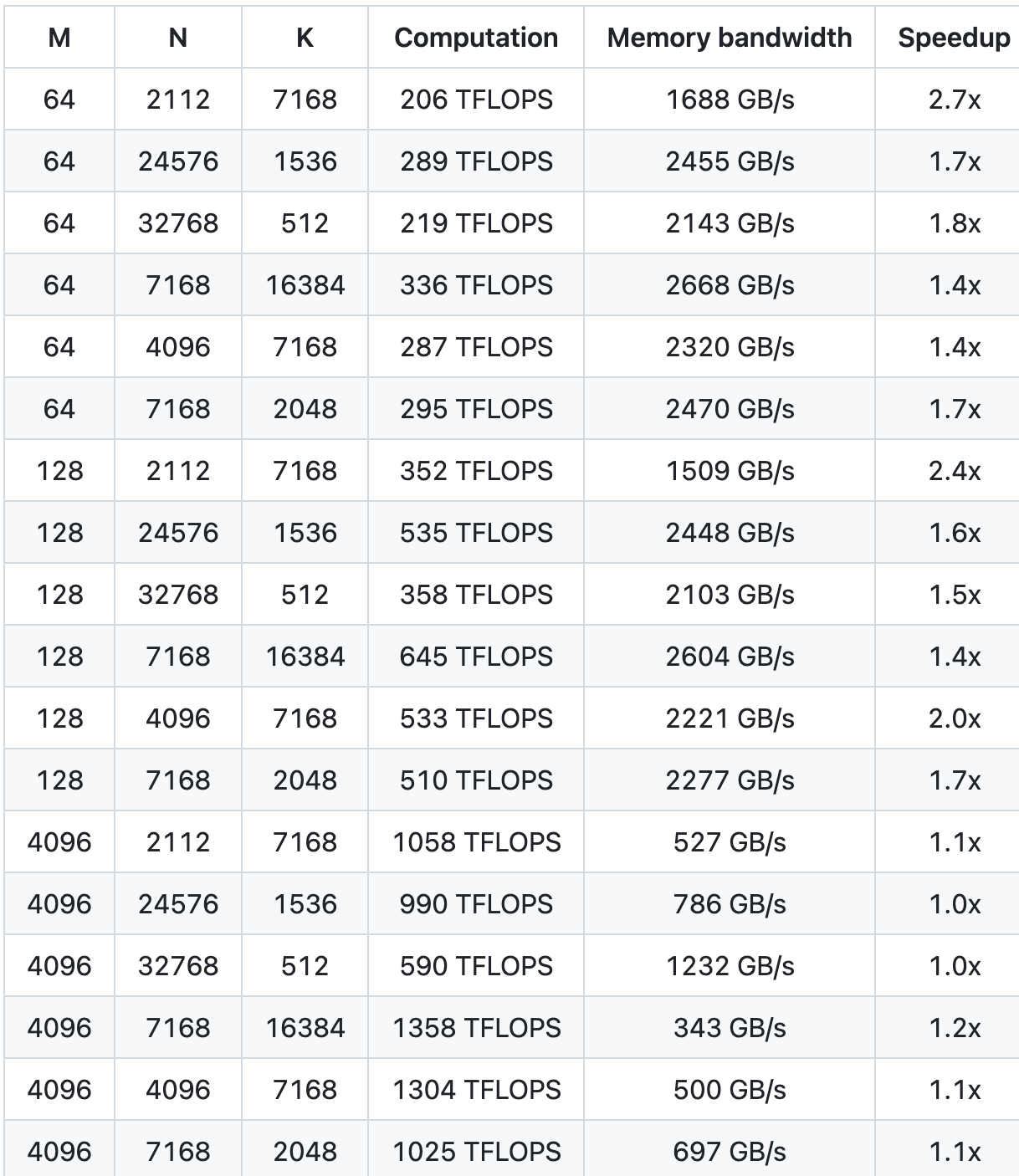
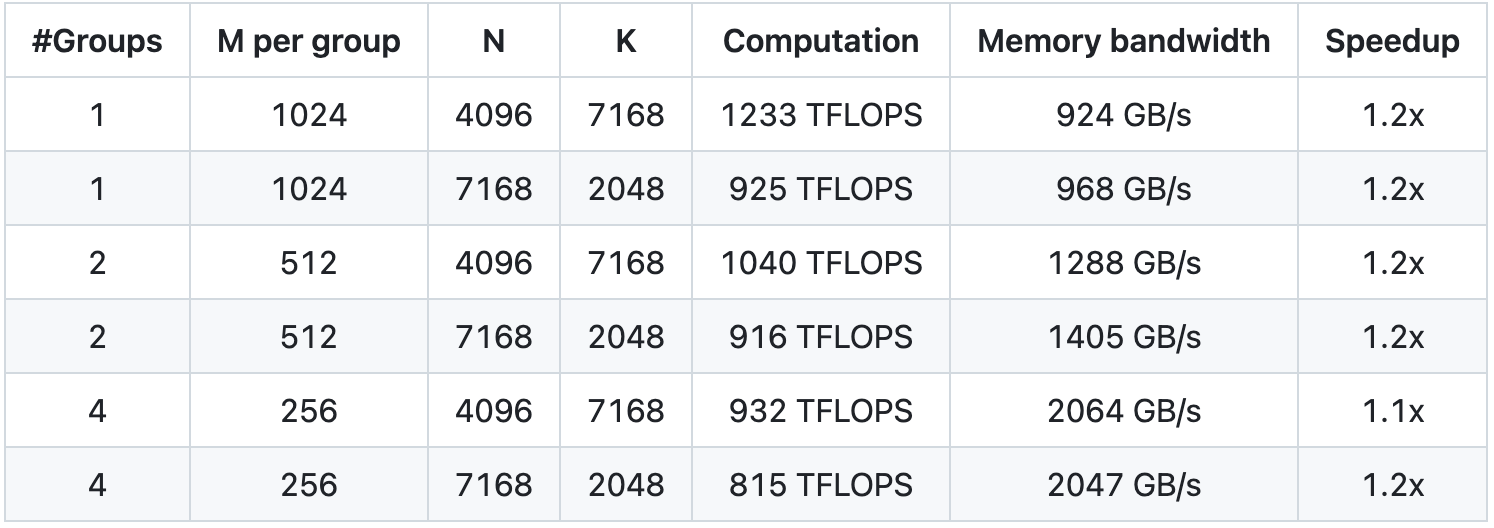
Мы тестировали NVCC 12.8 на H800, охватывая все формы матриц, которые могут использоваться во время вывода DeepSeek-V3/R1 (включая предварительное заполнение и декодирование, но не включая тензорный параллелизм). Все показатели ускорения рассчитываются на основе тщательно оптимизированной внутренней реализации CUTLASS 3.6.
Производительность DeepGEMM при некоторых конкретных формах матриц не идеальна. Если вы заинтересованы в оптимизации, вы можете отправить запросы на оптимизацию.
Стандартный GEMM для плотных моделей
Сгруппированные GEMM для модели МО (непрерывная компоновка)
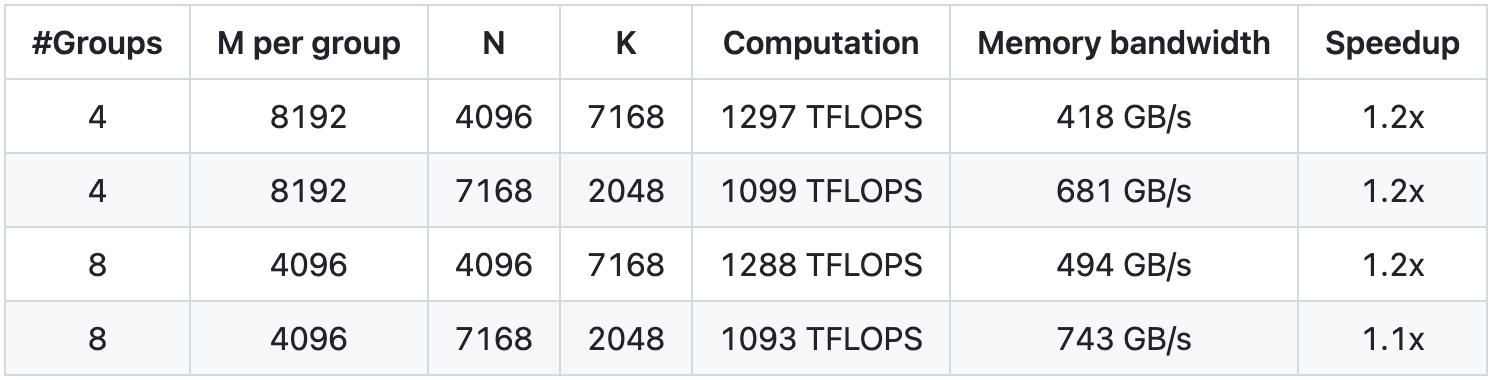
Сгруппированная GEMM (макет маски) для модели МО
быстрый старт
Экологические требования
- Графический процессор с архитектурой Hopper, должен поддерживать sm_90a
- Питон 3.8 и выше
- CUDA версии 12.3 и выше (для лучшей производительности настоятельно рекомендуется использовать версию 12.8 и выше)
- PyTorch 2.1 и выше
- CUTLASS 3.6 и выше (можно клонировать через подмодуль Git)
развивать
# Субмодуль необходимо клонировать
git clone –recursive [email protected]:deepseek-ai/DeepGEMM.git# Сделать символические ссылки для сторонних (CUTLASS и CuTe) включающими каталоги
разработка python setup.py# Тестовая JIT-компиляция
тесты Python/test_jit.py# Проверьте все орудия GEMM (обычные, сгруппированные смежно и сгруппированные по маске)
тесты Python/test_core.py
Установить
установка python setup.py
Затем импортируйте deep_gemm в свой проект Python и наслаждайтесь его использованием!
Прикреплен адрес открытого исходного кода GitHub:
https://github.com/deepseek-ai/DeepGEMM
Автор: Лю Я, Мо Чунюй
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo