Самая мощная большая модель с открытым исходным кодом взрывается поздно ночью! Llama 3 Return of the King, почти не хуже GPT-4, Маску нравится Прикрепленная ссылка на опыт |
Без особых сюрпризов Meta «взорвала улицы» серией моделей Llama 3, которые известны как «самые мощные большие модели с открытым исходным кодом в истории».
В частности, Meta выложила в открытый доступ две модели разных размеров: 8B и 70B.
- Llama 3 8B: По мощности не уступает самой большой Llama 2 70B.
- Llama 3 70B: Модель AI первого уровня, сравнимая с Gemini 1.5 Pro, превосходящая Claude Big Cup по всем аспектам.
Вышеупомянутое — всего лишь закуски Меты, настоящая еда еще впереди. В ближайшие несколько месяцев Meta последовательно запустит серию новых моделей с мультимодальным, многоязычным диалогом, более длинными контекстными окнами и другими возможностями. Ожидается, что среди них игрок-тяжеловес с рейтингом более 400B будет соревноваться с Claude 3 Super Cup. .
Адрес опыта Ламы 3: https://llama.meta.com/llama3/

Еще одна модель уровня GPT-4 здесь, Лама 3 открыта
По сравнению с предыдущей моделью Llama 2, Llama 3, можно сказать, вышла на новый уровень.
Благодаря улучшениям в предварительном обучении и после обучения, модели точной настройки перед обучением и инструкциями, выпущенные на этот раз, являются на сегодняшний день самыми мощными моделями в шкалах параметров 8B и 70B. В то же время происходит оптимизация пост-обучения. -Процесс обучения значительно снизил частоту ошибок модели, повысил ее согласованность и обогатил разнообразие ответов.
Цукерберг однажды заявил в публичном выступлении, что, учитывая, что пользователи не будут задавать вопросы, связанные с кодированием Meta AI в WhatsApp, оптимизация Llama 2 в этой области не является выдающейся.
На этот раз в Llama 3 были достигнуты революционные улучшения в рассуждениях, генерации кода и выполнении инструкций, что сделало ее более гибкой и простой в использовании.
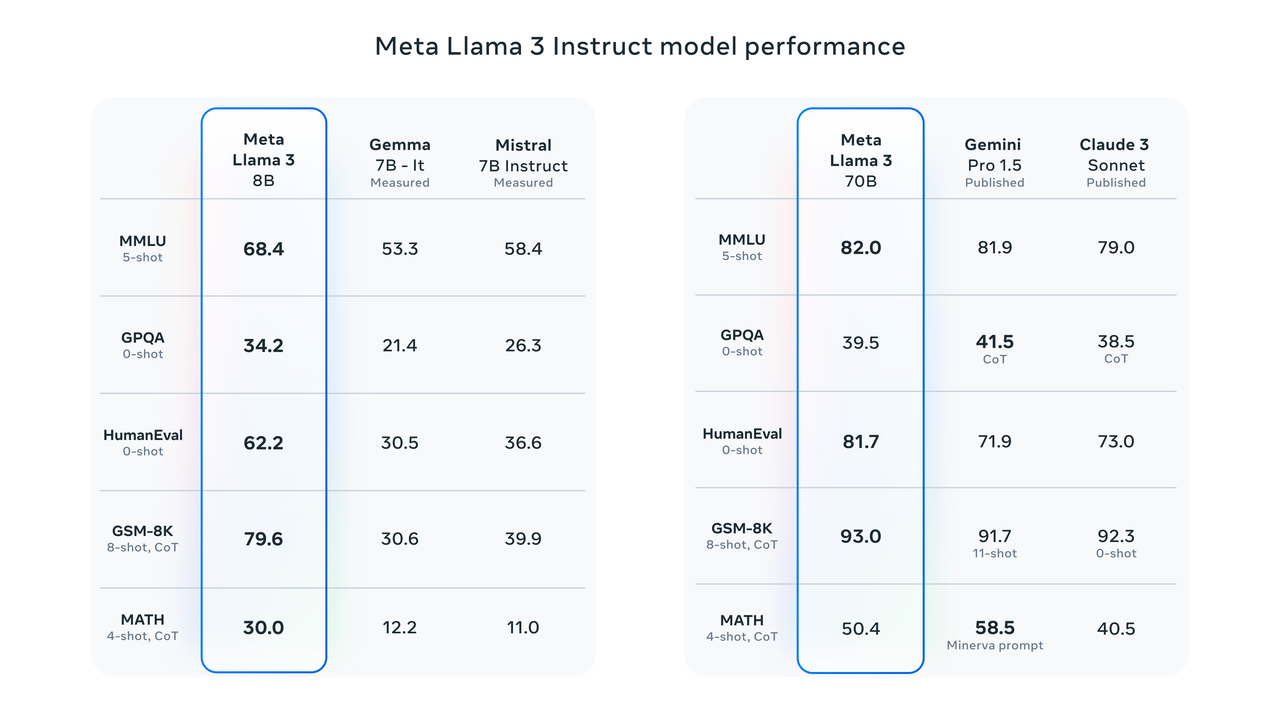
Результаты тестов показывают, что Llama 3 8B набирает гораздо более высокие баллы, чем Google Gemma 7B и Mistral 7B Instruct в MMLU, GPQA, HumanEval и других тестах. По словам Цукерберга, самая маленькая Лама 3 по сути такая же мощная, как и самая большая Лама 2.
Llama 3 70B входит в число лучших моделей AI. Его общая производительность лучше, чем у Claude 3. По сравнению с Gemini 1.5 Pro они равны.
Чтобы точно изучить производительность модели в соответствии с критериями, Meta также разработала новый высококачественный набор данных для оценки человеком.
Набор для оценивания содержит 1800 подсказок, охватывающих 12 ключевых случаев использования: обращение за советом, мозговой штурм, категоризация, закрытые вопросы и ответы, кодирование, творческое письмо, извлечение, персона, открытые вопросы и ответы, рассуждение, переписывание и подведение итогов.

Чтобы предотвратить переобучение Llama 3 в этом оценочном наборе, Meta даже запретила своей исследовательской группе доступ к этому набору данных. В соревновании один на один с Claude Sonnet, Mistral Medium и GPT-3.5 Meta Llama 70B завершила соревнование «ошеломляющей победой».
Согласно официальному представлению Meta, Llama 3 выбрала в своей архитектуре модели относительно стандартную архитектуру чистого декодера Transformer. По сравнению с Llama 2, Llama 3 имеет несколько ключевых улучшений:
- Llama 3 использует токенизатор со словарем токенов в 128 тыс. для более эффективного кодирования языка, что значительно повышает производительность модели.
- Групповое внимание к запросам (GQA) используется как в моделях 8B, так и в 70B для повышения эффективности вывода модели Llama 3.
- Модель обучается на последовательностях из 8192 токенов с использованием масок, чтобы гарантировать, что самообслуживание не выходит за границы документа.
Количество и качество обучающих данных являются ключевыми факторами, способствующими появлению возможностей крупных моделей на следующем этапе.
С самого начала Meta Llama 3 задумывалась как самая мощная модель. Meta вкладывает значительные средства в данные перед обучением. Сообщается, что Llama 3 использует более 15T токенов, собранных из общедоступных источников, что в семь раз превышает набор данных, используемый Llama 2, а количество содержащихся в ней кодовых данных в четыре раза больше, чем у Llama 2.

Учитывая практическое применение многоязычности, более 5% набора данных для предварительного обучения Llama 3 состоит из высококачественных неанглоязычных данных, охватывающих более 30 языков. Однако представители Meta также признали, что по сравнению с английским, производительность выше. Ожидается, что из этих языков он будет немного хуже.
Чтобы обеспечить обучение Llama 3 на данных высочайшего качества, исследовательская группа Meta даже заранее использует эвристические фильтры, фильтры NSFW, методы семантической дедупликации и классификаторы текста для прогнозирования качества данных.
Стоит отметить, что исследовательская группа также обнаружила, что предыдущие поколения моделей Llama на удивление хорошо справлялись с идентификацией высококачественных данных, поэтому они позволили Llama 2 генерировать обучающие данные для классификатора качества текста, поддерживаемого Llama 3, по-настоящему реализуя «обучение ИИ ИИ». " .
Помимо качества обучения, Llama 3 также совершила качественный скачок в эффективности тренировок.
Meta сообщила, что для обучения самой большой модели Llama 3 они объединили три типа распараллеливания: распараллеливание данных, распараллеливание моделей и распараллеливание конвейеров.
При одновременном обучении на 16 000 графических процессорах можно достичь загрузки более 400 терафлопс вычислений на каждый графический процессор. Исследовательская группа провела обучение на двух специально созданных кластерах графических процессоров 24 КБ.

Чтобы максимально увеличить время безотказной работы графического процессора, исследовательская группа разработала новый усовершенствованный стек обучения, который автоматизирует обнаружение, обработку и обслуживание ошибок. Кроме того, Meta значительно повысила надежность оборудования и механизмы бесшумного обнаружения повреждения данных, а также разработала новую масштабируемую систему хранения, позволяющую снизить затраты на контрольные точки и откаты.
Благодаря этим улучшениям общее эффективное время тренировки превышает 95%, а также эффективность тренировки Llama 3 примерно в три раза выше, чем у предыдущего поколения.
Для получения более подробной технической информации посетите официальный блог Meta: https://ai.meta.com/blog/meta-llama-3/.
Открытый исходный код против закрытого исходного кода
Будучи «сыном» Меты, Llama 3 естественным образом интегрирован в чат-бота с искусственным интеллектом Meta AI.
Еще на прошлогодней конференции Meta Connect 2023 Цукерберг официально объявил о запуске Meta AI на встрече, а затем быстро продвинул его в США, Австралии, Канаде, Сингапуре, Южной Африке и других регионах.
В предыдущих интервью Цукерберг был еще более уверен в Meta AI, оснащенном Llama 3, заявив, что это будет самый умный AI-помощник, которым люди смогут пользоваться бесплатно.
Я думаю, что это перейдет от формата, подобного чат-боту, к формату, в котором вы можете просто задать вопрос, и он даст вам ответ, и вы можете давать ему более сложные задачи, и он их выполнит.
Прилагается веб-адрес Meta AI: https://www.meta.ai/.

Конечно, если Meta AI «еще не доступен в вашей стране/регионе», вы можете использовать самый простой канал для использования модели с открытым исходным кодом — Hugging Face, крупнейший в мире веб-сайт сообщества искусственного интеллекта с открытым исходным кодом.
Прилагаем адрес опыта: https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct.
Perplexity, Poe и другие платформы также быстро объявили об интеграции Llama 3 в сервисы платформы.

Вы также можете испытать Llama 3, вызвав интерфейс API-интерфейса репликации платформы модели с открытым исходным кодом. Цена его использования также раскрыта, поэтому вы можете использовать его по требованию.
Интересно, что до того, как Meta официально анонсировала Llama 3, зоркие пользователи сети обнаружили, что рынок Microsoft Azure украл версию Llama 3 8B Instruct. Однако по мере дальнейшего распространения новостей, когда пользователи сети стекались, чтобы снова попытаться получить доступ к ссылке, все, что я получил, это. страница «404».
В настоящее время восстановлено: https://azuremarketplace.microsoft.com/en-us/marketplace/apps/metagenai.meta-llama-3-8b-chat-offer?tab=overview.
Появление «Ламы 3» вызывает новую бурю обсуждений в социальной платформе X.
Главный научный сотрудник Meta AI и обладатель премии Тьюринга Ян ЛеКун не только приветствовал выпуск Llama 3, но и еще раз предсказал, что в ближайшие несколько месяцев будут выпущены новые версии. Даже Маск появился в области комментариев и выразил свое признание и ожидания от «Ламы 3» кратким и неявным «Неплохо».
Джим Фан, старший научный сотрудник NVIDIA, сосредоточил свое внимание на предстоящей Llama 3 400B+. По его мнению, запуск Llama 3 оторвался от технологического прогресса и является символом модели с открытым исходным кодом и модели с закрытым исходным кодом. .
Из проведенного им эталонного теста видно, что сила Llama 3 400B+ практически сопоставима с Claude Extra Large Cup и новой версией GPT-4 Turbo. Хотя определенный разрыв все еще существует, его достаточно, чтобы доказать. что ему принадлежит место среди лучших больших моделей.

Сегодня день рождения Эндрю Нг, профессора Стэнфордского университета и ведущего эксперта в области искусственного интеллекта. Прибытие Llama 3, несомненно, станет самым особенным способом отпраздновать его день рождения.
Надо сказать, что сегодняшняя модель с открытым исходным кодом действительно позволяет расцвести сотне цветов и соперничать между собой сотнями школ мысли.
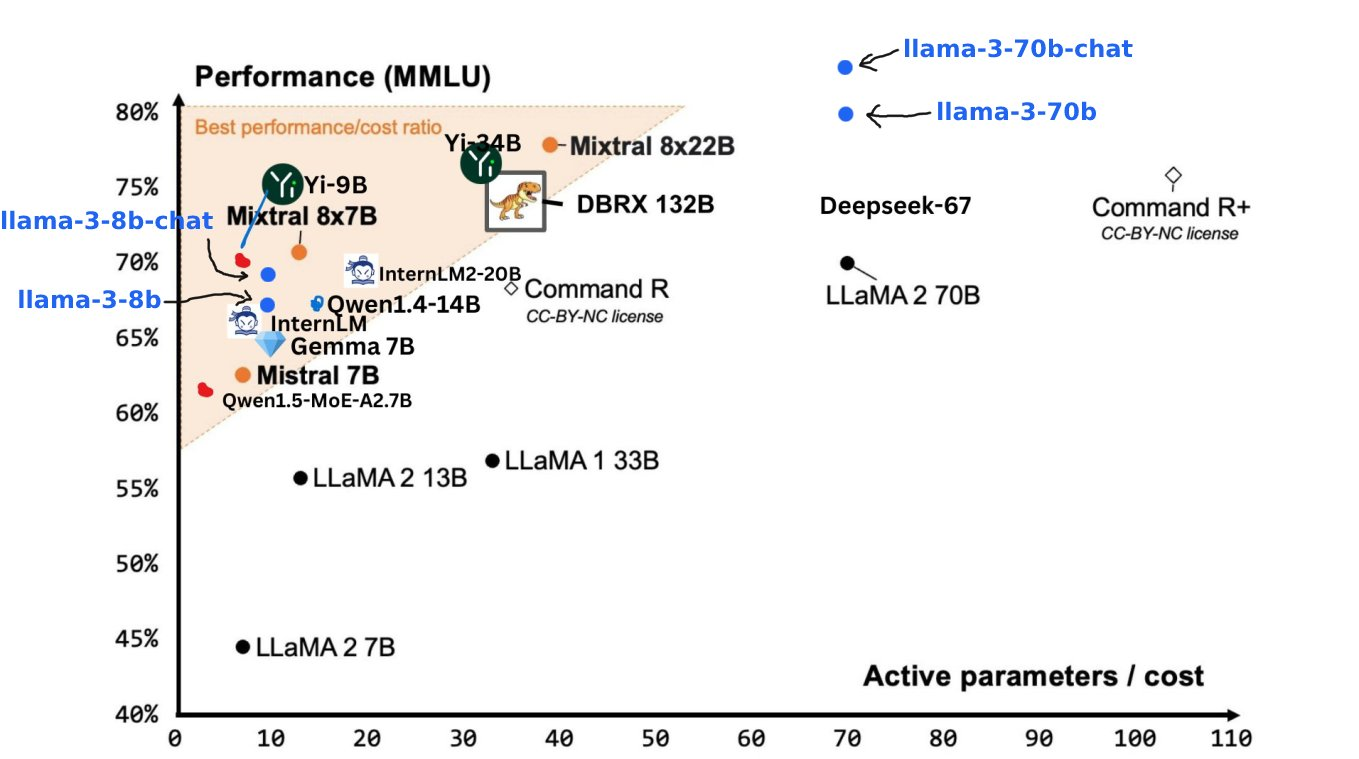
В начале этого года Цукерберг, у которого на руках 350 000 графических процессоров, твердым тоном описал видение Meta в интервью The Verge — стремление создать AGI (искусственный общий интеллект).
В отличие от OpenAI, который не является открытым, Meta начала борьбу за Святой Грааль AGI по пути открытого исходного кода.
Как сказал Цукерберг, Meta, исходный код которой полностью открыт, не добилась ничего на этом сложном пути:
Я вообще склонен думать, что открытый исходный код полезен для сообщества и для нас, потому что мы извлекаем выгоду из инноваций.
В прошлом году весь круг ИИ бесконечно спорил вокруг пути с открытым или закрытым исходным кодом. Эти дебаты вышли за рамки сравнения преимуществ и недостатков на техническом уровне и затронули основное направление будущего развития ИИ. Даже Маск, который выступил лично, изменил мир, выпустив Grok 1.0 с открытым исходным кодом.
Не так давно некоторые мнения говорили, что модель с открытым исходным кодом станет все более отсталой. Теперь появление Llama 3 также дало этому пессимистическому мнению оглушительную пощечину.
Однако, хотя Llama 3 вносит некоторое облегчение в модель с открытым исходным кодом, дебаты об открытом и закрытом исходном коде еще далеки от завершения.
В конце концов, GPT-4.5/5, который тайно готовится к запуску, может положить конец этой затянувшейся дискуссии, продемонстрировав непревзойденные результаты этим летом.
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo