Узнайте о новом FlashMLA с открытым исходным кодом от DeepSeek в одной статье. Эти детали заслуживают внимания.

С сегодняшнего дня мы официально вступаем в Неделю открытого исходного кода DeepSeek.
Первая версия проекта DeepSeek с открытым исходным кодом, FlashMLA, была распространена по всей сети за очень короткий период времени. Всего за несколько часов проект набрал более 3,5 тысяч звезд и продолжает стремительно расти.
Хотя я знаю каждую букву во FlashMLA, я не могу понять их вместе. Не волнуйтесь, мы подготовили руководство по ускоренной работе FlashMLA.
▲
Организатор: Grok 3, проверено APPSO.
Пусть производительность H800 резко возрастет, каково происхождение FlashMLA?
Согласно официальному описанию, FlashMLA — это эффективное ядро декодирования MLA (Multi-Head Latent Attention), оптимизированное для графического процессора Hopper, которое поддерживает обработку последовательностей переменной длины и теперь запущено в производство.
FlashMLA может повысить эффективность вывода LLM (большая языковая модель) за счет оптимизации декодирования MLA и страничного кэша KV, особенно на высокопроизводительных графических процессорах, таких как H100/H800, для достижения максимальной производительности.
Говоря человеческим языком, FlashMLA — это передовая технология, специально разработанная для высокопроизводительных ИИ-чипов Hopper — «многоуровневое ядро декодирования внимания».
Звучит сложно, но, говоря простыми словами, это что-то вроде суперэффективного «переводчика», который позволяет компьютерам быстрее обрабатывать языковую информацию. Это позволяет компьютерам очень быстро обрабатывать языковую информацию различной длины.
Например, когда вы используете чат-бота, он может позволить вам отвечать на ваши разговоры быстрее и без задержек. Чтобы повысить эффективность, он в основном оптимизирует некоторые сложные вычислительные процессы. Это похоже на модернизацию «мозга» компьютера, чтобы сделать его умнее и эффективнее при обработке языковых задач.
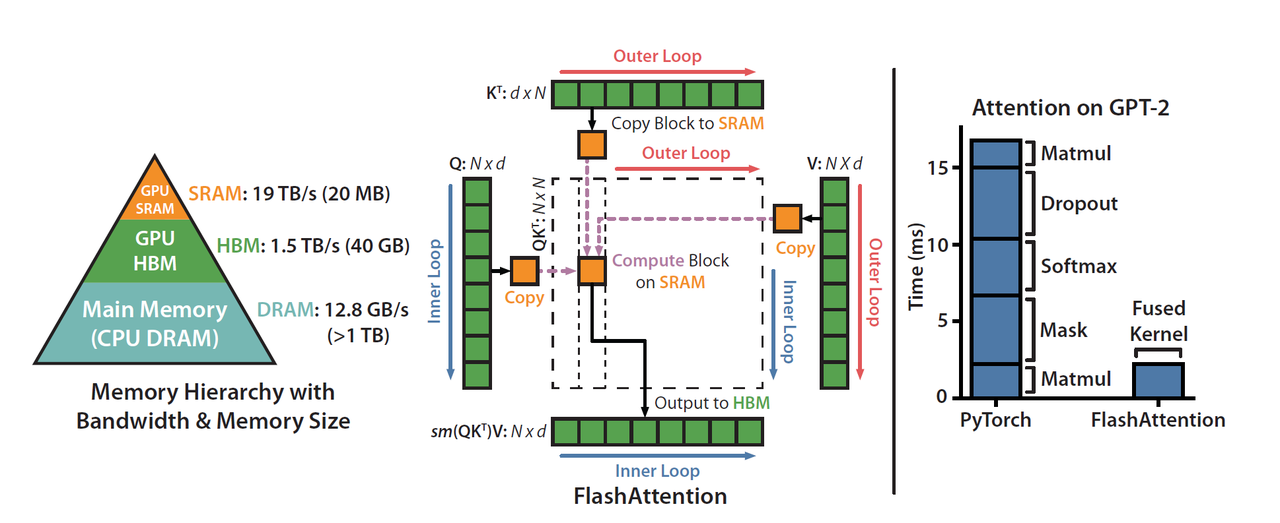
DeepSeek официально упомянул, что FlashMLA вдохновлен проектами FlashAttention 2&3 и Cutlass.
FlashAttention — это эффективный метод расчета внимания, специально оптимизированный для механизма самообслуживания моделей Transformer (таких как GPT и BERT). Его основная цель — уменьшить использование видеопамяти и ускорить вычисления. Cutlass также является инструментом оптимизации, который в основном помогает повысить эффективность вычислений.
Популярность DeepSeek во многом обусловлена созданием высокопроизводительных моделей при невысокой стоимости.
Секрет этого заключается главным образом в инновациях в архитектуре моделей и технологиях обучения, особенно в применении смешанных экспертов (MoE) и технологии скрытого внимания с несколькими головами (MLA).
Создание решений искусственного интеллекта с помощью DeepSeek: практический семинар – Ассоциация ученых по данным
FlashMLA — это версия реализации и оптимизации многоголовой технологии скрытого внимания (MLA), разработанной DeepSeek. Итак, вопрос в том, что такое механизм MLA (множественного скрытого внимания)?
В традиционных языковых моделях существует технология под названием «Multi-Head Attention (MHA)». Это позволяет компьютерам лучше понимать язык, подобно тому, как человеческий глаз может фокусироваться на нескольких местах одновременно.
Однако у этой технологии есть недостаток: для хранения информации требуется большой объем памяти, который представляет собой «склад», который можно загрузить, но если склад слишком велик, он будет тратить пространство.
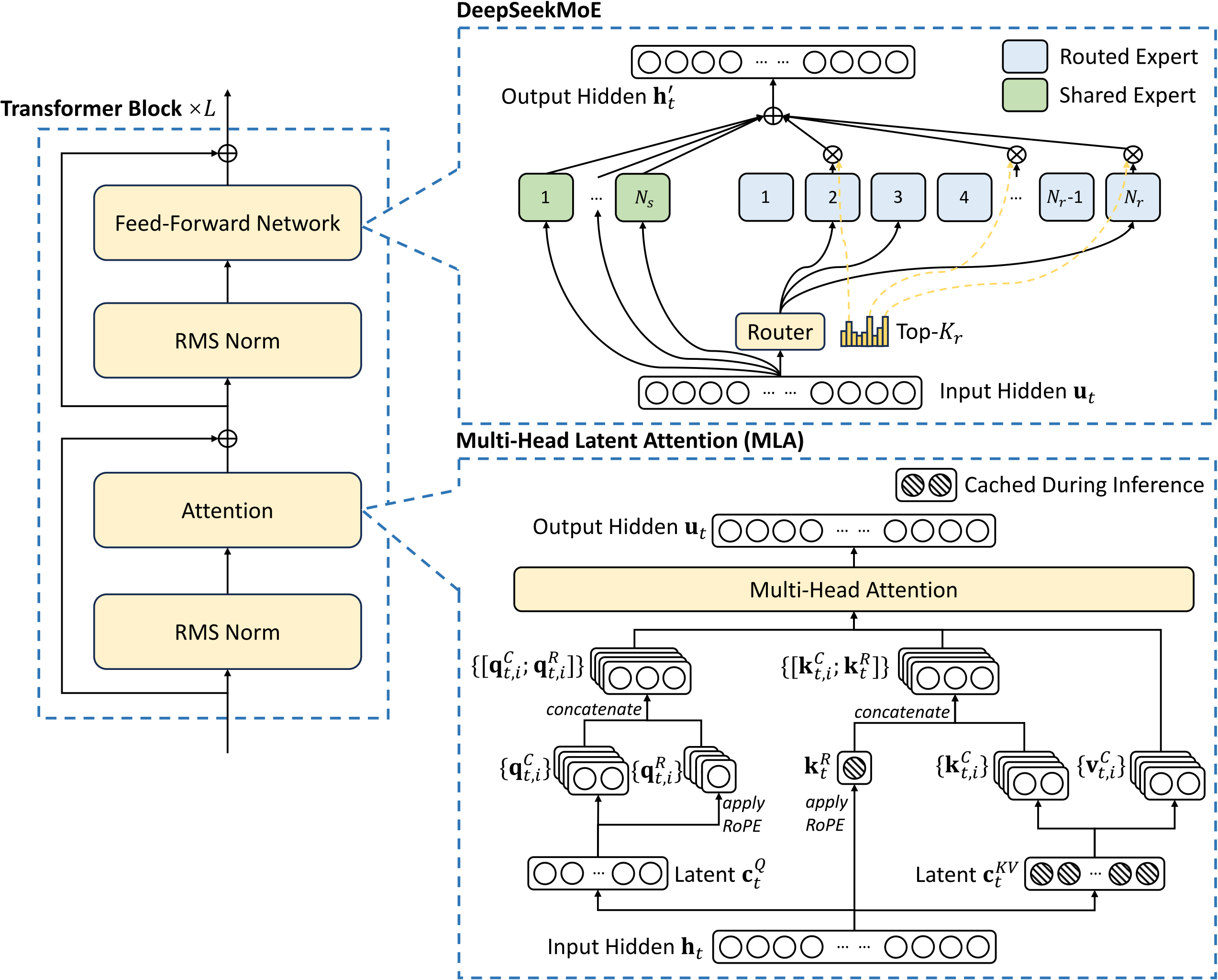
Обновление MLA заключается в методе, называемом «декомпозиция низкого ранга».
Он сжимает этот большой склад в маленький, но функция по-прежнему такая же хорошая, как и замена большого холодильника на маленький, но вещи внутри все равно можно хранить. Таким образом,
При обработке языковых задач это не только экономит место, но и делает это быстрее.
Однако, хотя MLA и сжала склад, ее рабочий эффект остается таким же хорошим, как и раньше, без каких-либо компромиссов.
Конечно, помимо MLA и MoE, DeepSeek также использует некоторые другие технологии для значительного снижения затрат на обучение и логические выводы, включая, помимо прочего, обучение с низкой точностью, стратегии балансировки нагрузки без вспомогательных потерь и прогнозирование нескольких токенов (MTP).
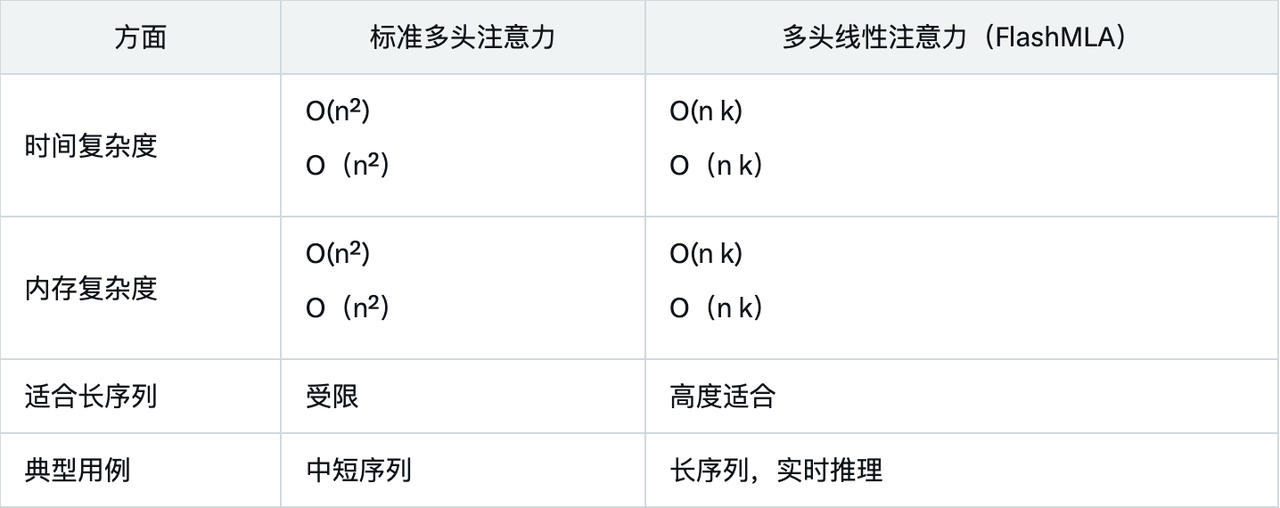
Данные о производительности показывают, что FlashMLA значительно превосходит традиционные методы при ограничении памяти и вычислительных ресурсов благодаря конструкции с линейной сложностью и оптимизации для графических процессоров Hopper.
Сравнение со стандартным многоголовым вниманием еще раз подчеркивает преимущества FlashMLA:
Основные сценарии применения FlashMLA включают в себя:
- Обработка длинных последовательностей: подходит для обработки текста с тысячами тегов, например для анализа документов или длинных разговоров.
- Приложения реального времени: такие как чат-боты, виртуальные помощники и системы перевода в реальном времени для сокращения задержек.
- Эффективность ресурсов: снижает требования к памяти и вычислительным ресурсам для простого развертывания на периферийных устройствах.
В настоящее время обучение и рассуждения ИИ в основном опираются на NVIDIA H100/H800, но экосистема программного обеспечения все еще совершенствуется.
Поскольку FlashMLA имеет открытый исходный код, в будущем его можно будет интегрировать в экосистему vLLM (эффективная среда вывода LLM), Hugging Face Transformers или Llama.cpp (облегченный вывод LLM), что, как ожидается, повысит эффективность работы больших языковых моделей с открытым исходным кодом (таких как LLaMA, Mistral, Falcon).
Те же ресурсы могут выполнить больше работы и сэкономить деньги.
Поскольку FlashMLA имеет более высокую вычислительную эффективность (580 терафлопс) и лучшую оптимизацию полосы пропускания памяти (3000 ГБ/с), те же ресурсы графического процессора могут обрабатывать больше запросов, тем самым снижая затраты на вывод единиц.
Для компаний, занимающихся искусственным интеллектом, или поставщиков услуг облачных вычислений, использование FlashMLA означает снижение затрат и более быстрый вывод, что принесет прямую выгоду большему числу компаний, занимающихся искусственным интеллектом, академическим учреждениям и корпоративным пользователям, а также улучшит использование ресурсов графического процессора.
Кроме того, исследователи и разработчики могут осуществлять дальнейшую оптимизацию на основе FlashMLA.
В прошлом эти эффективные технологии оптимизации вывода ИИ обычно находились в руках таких гигантов, как OpenAI и NVIDIA. Но теперь, благодаря открытому исходному коду FlashMLA, небольшие компании, занимающиеся искусственным интеллектом, или независимые разработчики также могут использовать его.
Короче говоря, если вы являетесь практиком или разработчиком искусственного интеллекта и недавно использовали H100/H800 для обучения или вывода LLM, то FlashMLA может стать проектом, заслуживающим внимания или исследования.
Подобно тому, как пользователи сети раскрыли подробности PTX в статье DeepSeek V3 во время Весеннего фестиваля, пользователи сети X обнаружили, что проект FlashMLA, выпущенный DeepSeek, также содержит строку встроенного кода PTX.
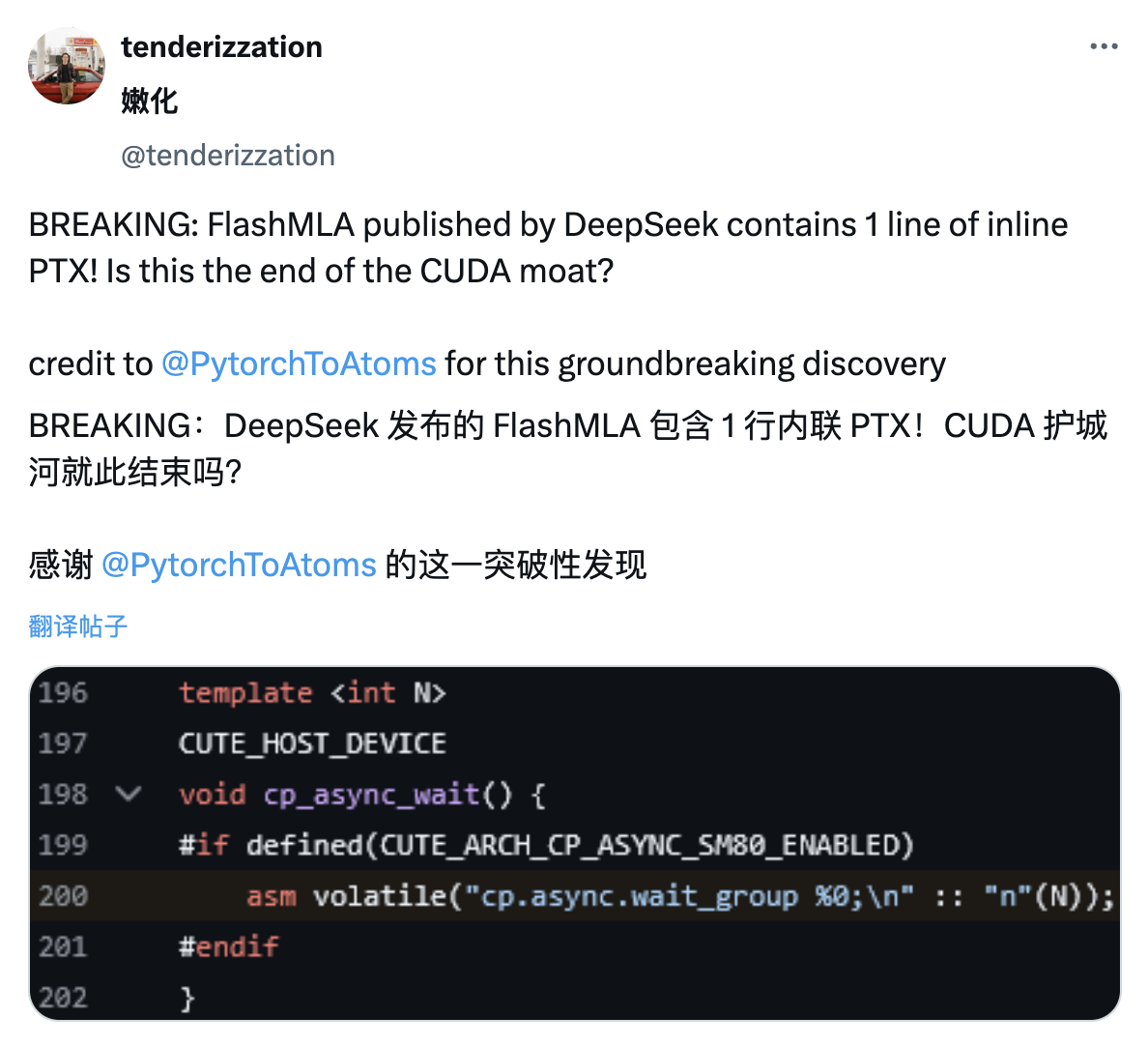
PTX — это промежуточная архитектура набора команд платформы CUDA, расположенная между языками программирования графических процессоров высокого уровня и машинным кодом низкого уровня. Ее часто рассматривают как один из технических рвов NVIDIA.
Встраивание PTX позволяет разработчикам более точно контролировать процесс выполнения графического процессора, потенциально достигая более эффективной производительности вычислений.
Кроме того, прямое использование базовых функций графических процессоров NVIDIA без необходимости полностью полагаться на CUDA также поможет уменьшить технические барьерные преимущества NVIDIA в области программирования графических процессоров.
Другими словами, это также может означать, что DeepSeek намеренно обходит закрытую экосистему Nvidia.
Конечно, если не произойдет ничего неожиданного, по сообщениям зарубежных СМИ, на следующей неделе ожидается выход таких моделей, как GPT-4.5 и Claude 4. На этой неделе может развернуться война ИИ, которой не было в конце прошлого года.
Не так уж и сложно наблюдать за весельем, начинать драку, начинать драку.
Официальное руководство по развертыванию
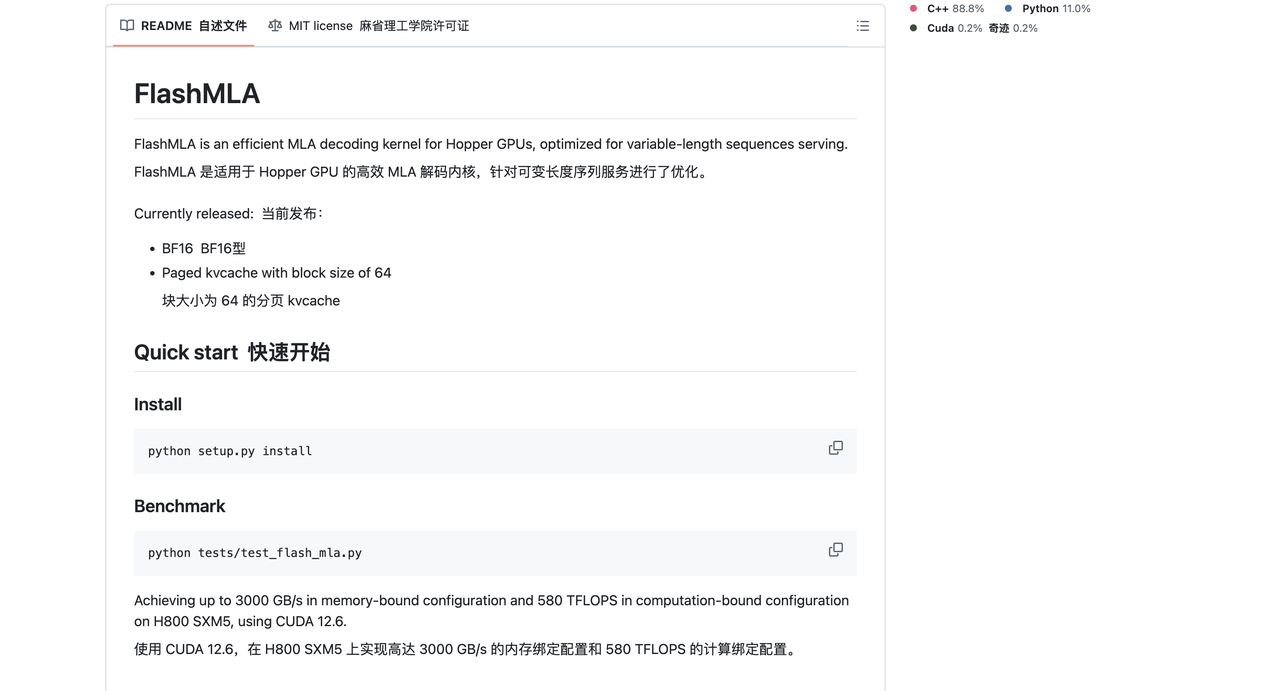
FlashMLA — это эффективное ядро декодирования MLA, оптимизированное для графических процессоров Hopper и может использоваться для обработки вывода последовательностей переменной длины.
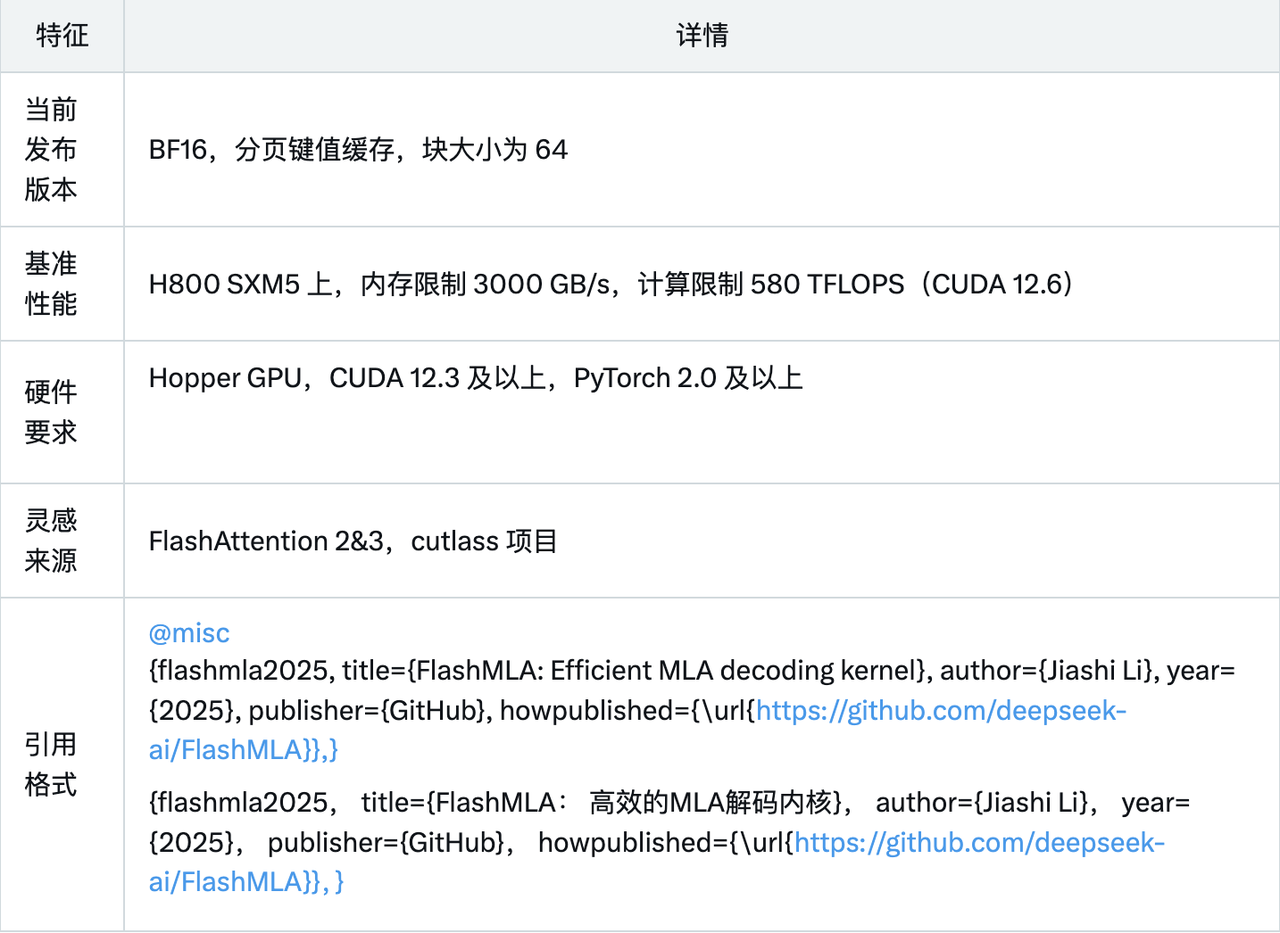
Текущая выпущенная версия поддерживает:
- БФ16
- Страничный кэш KV, размер блока 64
При использовании CUDA 12.6 на H800 SXM5 FlashMLA может достигать скорости 3000 ГБ/с в конфигурации, ограниченной пропускной способностью памяти, и до 580 терафлопс в конфигурации, ограниченной вычислительной мощностью.
Проектное оборудование:
- Бункерный графический процессор
- CUDA 12.3 и выше
- PyTorch 2.0 и выше
Прикреплен адрес проекта GitHub:
https://github.com/deepseek-ai/FlashMLA
Установить
установка python setup.py
эталон
тесты Python/test_flash_mla.py
pythontest/test_flash_mla.py — это инструкция командной строки, используемая для запуска тестового файла Python test_flash_mla.py, обычно используемого для тестирования функций или модулей, связанных с flash_mla.
из импорта flash_mla get_mla_metadata, flash_mla_with_kvcache
tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)
для меня в диапазоне (num_layers):
…
о_и, lse_i = flash_mla_with_kvcache(
q_i, kvcache_i, block_table, кэш_seqlens, dv,
tile_scheduler_metadata, num_splits, causal=True,
)
…
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo