Только что Хуан Жэньсюнь представил ИИ-чип ядерной бомбы третьего поколения! Персональный суперкомпьютер выполняет 1000 триллионов операций в секунду, DeepSeek становится крупнейшим победителем

Конференция Nvidia GTC стала Суперкубком индустрии искусственного интеллекта. Здесь нет сценария или телесуфлера, и Хуан Ренсюнь застрял на полпути. Напротив, это самая гуманная часть этой конференции по искусственному интеллекту с высокой концентрацией. На современных технологических конференциях уже очень редко репетируются или записываются заранее.

Только что Хуан Жэньсюнь снова выпустил новое поколение чипов искусственного интеллекта уровня ядерной бомбы, но на этой конференции есть и скрытый главный герой — DeepSeek.
Благодаря улучшениям в ИИ агентов (Agentic AI) и возможностях рассуждения, объем необходимых вычислений сейчас как минимум в 100 раз превышает тот, который оценивался в это время в прошлом году.
Влияние рассуждений об экономической эффективности на индустрию искусственного интеллекта, а не просто накопление вычислительной мощности, стало основной темой всей этой конференции. NVIDIA хочет стать фабрикой искусственного интеллекта, позволяющей искусственному интеллекту учиться и рассуждать со скоростью, превышающей скорость человека.
По сути, аргументация заключается в том, что фабрика производит токены, и стоимость фабрики зависит от того, может ли она генерировать доход и прибыль. Поэтому завод пришлось строить с предельной эффективностью.
Новая «ядерная бомба» NVIDIA, которую вытащил Джен-Сун Хуан, также говорит нам о том, что будущая конкуренция в области искусственного интеллекта заключается не в том, чья модель больше, а в том, чья модель имеет наименьшую стоимость рассуждений и более высокую эффективность рассуждений.
Помимо нового чипа Blackwell, есть еще два «Настоящих ПК с искусственным интеллектом».
Новый чип Blackwell под кодовым названием «Ultra» представляет собой AI-чип GB300. Он приходит на смену прошлогоднему «самому мощному в мире AI-чипу» B200 и снова достигает прорыва в производительности.
Blackwell Ultra будет включать стоечное решение NVIDIA GB300 NVL72, а также систему NVIDIA HGX B300 NVL16.

Blackwell Ultra GB300 NVL72 будет выпущен во второй половине этого года. Подробности параметров следующие:
- 1.1 Вывод EF FP4: при выполнении задач прецизионного вывода FP4 он может достигать 1,1 ExaFLOPS (exaFLOPS).
- 0,36 EF FP8 Обучение: Производительность составляет 1,2 Эксафлопс при выполнении обучающих задач с точностью FP8.
- Увеличение в 1,5 раза GB300 NVL72: по сравнению с GB200 NVL72 производительность в 1,5 раза выше.
- 20 ТБ HBM3: оснащен памятью HBM 20 ТБ, что в 1,5 раза больше, чем у предыдущего поколения.
- Быстрая память 40 ТБ: он имеет 40 ТБ быстрой памяти, что в 1,5 раза больше, чем у предыдущего поколения.
- 14,4 ТБ/с CX8: поддерживает CX8 с пропускной способностью 14,4 ТБ/с, что в 2 раза больше, чем у предыдущего поколения.
Один чип Blackwell Ultra обеспечит ту же производительность искусственного интеллекта в 20 петафлопс (петафлопс), что и его предшественник, но с большим объемом памяти HBM3e на 288 ГБ.
Если H100 больше подходит для обучения крупномасштабных моделей, а B200 хорошо справляется с задачами вывода, то B300 — это многофункциональная платформа, которая может обрабатывать предварительное обучение, постобучение и вывод искусственного интеллекта.

NVIDIA также особо отметила, что Blackwell Ultra также подходит для агентов ИИ и «физического ИИ», используемого для обучения роботов и автономных транспортных средств.
Для дальнейшего повышения производительности системы Blackwell Ultra также будет интегрирован с платформами NVIDIA Spectrum-X Ethernet и NVIDIA Quantum-X800 InfiniBand, чтобы обеспечить количественную пропускную способность 800 Гбит/с для каждого графического процессора в системе, помогая фабрикам искусственного интеллекта и облачным центрам обработки данных быстрее обрабатывать модели вывода искусственного интеллекта.
В дополнение к стойке NVL72 Nvidia также выпустила DGX Station, настольный компьютер с одним чипом GB300 Blackwell Ultra. В дополнение к Blackwell Ultra этот хост также будет оснащен 784 ГБ такой же системной памяти, встроенной сетью NVIDIA ConnectX-8 SuperNIC со скоростью 800 Гбит/с и сможет поддерживать производительность искусственного интеллекта 20 петафлопс.

«Мини-хост» Project DIGITS, ранее представленный на выставке CES 2025, также официально называется DGX Spark. Он оснащен суперчипом GB10 Grace Blackwell, специально оптимизированным для настольных компьютеров. Он может выполнять до 1000 триллионов вычислительных операций ИИ в секунду и используется для точной настройки и рассуждения новейших моделей ИИ, включая базовую модель мира NVIDIA Cosmos Reason и базовую модель робота NVIDIA GR00T N1.
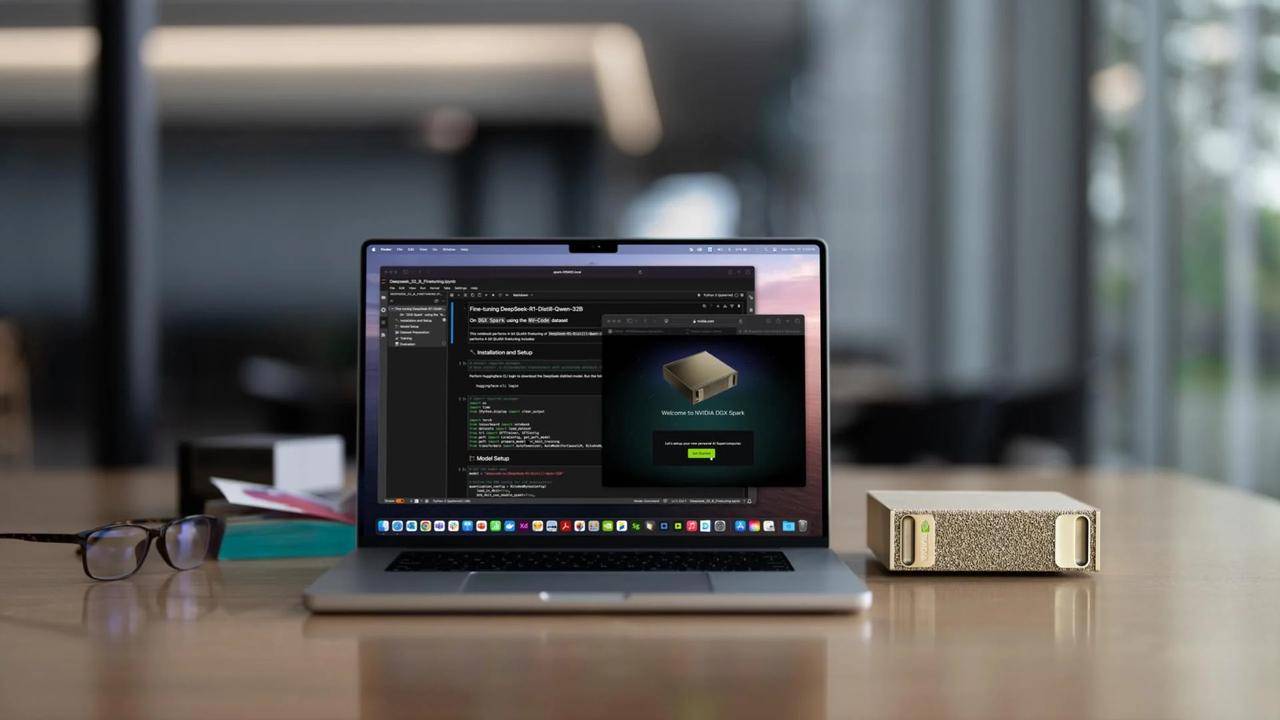
Хуан Ренсюнь сказал, что с помощью DGX Station и DGX Spark пользователи могут запускать большие модели локально или развертывать их в других ускоренных облаках или инфраструктуре центров обработки данных, таких как NVIDIA DGX Cloud.
Это компьютер эпохи ИИ.
Система DGX Spark уже доступна для предварительного заказа, а выпуск DGX Station ожидается позднее в этом году от таких партнеров, как ASUS, Dell, HP и других.
Официально анонсирован AI-чип следующего поколения Rubin, который будет выпущен во второй половине 2026 года
NVIDIA всегда называла свою архитектуру в честь ученых, и этот метод именования стал частью культуры NVIDIA. На этот раз Nvidia продолжила эту практику и назвала свою платформу чипов искусственного интеллекта следующего поколения «Вера Рубин» в честь известного американского астронома Веры Рубин.
Хуан Ренсюнь заявил, что результативность Рубина будет в 900 раз выше, чем у Хоппера, а Блэквелл добился улучшения в 68 раз по сравнению с Хоппером.
Среди них Vera Rubin NVL144, выход которого ожидается во второй половине 2026 года. Информация о параметрах сохраняет поток и не считывает версию:
- 3.6 Вывод EF FP4: при выполнении задач прецизионного вывода FP4 он может достигать 3,6 ExaFLOPS (exaFLOPS).
- 1.2 Обучение EF FP8: При выполнении обучающих задач с точностью FP8 производительность составляет 1,2 Эксафлопс.
- 3,3X GB300 NVL72: по сравнению с GB300 NVL72 производительность улучшена в 3,3 раза.
- HBM4 13 ТБ/с: оснащен HBM4, пропускная способность составляет 13 ТБ/с.
- Быстрая память 75 ТБ: он имеет 75 ТБ быстрой памяти, что в 1,6 раза больше, чем у предыдущего поколения.
- 260 ТБ/с NVLink6: поддерживает NVLink 6 с пропускной способностью 260 ТБ/с, что в 2 раза больше, чем у предыдущего поколения.
- 28,8 ТБ/с CX9: поддерживает CX9 с пропускной способностью 28,8 ТБ/с, что в 2 раза больше, чем у предыдущего поколения.

Стандартная версия Rubin будет оснащена HBM4, который значительно улучшил производительность по сравнению с нынешним чипом Hopper H100.
Рубин представил преемника под названием Grace CPU — Veru, который содержит 88 настраиваемых ядер Arm, каждое ядро поддерживает 176 потоков и обеспечивает соединение с высокой пропускной способностью 1,8 ТБ/с через NVLink-C2C.
Nvidia заявляет, что специальная конструкция Vera будет в два раза быстрее процессора, используемого в прошлогоднем чипе Grace Blackwell.
В сочетании с процессором Vera вычислительная мощность Rubin может достигать 50 петафлопс в задачах вывода, что более чем в два раза превышает 20 петафлопс у Blackwell. Кроме того, Rubin также поддерживает память HBM4 объемом до 288 ГБ, что также является одной из основных спецификаций, на которую обращают внимание разработчики ИИ.

Фактически Rubin состоит из двух графических процессоров, и эта концепция конструкции аналогична представленному сейчас на рынке графическому процессору Blackwell — последний также работает путем сборки двух независимых чипов в единое целое.
Начиная с Rubin, Nvidia больше не будет называть компоненты с несколькими графическими процессорами одним графическим процессором, как это было с Blackwell, а будет более точно подсчитывать их в соответствии с фактическим количеством кристаллов графического процессора.
Технология межсоединения также была модернизирована. Рубин оснащен NVLink шестого поколения и сетевой картой CX9, поддерживающей скорость 1600 Гбит/с, что позволяет ускорить передачу данных и улучшить качество связи.
Помимо стандартной версии Rubin, Nvidia также планирует выпустить Ultra-версию Rubin.

Rubin Ultra NVL576 будет выпущен во второй половине 2027 года. Детали параметра следующие:
- Вывод 15 EF FP4. Производительность достигает 15 экзафлопс при выполнении задач вывода с точностью FP4.
- 5 Обучение EF FP8: производительность 5 экзафлопс при выполнении задач обучения с точностью FP8.
- 14X GB300 NVL72: по сравнению с GB300 NVL72 производительность улучшена в 14 раз.
- 4,6 ПБ/с HBM4e: Оснащен памятью HBM4e, пропускная способность составляет 4,6 ПБ/с.
- Быстрая память объемом 365 ТБ. Система имеет 365 ТБ быстрой памяти, что в 8 раз больше, чем в предыдущем поколении.
- 1,5 ПБ/с NVLink7: поддерживает NVLink 7 с пропускной способностью 1,5 ПБ/с, что в 12 раз больше, чем у предыдущего поколения.
- 115,2 ТБ/с CX9: поддерживает CX9 с пропускной способностью 115,2 ТБ/с, что в 8 раз больше, чем у предыдущего поколения.
Что касается аппаратной конфигурации, система Veras от Rubin Ultra продолжает разработку 88 настраиваемых ядер Arm, каждое ядро поддерживает 176 потоков и обеспечивает пропускную способность 1,8 ТБ/с через NVLink-C2C.
Что касается графического процессора, Rubin Ultra объединяет четыре графических процессора Reticle-Size. Каждый графический процессор обеспечивает 100 петафлопс вычислительной мощности FP4 и оснащен 1 ТБ памяти HBM4e, достигая новых высот производительности и объема памяти.
Чтобы сохранить прочную позицию в быстро меняющейся рыночной конкуренции, ритм выпуска продуктов NVIDIA был сокращен до одного раза в год. На пресс-конференции Хуан также официально объявил название ИИ-чипа следующего поколения — физик Фейнман.
Поскольку масштабы фабрик искусственного интеллекта продолжают расширяться, важность сетевой инфраструктуры становится все более заметной.
С этой целью NVIDIA запустила Spectrum-X  и кремниевые оптические сетевые коммутаторы Quantum-X, призванные помочь фабрикам искусственного интеллекта соединять миллионы графических процессоров на разных площадках, одновременно значительно снижая энергопотребление и эксплуатационные расходы.
и кремниевые оптические сетевые коммутаторы Quantum-X, призванные помочь фабрикам искусственного интеллекта соединять миллионы графических процессоров на разных площадках, одновременно значительно снижая энергопотребление и эксплуатационные расходы.

Переключатели Spectrum-X Photonics доступны в различных конфигурациях, в том числе:
- Конфигурация с 128 портами 800 Гбит/с или 512 портами 200 Гбит/с с общей пропускной способностью 100 Тбит/с.
- Конфигурация с 512 портами 800 Гбит/с или 2048 портами 200 Гбит/с, общая пропускная способность достигает 400 Тбит/с.
Прилагаемый коммутатор Quantum-X Photonics основан на технологии SerDes 200 Гбит/с, обеспечивает 144-портовые соединения InfiniBand 800 Гбит/с и использует конструкцию жидкостного охлаждения для эффективного охлаждения встроенных компонентов кремниевой фотоники.
Коммутаторы Quantum-X Photonics обеспечивают двукратную скорость и пятикратную масштабируемость вычислительной архитектуры искусственного интеллекта по сравнению с продуктами предыдущего поколения.
Ожидается, что коммутаторы Quantum-X Photonics InfiniBand появятся в продаже позднее в этом году, а коммутаторы Spectrum-X Photonics Ethernet появятся в продаже в 2026 году.
С быстрым развитием искусственного интеллекта резко возросла потребность в пропускной способности, низкой задержке и высокой энергоэффективности в центрах обработки данных.
В коммутаторах NVIDIA Spectrum-X Photonics используется технология интеграции фотоники, называемая CPO. Его суть заключается в том, чтобы поместить оптический механизм (то есть чип, который может обрабатывать оптические сигналы) и обычные электронные микросхемы (такие как коммутационные чипы или микросхемы ASIC) в одном корпусе.
Преимуществ у этой техники много:
- Более высокая эффективность передачи: поскольку расстояние сокращается, сигнал передается быстрее.
- Меньшее энергопотребление: расстояние короче, и для передачи сигналов требуется меньше энергии.
- Меньший размер: за счет интеграции оптических и электрических компонентов общий размер становится меньше, а использование пространства выше.
Dynamo, «операционная система» для заводов искусственного интеллекта
В будущем не будет центров обработки данных, будут только фабрики искусственного интеллекта.
Хуан Жэньсюнь сказал, что в будущем, когда в каждой отрасли и каждой компании будет своя фабрика, будет две фабрики: одна — это фабрика, на которой они фактически производят, а другая — фабрика ИИ, а «Динамо» — это операционная система, специально созданная для «фабрики ИИ».
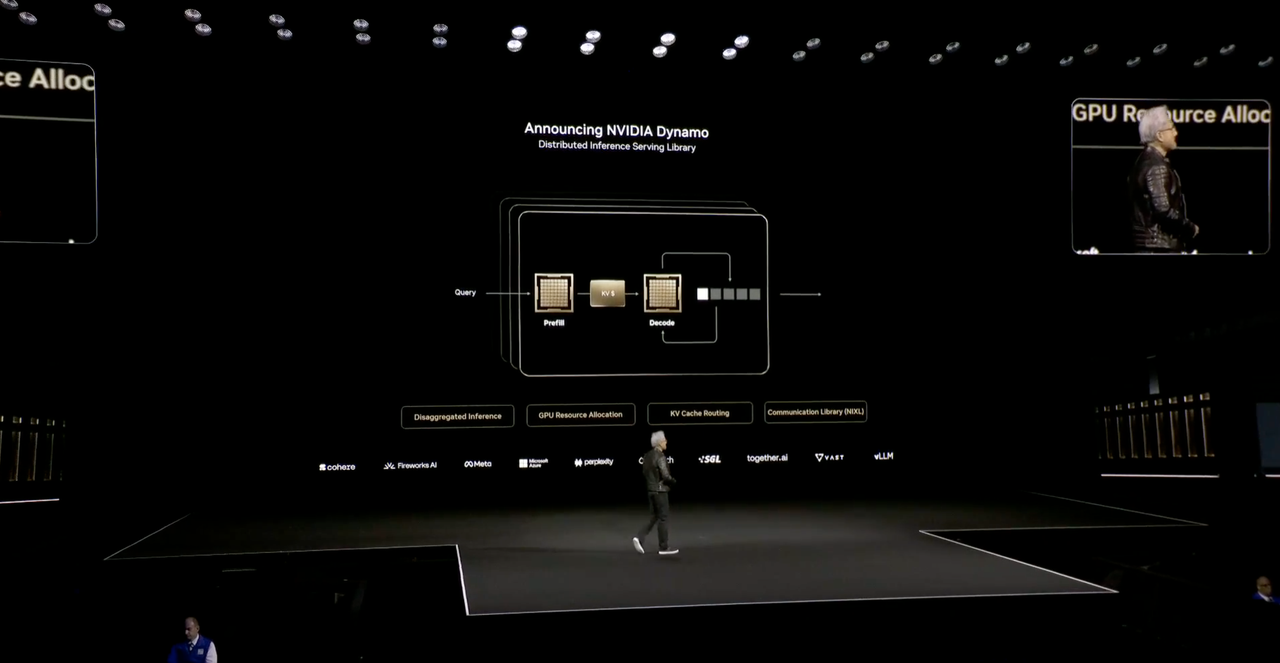
Dynamo — это распределенная библиотека служб рассуждений, которая предоставляет решения с открытым исходным кодом для проблем, требующих токенов, но не позволяющих получить достаточное количество токенов.
Проще говоря, у «Динамо» четыре преимущества:
- Механизм планирования графического процессора динамически планирует ресурсы графического процессора для адаптации к потребностям пользователя.
- Интеллектуальный маршрутизатор уменьшает перерасчет повторных и перекрывающихся запросов на графическом процессоре, высвобождая больше вычислительной мощности для обработки новых входящих запросов.
- Библиотека связи с малой задержкой для ускорения передачи данных
- Менеджер памяти, интеллектуальный анализ данных в недорогих устройствах памяти и хранения данных.
Роботы-гуманоиды никогда не исчезнут из их облика
Роботы-гуманоиды снова стали финалом конференции GTC. На этот раз NVIDIA представила Isaac GR00T N1, первую в мире функциональную модель робота-гуманоида с открытым исходным кодом.

Хуан Ренсюнь сказал, что наступила эра общей робототехники. С помощью системы генерации данных и обучения роботов ядра Isaac GR00T N1 разработчики роботов по всему миру выйдут на новый рубеж эпохи искусственного интеллекта.
Эта модель использует архитектуру «двойной системы» для имитации когнитивных принципов человека:
- Система 1: Модель быстрого мышления, имитирующая человеческие реакции или интуицию.
- Система 2: Модель медленного мышления для обдуманного принятия решений.
При поддержке модели визуального языка Система 2 рассуждает об окружающей среде и дает инструкции, а затем планирует действия. Система 1 преобразует эти планы в действия робота.
Базовая модель GR00T N1 предварительно обучается с использованием обобщенных человеческих рассуждений и навыков, а разработчики могут проводить дополнительное обучение на реальных или синтетических данных для удовлетворения конкретных потребностей: может ли она выполнять конкретные задачи на заводе или автономно выполнять домашние дела дома.
Хуан также анонсировал Newton, физический движок с открытым исходным кодом, разработанный в сотрудничестве с Google DeepMind и Disney Research.

На сцене также появился робот, оснащенный платформой Ньютона. Хуан назвал его «Синим». Он был похож на робота BDX из «Звездных войн» и мог взаимодействовать с Хуангом с помощью голоса и движений.
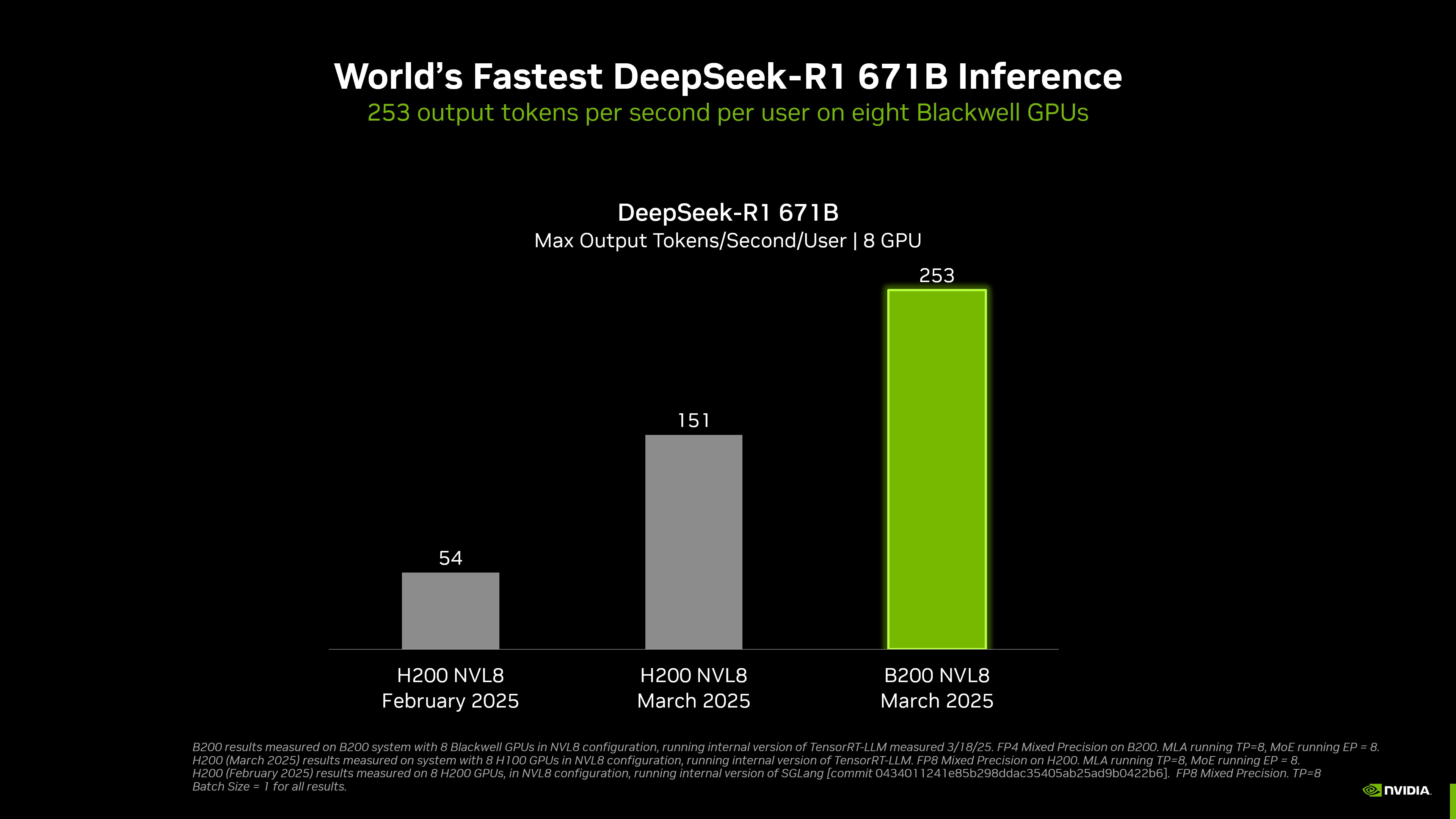
Благодаря 8 графическим процессорам скорость вывода DeepSeek-R1 является самой высокой в мире.
NVIDIA достигла самого быстрого в мире вывода DeepSeek-R1.
Согласно официальному сайту, система DGX, оснащенная 8 графическими процессорами Blackwell, может достигать скорости более 250 токенов в секунду на пользователя при запуске модели DeepSeek-R1 с 671 миллиардом параметров или достигать максимальной пропускной способности более 30 000 токенов в секунду.
Благодаря сочетанию аппаратного и программного обеспечения пропускная способность NVIDIA на модели DeepSeek-R1 671B увеличилась примерно в 36 раз с января этого года, а экономическая эффективность на один токен увеличилась примерно в 32 раза.
Для достижения этого достижения вся экосистема вывода NVIDIA была глубоко оптимизирована для архитектуры Blackwell. Она не только интегрирует передовые инструменты, такие как TensorRT-LLM и TensorRT Model Optimizer, но также беспрепятственно поддерживает основные платформы, такие как PyTorch, JAX и TensorFlow.
На таких моделях, как DeepSeek-R1, Llama 3.1 405B и Llama 3.3 70B, платформа DGX B200 с точностью FP4 повышает скорость вывода более чем в 3 раза по сравнению с платформой DGX H200.
Стоит отметить, что в программном докладе этой конференции не упоминались квантовые вычисления, но NVIDIA специально организовала квантовый день на этой конференции GTC и пригласила на него руководителей многих популярных компаний, занимающихся квантовыми вычислениями.
Вы должны знать, что утверждение Хуан Жэньсюня в начале года о том, что «квантовым вычислениям потребуется 20 лет, чтобы стать практическими», все еще в моих ушах.
За изменением тона он неотделим от топологического квантового чипа Microsoft Majorana 1, которому потребовалось 17 лет, чтобы разработать и реализовать интеграцию 8 топологических кубитов. Он также неотделим от чипа Google Willow, который утверждает, что выполняет задачу, на обработку которой классическому компьютеру требуется 10^25 лет, за 5 минут, что способствует повальному увлечению квантовыми вычислениями.

Чип, несомненно, является изюминкой, но дебют некоторого программного обеспечения также заслуживает внимания.
Марк Андриссен, известный инвестор из Кремниевой долины, однажды заявил, что программное обеспечение пожирает мир. Основная логика заключается в том, что программное обеспечение становится инфраструктурой, которая контролирует физический мир посредством виртуализации, абстракции и стандартизации.
Не довольствуясь ролью «продавца лопат», NVIDIA стремится создать «производительную операционную систему» в эпоху искусственного интеллекта. От интеллектуального вождения автомобилей до фабрик цифровых двойников в обрабатывающей промышленности — эти примеры, представленные на конференции, являются конкретным выражением преобразования вычислительной мощности графических процессоров в производительность отрасли.
Фактически, будь то новейший чип ядерной бомбы, представленный на пресс-конференции, или квантовые вычисления, делающие ставку на будущее, идеи Хуан Жэньсюня и план будущего развития ИИ на этой пресс-конференции более интересны, чем текущие технические параметры и показатели производительности.

Сравнивая архитектуру Блэквелла и Хоппера, Хуан Ренсюнь также не забыл использовать юмор.
В качестве примера он использовал сравнительные данные завода мощностью 100 МВт, указав, что архитектура Hopper требует 45 000 чипов и 400 стоек, в то время как архитектура Blackwell значительно снижает требования к оборудованию за счет более высокой эффективности.
Поэтому классическое резюме Хуан Жэньсюня было снова выброшено: «чем больше вы покупаете, тем больше вы экономите» (чем больше вы покупаете, тем больше вы экономите). Затем тема изменилась, и он добавил: «чем больше вы покупаете, тем больше вы зарабатываете» (чем больше вы покупаете, тем больше вы зарабатываете).
Поскольку фокус в области искусственного интеллекта смещается от обучения к рассуждению, NVIDIA необходимо доказать, что ее программная и аппаратная экосистема незаменима в сценариях рассуждения.
С одной стороны, такие гиганты, как Meta и Google, разрабатывают собственные чипы искусственного интеллекта, которые могут отвлечь спрос от рынка графических процессоров.
С другой стороны, своевременный дебют новейших чипов искусственного интеллекта NVIDIA является ответом на влияние моделей с открытым исходным кодом, таких как DeepSeek, на спрос на графические процессоры и демонстрирует технологические преимущества в области рассуждений. Это также призвано застраховаться от опасений рынка по поводу пикового спроса на обучение.
Nvidia, чья оценка недавно упала до 10-летнего минимума, нуждается в серьезной победе больше, чем когда-либо.
# Добро пожаловать на официальную общедоступную учетную запись WeChat aifaner: aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo