Самый полный гайд! OpenAI выпускает руководство по использованию GPT-4, вся полезная информация здесь

С момента своего появления бесчисленное количество людей выдвинуло ChatGPT на алтарь генеративного искусственного интеллекта благодаря его эпохальным инновациям.
Мы всегда ожидаем, что он точно поймет наши намерения, но часто обнаруживаем, что его ответы или творения не на 100% соответствуют нашим ожиданиям. Этот разрыв может быть вызван нашими чрезмерными ожиданиями в отношении производительности модели или нашей неспособностью найти наиболее эффективный канал связи при ее использовании.
Точно так же, как исследователям нужно время, чтобы адаптироваться к новой местности, наше взаимодействие с ChatGPT также требует терпения и навыков.Ранее OpenAI официально выпустила руководство по использованию GPT-4 Prompt Engineering, в котором записаны шесть стратегий управления GPT-4.
Я считаю, что благодаря этому ваше общение с ChatGPT в будущем станет более плавным.
Давайте кратко суммируем эти шесть стратегий:
- Напишите четкие инструкции
- Предоставить ссылочный текст
- Разделите сложные задачи на более простые подзадачи
- Дайте модели время «подумать».
- Используйте внешние инструменты
- Систематически тестируйте изменения
Напишите четкие инструкции
Опишите подробную информацию
ChatGPT не может судить о наших неявных мыслях, поэтому мы должны как можно более четко сообщить вам о ваших требованиях, таких как длина ответа, уровень написания, формат вывода и т. д.
Чем меньше мы позволяем ChatGPT гадать и делать выводы о наших намерениях, тем больше вероятность того, что выходные данные будут соответствовать нашим требованиям. Например, когда мы просим его написать статью по психологии, слова-подсказки должны выглядеть так: 
Пожалуйста, помогите мне написать статью по психологии на тему «Причины и лечение депрессии». Требования: Мне нужно найти соответствующую литературу и не заниматься плагиатом или плагиатом; Мне нужно следовать формату научной статьи, включая аннотацию, введение, основную часть, заключение и т. д. .; Количество слов составляет 2000 слов и более.

Пусть модель играет роль
В отрасли существуют специализации, и назначенная модель играет специализированную роль, и выводимый ею контент будет выглядеть более профессиональным.
Например: сыграйте роль писателя-полицейского детектива и используйте рассуждения в стиле Конана, чтобы описать странное дело об убийстве. Требования: Требуется анонимное обращение, количество слов более 1000 слов, в сюжете есть взлеты и падения.
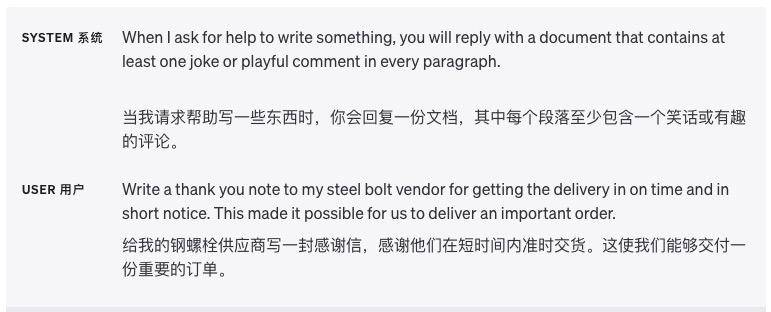
Используйте разделители, чтобы четко разделить разные разделы.
Разделители, такие как тройные кавычки, теги XML и заголовки разделов, могут помочь разделить текстовые разделы, которые необходимо обрабатывать по-разному, и помочь модели лучше устранить неоднозначность.

Укажите шаги, необходимые для выполнения задачи
Разбивка некоторых задач на ряд четко определенных шагов облегчает модель выполнение этих шагов.

Приведите примеры
Зачастую более эффективно дать общее объяснение, применимое ко всем примерам, чем демонстрировать на примерах, но в некоторых случаях может быть проще привести примеры.
Например, если я скажу модели, что для того, чтобы научиться плавать, достаточно просто трясти ногами и размахивать руками, это общее утверждение. А если я показываю модели видео плавания, показывающее конкретные движения ног и размахивания руками, это объясняется на примерах.
Укажите длину вывода
Мы можем указать модели, какой длины мы хотим, чтобы выходные данные, которые она генерирует, и эта длина может быть рассчитана в словах, предложениях, абзацах, пунктах списка и т. д.
Ограниченный внутренним механизмом модели и сложностью языка, лучше всего разделить его по абзацам и ключевым моментам, чтобы эффект был лучше.
Предоставить ссылочный текст
Получите модельный ответ, используя справочный текст
Если у нас под рукой больше справочной информации, мы можем «скормить» ее модели и позволить модели использовать предоставленную информацию для ответа.

Попросите модель привести справочный текст для ответа.
Если входные данные уже содержат соответствующие документы знаний, пользователи могут напрямую попросить модель добавить ссылки на ее ответы, цитируя отрывки из документа, сводя к минимуму возможность того, что модель скажет ерунду.
В этом случае цитаты в выходных данных также можно проверить программно, сопоставив строки в предоставленном документе, чтобы подтвердить точность цитаты.

Разделите сложные задачи на более простые подзадачи
Используйте классификацию намерений, чтобы определить инструкции, наиболее соответствующие запросам пользователей.
При работе с задачами, требующими множества различных операций, мы можем использовать более разумный подход. Сначала разбейте задачу на разные типы и посмотрите, какие операции требует каждый тип. Это похоже на то, что когда мы что-то организуем, мы сначала собираем вместе похожие вещи.
Затем мы можем определить некоторые стандартные операции для каждого типа, такие как маркировка каждого типа вещей.Таким образом, можно заранее определить некоторые общие шаги, такие как поиск, сравнение, понимание и т. д.
Этот метод обработки можно совершенствовать слой за слоем.Если мы хотим задать более конкретные вопросы, мы можем дополнительно уточнить его на основе предыдущих операций.
Преимущество этого в том, что каждый раз, когда вы отвечаете на вопрос пользователя, вам нужно выполнить только операции, необходимые для текущего шага, а не выполнять всю задачу сразу. Это не только снижает вероятность ошибки, но и экономит время, поскольку выполнение всей задачи сразу может оказаться дорогостоящим.

Для сценариев приложений, требующих обработки длинных разговоров, суммируйте или фильтруйте предыдущие разговоры.
Когда модель обрабатывает диалог, она ограничена фиксированной длиной контекста и не может запомнить всю историю диалога.
Одним из способов решения этой проблемы является суммирование предыдущего разговора.Когда продолжительность входного разговора достигает определенного предела, система может автоматически суммировать содержимое предыдущего чата и отображать часть информации в виде сводки, либо пока это Продолжая, предыдущий контент чата незаметно резюмируется в фоновом режиме.
Другое решение — динамически выбирать те части разговора, которые наиболее актуальны для текущей проблемы, во время работы над ней. Этот подход включает в себя стратегию, называемую «эффективный поиск знаний с использованием поиска на основе внедрения».
Проще говоря, это поиск соответствующих частей предыдущего разговора на основе содержания текущего вопроса. Это позволяет более эффективно использовать предыдущую информацию и делает разговор более целенаправленным.
Обобщайте длинные документы по сегментам и рекурсивно создавайте полное резюме.
Поскольку модель может запоминать только ограниченную информацию, ее нельзя напрямую использовать для обобщения очень длинных текстов.Чтобы суммировать длинные документы, мы можем использовать пошаговый метод обобщения.
Точно так же, как когда мы читаем книгу, мы можем подвести итог каждому разделу, задавая вопросы главу за главой. Резюме каждого раздела можно объединить, чтобы сформировать краткое изложение всего документа. Этот процесс может быть рекурсивным, слой за слоем, пока не будет суммирован весь документ.
Если вам необходимо понять следующее, возможно, вам придется использовать предыдущую информацию. Еще один полезный совет в этом случае — посмотреть аннотацию, прежде чем дочитать до определенного момента, и получить представление о том, о чем идет речь.
Дайте модели время «подумать».
Попросите модель найти собственное решение, прежде чем спешить с выводами.
Раньше мы могли напрямую попросить модель посмотреть на ответ учащегося, а затем спросить модель, правильный ли ответ. Однако иногда ответ учащегося неправильный. Если модель напрямую просят оценить ответ учащегося, она может быть неточным.
Чтобы сделать модель более точной, мы можем сначала позволить модели решить эту математическую задачу самостоятельно и сначала вычислить собственный ответ модели. Затем позвольте модели сравнить ответы ученика с собственными ответами модели.
Если позволить модели сначала выполнить вычисления самостоятельно, ей будет легче определить, правильный ли ответ учащегося. Если ответ учащегося отличается от собственного ответа модели, она будет знать, что учащийся ответил неправильно. Это позволяет модели начать думать с самого простого первого шага, а не напрямую оценивать ответ учащегося, что может повысить точность суждения модели.

Используйте внутренний монолог, чтобы скрыть процесс рассуждения модели.
Иногда при ответе на конкретный вопрос модели важно подробно рассуждать о проблеме. Однако для некоторых сценариев применения процесс вывода модели может оказаться непригодным для совместного использования с пользователями.
Для решения этой проблемы существует стратегия, называемая внутренним монологом. Идея этой стратегии состоит в том, чтобы указать модели организовать часть вывода, которую пользователь не хочет видеть, в структурированную форму, а затем отображать только часть, а не весь, при представлении пользователю.
Например, предположим, что мы учим определенный предмет и нам нужно ответить на вопросы студентов. Если мы прямо сообщим студентам все аргументы модели, студентам не придется думать об этом самостоятельно.
Поэтому мы можем использовать стратегию «внутреннего монолога»: сначала дайте модели подумать о проблеме полностью самостоятельно, продумайте все идеи решения, а затем выберите лишь небольшую часть идей модели и изложите ее ученикам простым языком.
Или мы можем разработать серию вопросов: сначала пусть модель сама обдумает все решение, не позволяя учащимся отвечать, а затем дайте учащимся простой аналогичный вопрос, основанный на идеях модели. После того, как учащиеся ответят, позвольте модели судить правильные ли ответы учащихся.
Наконец, модель использует простой для понимания язык, чтобы объяснить учащимся правильные идеи решения. Это не только тренирует способность модели рассуждать, но и позволяет учащимся думать самостоятельно, не сообщая им все ответы напрямую.

Спросите модель, не пропустила ли она что-нибудь на предыдущем проходе.
Предположим, мы просим модель найти предложения, связанные с определенным вопросом, в большом файле, и модель будет сообщать нам по одному предложению за раз.
Но иногда модель ошибается и останавливается, когда ей следует продолжить поиск связанных предложений, в результате чего связанные предложения пропускаются и не сообщаются нам позже.
В это время мы можем напомнить модели «Есть ли еще связанные предложения?», после чего она продолжит запрашивать связанные предложения, чтобы модель могла найти более полную информацию.
Используйте внешние инструменты
Эффективный поиск знаний с использованием поиска на основе встраивания
Если мы добавим некоторую внешнюю информацию к входным данным модели, модель сможет отвечать на вопросы более разумно. Например, если пользователь задает вопрос об определенном фильме, мы можем ввести в модель некоторую важную информацию о фильме (например, актеров, режиссеров и т. д.), чтобы модель могла дать более разумные ответы.
Встраивание текста — это вектор, который измеряет взаимосвязь между текстами. Похожие или связанные текстовые векторы находятся ближе, тогда как несвязанные текстовые векторы находятся относительно далеко, что означает, что мы можем использовать встраивания для эффективного поиска знаний.
В частности, мы можем разрезать текстовый корпус на фрагменты, встраивать и хранить каждый фрагмент. Затем мы можем встроить заданный запрос и найти наиболее релевантный фрагмент встроенного текста в корпусе (т. е. фрагмент текста, который ближе всего к запросу в пространстве внедрения) с помощью векторного поиска.
Используйте выполнение кода для более точных вычислений или вызова внешних API.
Языковые модели не всегда способны точно выполнять сложные математические операции или вычисления, которые занимают много времени. В этом случае мы можем попросить модель написать некоторый код для выполнения задачи, а не позволять ей выполнять вычисления самостоятельно.
В частности, мы можем поручить модели написать код, который необходимо запустить, в определенном формате, например, окружив его тройными обратными кавычками. Когда код генерирует результаты, мы можем извлечь их и выполнить.
Наконец, при желании выходные данные механизма выполнения кода (например, интерпретатора Python) можно использовать в качестве входных данных для следующего вопроса в модели. Это позволяет более эффективно выполнять задачи, требующие вычислений.

Еще один отличный пример использования выполнения кода — использование внешних API (интерфейсов прикладного программирования). Если мы сообщим модели, как правильно использовать API, она сможет написать код, вызывающий этот API.
Мы можем предоставить модели некоторую документацию или примеры кода, показывающие, как использовать API, чтобы модель могла научиться использовать API. Проще говоря, предоставив модели некоторые рекомендации по API, она может создать код для реализации большего количества функций.

Предупреждение. Выполнение кода, сгенерированного моделью, по своей сути небезопасно, и любое приложение, пытающееся это сделать, должно принять меры предосторожности. В частности, изолированные среды выполнения кода необходимы для ограничения потенциального вреда, который может нанести ненадежный код.
Пусть модель обеспечивает конкретную функциональность
Мы можем передать ему список с описанием функциональности через запрос API. Таким образом, модель способна генерировать параметры функции на основе предоставленного шаблона. Сгенерированные параметры функции возвращаются в формате JSON, который мы затем используем для выполнения вызова функции.
Затем можно реализовать цикл, передавая выходные данные вызова функции обратно в модель в следующем запросе.Это рекомендуемый способ вызова внешних функций с использованием модели OpenAI.
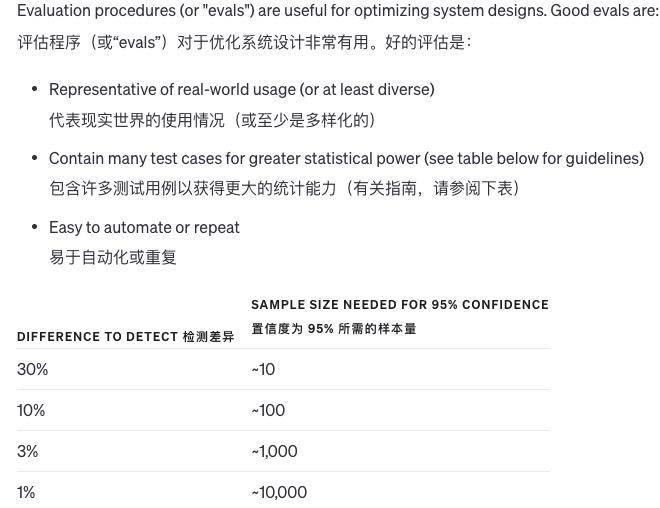
Систематически тестируйте изменения
Когда мы вносим изменения в систему, трудно судить, хорошие это изменения или плохие. Поскольку примеров так мало, трудно определить, действительно ли результаты улучшились или это просто вопрос удачи. Иногда модификация хороша в одних ситуациях и плоха в других.
Так как же нам оценить качество вывода системы? Если на вопрос существует только один стандартный ответ, компьютер может автоматически определить, правильный он или нет. Если стандартного ответа нет, для оценки качества можно использовать другие модели.
Кроме того, мы также можем позволить людям оценивать субъективное качество или комбинировать компьютерную и человеческую оценку. Когда ответ на вопрос очень длинный и качество разных ответов не сильно различается, модель может оценить качество сама. .
Конечно, по мере того, как модели становятся более продвинутыми, все больше и больше контента может оцениваться автоматически, и требуется все меньше и меньше ручной оценки. Улучшить систему оценки очень сложно, и лучшим методом является объединение компьютеров и искусственного интеллекта.
Оцените выходные данные модели по сравнению с ответами золотого стандарта
Предположим, мы столкнулись с проблемой и нам нужен ответ. Мы уже знаем правильный ответ на этот вопрос, исходя из некоторых фактов. Например, на вопрос: «Почему небо голубое?» Правильным ответом может быть: «Потому что, когда солнечный свет проходит через атмосферу, свет в синей полосе света проходит лучше, чем другие цвета».
Этот ответ основан на следующих фактах:
Солнечный свет содержит разные цвета (светлые полосы).
Полоса синего света имеет меньшие потери при прохождении через атмосферу.
После того, как у нас есть вопрос и правильный ответ, мы можем использовать модель (например, модель машинного обучения), чтобы оценить важность каждого факта в ответе на правильный ответ.
Например, модель определяет, что тот факт, что «солнечный свет содержит разные цвета» в ответе, очень важен для правильности ответа. Для ответа также важен тот факт, что «полоса синего света имеет меньшие потери». Таким образом, мы сможем узнать, от каких ключевых известных фактов зависит ответ на этот вопрос.

В процессе человеко-машинного общения с помощью ChatGPT слова-подсказки кажутся простыми, но они играют наиболее важную роль. В эпоху цифровых технологий слова-подсказки являются отправной точкой для разделения требований. Разработав умные слова-подсказки, мы можем разделить всю Задача, разделенная на серию кратких шагов.
Такая декомпозиция не только помогает модели лучше понять намерения пользователя, но также предоставляет пользователю более четкий путь действий, точно так же, как дает подсказку, которая поможет нам шаг за шагом найти ответ на проблему.
Ваши и мои потребности подобны бурлящей реке, а слово-подсказка — шлюзу, регулирующему направление потока. Оно играет роль узла, соединяющего мышление пользователя и понимание машины. Не будет преувеличением сказать, что хорошее слово-подсказка — это не только проникновение в глубокое понимание пользователя, но и молчаливое понимание человеко-машинного общения.
Конечно, если вы хотите по-настоящему овладеть навыками использования слов-подсказок, недостаточно полагаться только на разработку подсказок, но официальное руководство по использованию OpenAI всегда предоставляет нам ценные вводные рекомендации.
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo