Только что OpenAI выпустила сразу три новые модели! Я также сделал новый сайт для этой цели
Только сейчас OpenAI объявила о запуске нового поколения аудиомоделей в своем API, включая функции преобразования речи в текст и преобразования текста в речь, что позволяет разработчикам легко создавать мощные голосовые агенты.
Основные характеристики нового продукта кратко изложены ниже.
- gpt-4o-transcribe (речь в текст): значительное снижение частоты ошибок в словах (WER), превосходя существующие модели Whisper по нескольким тестам.
- gpt-4o-mini-transcribe (преобразование речи в текст): упрощенная версия gpt-4o-transcribe, более быстрая и эффективная.
- gpt-4o-mini-tts (преобразование текста в речь): впервые поддерживая «управляемость», разработчики могут не только указывать, «что сказать», но и контролировать, «как это сказать».
По данным OpenAI, недавно выпущенный gpt-4o-transcribe в течение длительного времени обучался с использованием разнообразных и высококачественных наборов аудиоданных, которые могут лучше улавливать нюансы речи, уменьшать неправильное распознавание и значительно повышать надежность транскрипции.
Таким образом, gpt-4o-transcribe больше подходит для обработки сложных сценариев, таких как различные акценты, шумная среда и изменение скорости речи, например, в центрах обработки вызовов клиентов, стенограммах встреч и других областях.
gpt-4o-mini-transcribe основан на архитектуре GPT-4o-mini и передает возможности больших моделей посредством технологии дистилляции знаний. Хотя WER (чем ниже, тем лучше) немного выше, чем у полной версии модели, он все же лучше исходной модели Whisper и больше подходит для сценариев применения с ограниченными ресурсами, но при этом требующих высококачественного распознавания речи.
Производительность этих двух моделей в многоязычном тесте FLEURS превзошла существующие модели Whisper v2 и v3, особенно на английском, испанском и других языках.
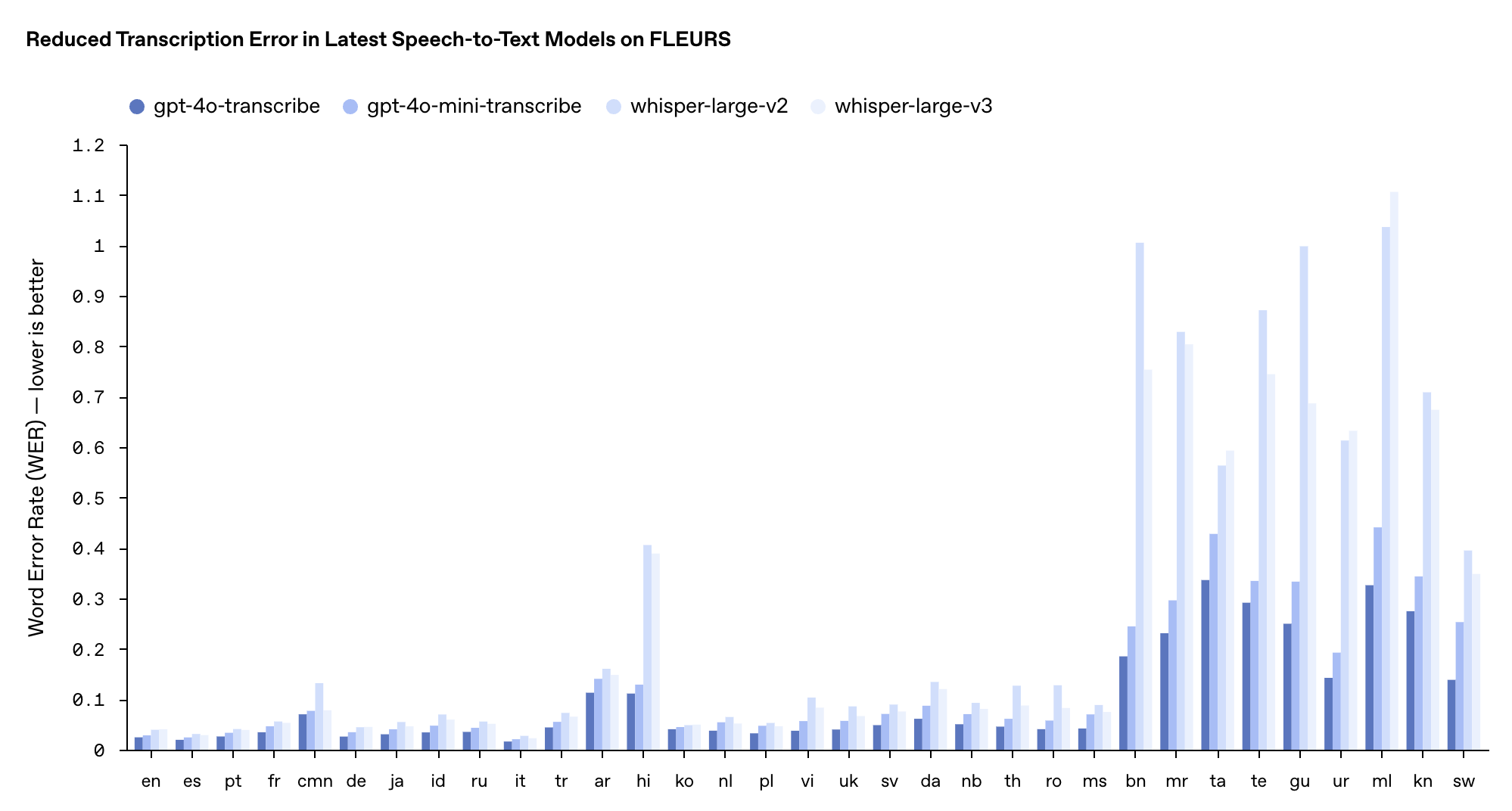
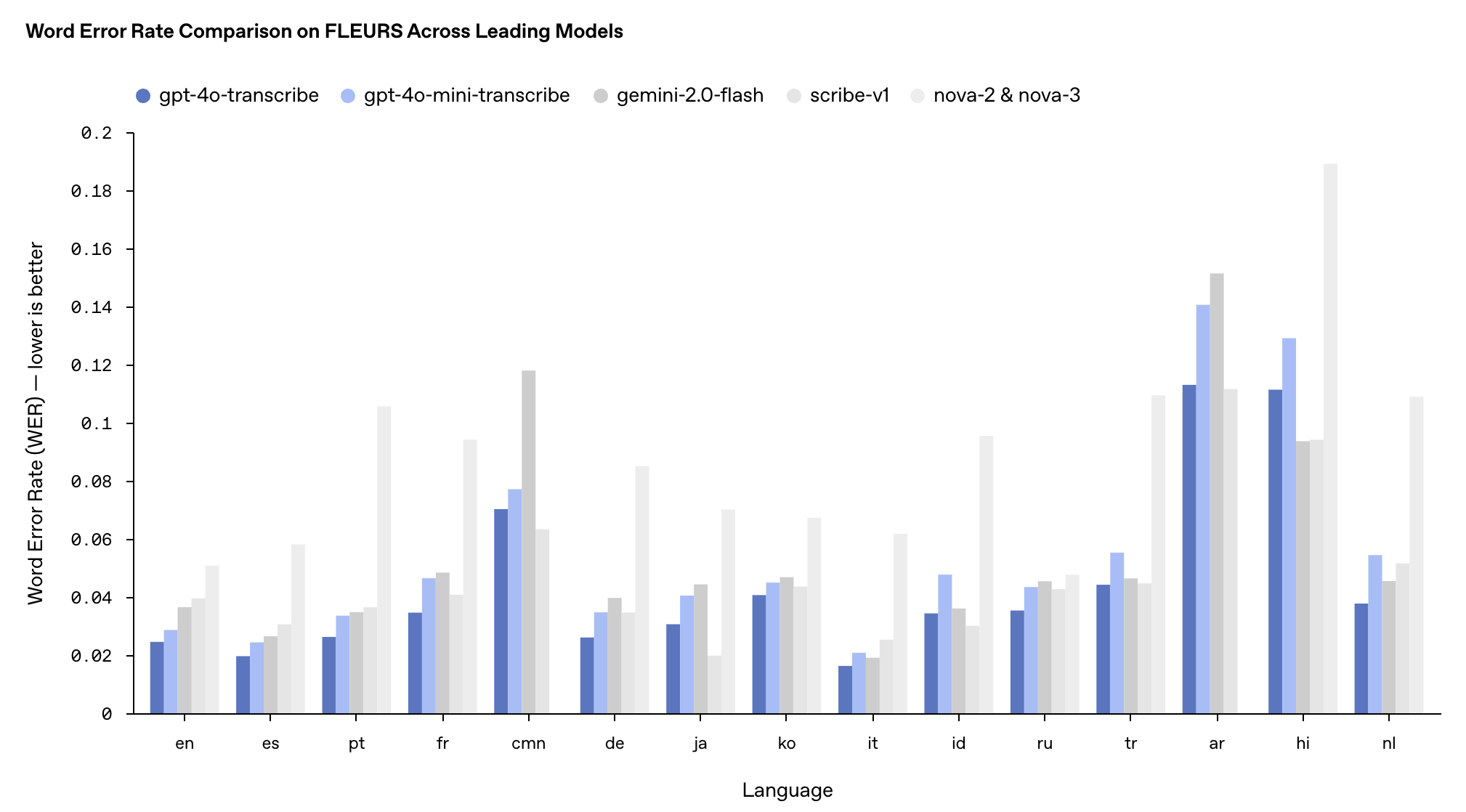
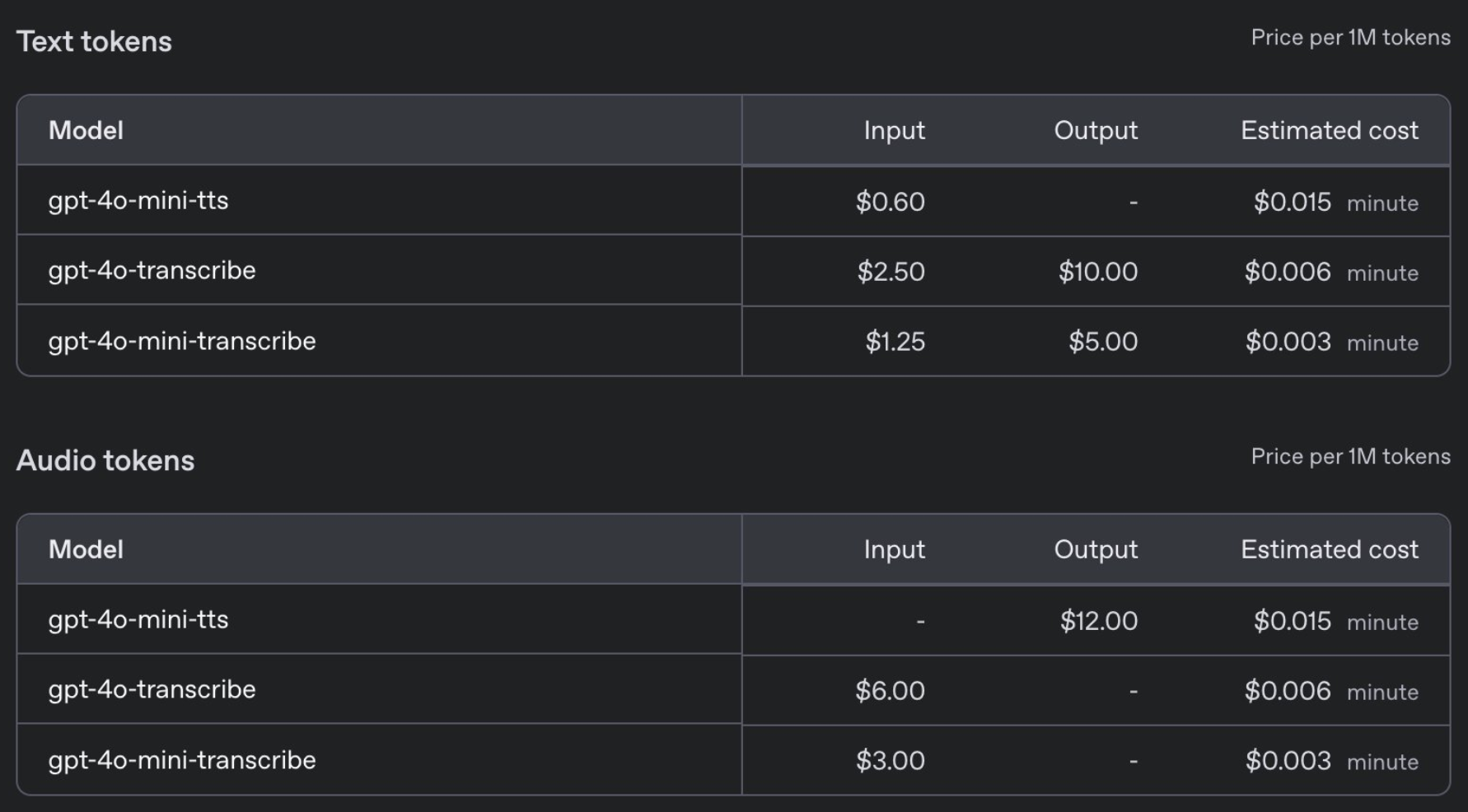
Что касается цен, GPT-4o-transcribe стоит так же, как и предыдущая модель Whisper, — 0,006 доллара за минуту, а GPT-4o-mini-transcribe стоит вдвое дешевле — 0,003 доллара за минуту.
В то же время OpenAI также выпустила новую модель преобразования текста в речь gpt-4o-mini-tts. Впервые разработчики могут не только указывать, что говорить, но и контролировать, как это говорить.
В частности, разработчики могут предварительно настроить различные стили голоса, такие как «Спокойный», «Серфер», «Профессионал», «Средневековый рыцарь» и т. д. Также можно настроить стиль голоса в соответствии с инструкциями, например «Говорите как сострадательный агент службы поддержки клиентов». Цена доступна всего за 0,015 доллара за минуту.
К безопасности нельзя относиться легкомысленно, и OpenAI заявляет, что gpt-4o-mini-tts будет постоянно контролироваться, чтобы гарантировать, что его выходные данные соответствуют заданному стилю синтеза.
За этими технологическими достижениями стоит множество инноваций OpenAI:
- Новая аудиомодель построена на архитектуре GPT-4o и GPT-4o-mini и предварительно обучена с использованием реальных наборов аудиоданных.
- Примените метод дистилляции знаний из очищенных наборов данных, созданных методом самостоятельной игры, чтобы добиться передачи знаний от больших моделей к маленьким моделям.
- Интеграция обучения с подкреплением (RL) в технологию преобразования речи в текст может значительно повысить точность транскрипции и уменьшить явления «иллюзии».
Ранним утром в прямом эфире OpenAI показала нам пример применения агента-консультанта по моде с использованием искусственного интеллекта.
Когда пользователь спросил «Какой у меня последний заказ?», система отреагировала гладко: шорты Patagonia, заказанные пользователем 9 февраля, были отправлены, а номер заказа «AD 507» был точно указан в дополнительном вопросе.
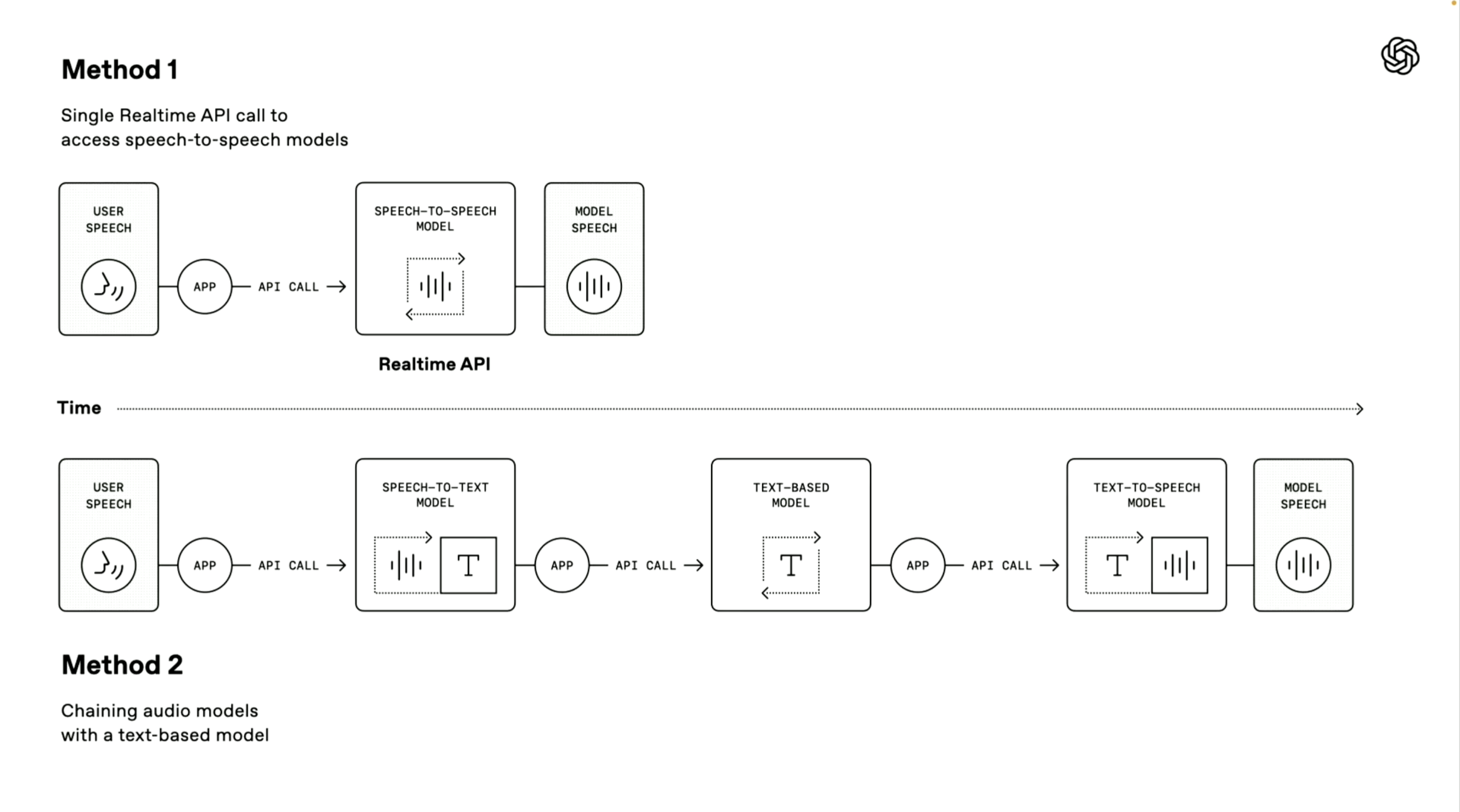
Стоит отметить, что демонстратор OpenAI также представил два технических пути создания голосового агента. Первая «модель преобразования речи в речь» использует метод сквозной прямой обработки.
Система может напрямую получать голосовой ввод пользователя и генерировать голосовые ответы без промежуточных этапов преобразования. Этот метод имеет более высокую скорость обработки и применяется в расширенном голосовом режиме ChatGPT и службах API в реальном времени. Он очень подходит для сценариев, требующих чрезвычайно высокой скорости ответа.
Второй «цепной метод» находится в центре внимания данной конференции.
Он разбивает весь процесс обработки на три независимых звена: сначала модель преобразования речи в текст используется для преобразования речи пользователя в текст, затем модель большого языка (LLM) обрабатывает текстовое содержимое и генерирует текст ответа и, наконец, модель преобразования текста в речь используется для преобразования ответа в естественный речевой вывод.
Преимущества этого метода — модульная конструкция, каждый компонент можно оптимизировать независимо; результаты обработки более стабильны, поскольку технология обработки текста обычно более зрелая, чем прямая обработка звука, а порог разработки ниже, разработчики могут быстро добавлять голосовые функции на основе существующих текстовых систем;
OpenAI также предоставляет несколько улучшений для этих систем голосового взаимодействия:
- Поддерживает потоковую передачу голоса для непрерывного ввода и вывода звука.
- Встроенная функция шумоподавления повышает четкость речи.
- Обнаружение семантической речевой активности, позволяющее определить, когда пользователь закончил говорить.
- Предоставление инструментов отслеживания пользовательского интерфейса, которые помогут разработчикам отлаживать голосовые агенты.
В настоящее время эти новые аудиомодели доступны разработчикам по всему миру.
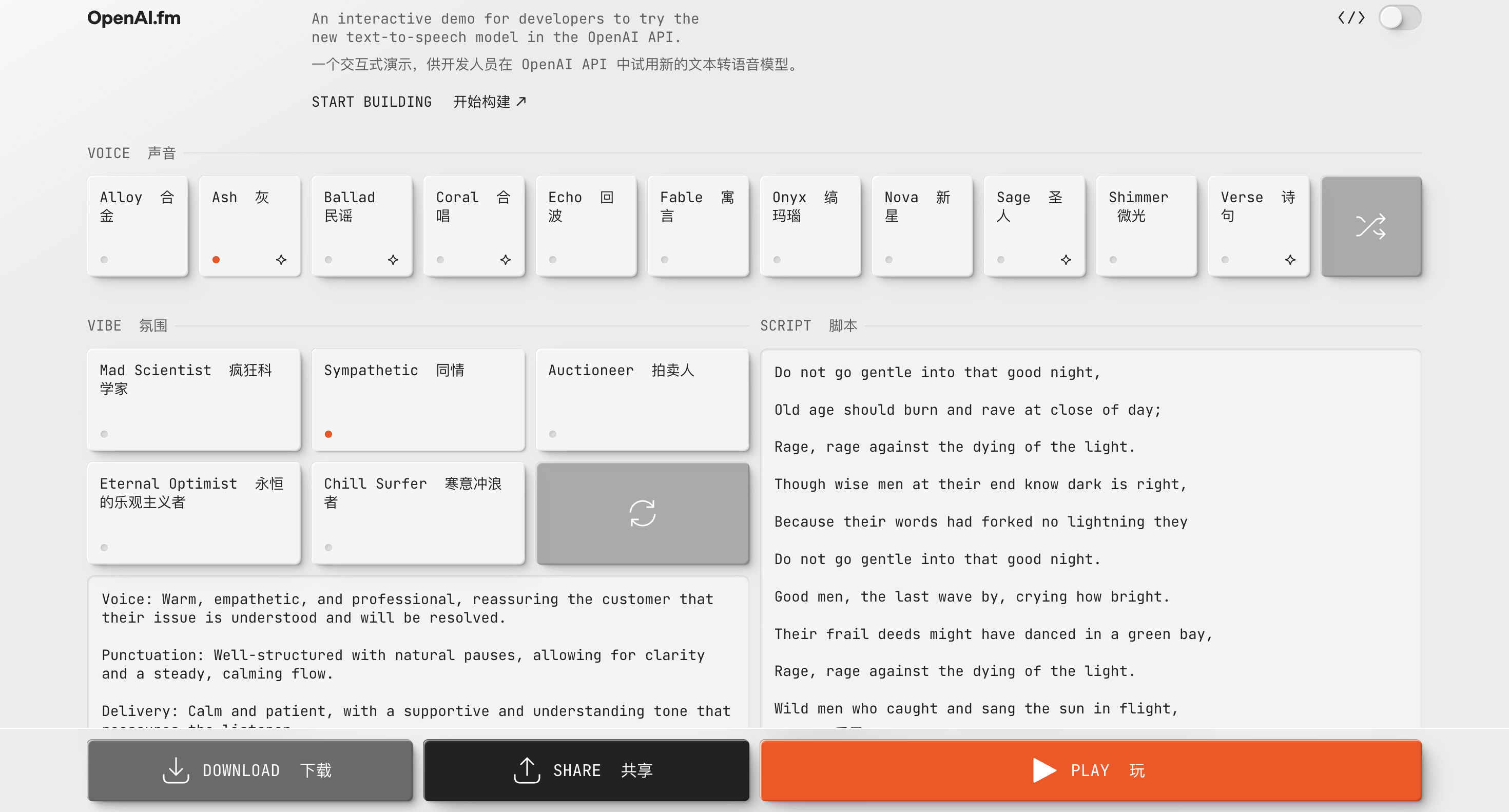
Вы также можете испытать и создать аудио, связанное с gpt-4o-mini-tts, на http://OpenAI.fm. Этот демонстрационный веб-сайт полностью функционален. В левом нижнем углу находится официальный предустановленный шаблон, который в основном включает в себя такие настройки, как индивидуальность, тон, диалект и произношение.
Еще мы тестировали скороговорку около восьмисот бегунов по северному склону Эммм, китайская версия была так себе. Что касается английского эффекта, то слушать его декламацию стихов вполне похоже на настоящего человека, но по сравнению с популярными ранее Hume AI или Sesame он все же не так хорош, как «слышимый человеческим ухом».
Кроме того, OpenAI запустила интеграцию с Agents SDK для дальнейшего упрощения процесса разработки.
Стоит отметить, что OpenAI также провела конкурс трансляций. Пользователи могут создавать аудио на http://OpenAI.fm, затем использовать кнопку «Поделиться» на OpenAI.fm, чтобы создать ссылку, а затем поделиться ссылкой на платформе X.
Каждый из трех самых креативных участников получит по ограниченной серии Teenage Engineering OB-4. Рекомендуется контролировать продолжительность звука примерно на уровне 30 секунд, и вы можете проявлять творческий подход к голосу, выражению лица, произношению или изменению интонации сценария.

Фактически, в этом году тенденция искусственного интеллекта также незаметно меняется. Помимо по-прежнему упора на IQ, существует еще одна тенденция акцентирования внимания на эмоциях.
Плюсами GPT-4.5 и Grok 3 являются эмоциональный интеллект, более творческое письмо и более персонализированные ответы, в то время как холодный робот (Zhiyuan Robot) также подчеркивает свою антропоморфность и фокусируется на эмоциональной ценности.
Поскольку голосовое поле напрямую затрагивает самый инстинктивный способ общения людей, в этой области оно предприняло еще более значительные усилия.
Искусственный интеллект «Сезам», который недавно стал популярен в Кремниевой долине, может чувствовать эмоции пользователей в режиме реального времени и генерировать эмоционально резонансные реакции, быстро захватывая сердца большого количества пользователей. Лауреат премии Тьюринга Ян Лекун также недавно подчеркнул, что у будущего искусственного интеллекта должны быть эмоции.
И новая голосовая модель, выпущенная сегодня OpenAI, и Meta Llama 4, которая скоро будет выпущена, призваны приблизиться к естественному голосовому диалогу, пытаясь сократить расстояние с пользователями за счет более естественного эмоционального взаимодействия и полагаться на «человеческое прикосновение» для привлечения поклонников.
Должен ли ИИ быть человеком? Надолго. Чат-ботов часто называют безэмоциональными инструментами, и они также будут напоминать вам во время разговора, что это бездушная модель. Однако мы часто можем интерпретировать из него эмоциональную ценность и даже неосознанно устанавливать с ним эмоциональные связи.
Возможно, у людей есть врожденное желание, чтобы их понимали и сопровождали, даже если это понимание исходит от машины.
# Добро пожаловать на официальную общедоступную учетную запись WeChat aifaner: aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo