Я использовал новую функцию ChatGPT, чтобы отредактировать изображение и отправить его в «Моменты», но во всех личных сообщениях меня спрашивали, как это сделать?
Когда рано утром OpenAI выпустила новое поколение графической функции Винсента, никто не был уверен в ее преимуществах. Они думали, что он последовал за Gemini и принес с собой несколько поздних обновлений.
GPT ничего не сказала, а просто шокировала аудиторию своими кейсами использования.

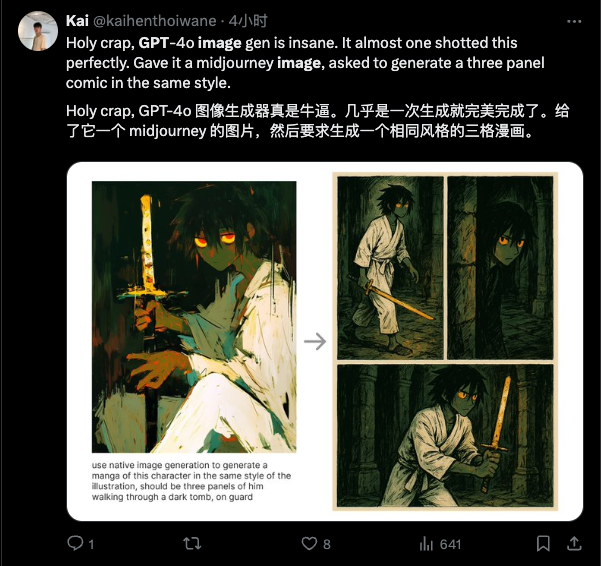
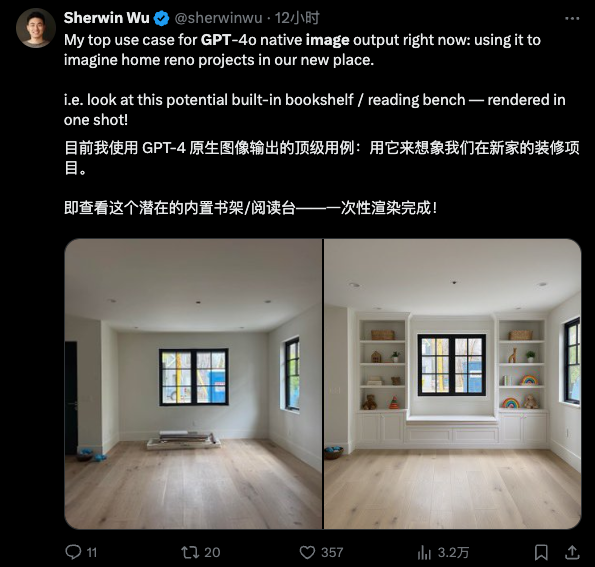
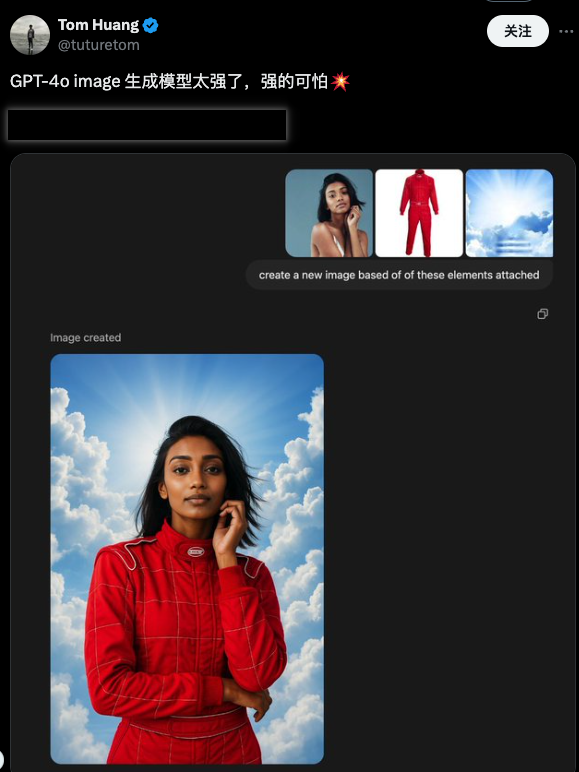
В своей последней версии OpenAI обеспечивает революционное соответствие инструкциям и стабильную производительность функциональности винсентианских графов. С помощью простейшей текстовой подсказки можно добиться высокоточной настройки деталей изображения — все изменения необходимо вносить только в сеансе , без каких-либо дополнительных операций типа кнопок или кистей.
Магия не требует кистей, только заклинания
Как и в случае с Gemini, в этом обновлении OpenAI основное внимание уделяется не тому, насколько реалистичными и сложными могут быть изображения, а соблюдению и последовательности инструкций, и это подразумевает использование только инструкций на естественном языке.
Давайте сначала посмотрим на набор фотографий еды начального уровня. Подсказка также очень проста: создайте изображение кофе и хлеба.

Позже, основываясь на исходной картинке, я попросил заменить ее на кофе со льдом и намазать джемом.

За исключением ручки чашки, я добавил то, что нужно было добавить, и оставил то, что нужно было исключить, и инструкции были соблюдены очень хорошо.
Снимки с портретами также имеют стабильную производительность.

Если присмотреться, небольшие изменения все же есть, но самые важные движения человеческого тела, морщины на одежде и выражения лиц безупречны.
При создании этого набора изображений я столкнулся с контролем рисков контента и получил сообщение об ошибке, сообщающее, что он не соответствует требованиям политики. Однако оно понимало цель первоначальной директивы и предлагаемых изменений.

Последний также имеет лучший и наиболее естественный эффект.
Задачи с простым содержимым экрана, естественно, легко понять, но как насчет более сложных?
В предыдущем фототесте Gemini мы создали сцену городской улицы, и эффект был потрясающим. Взгляните еще раз:

Тот же запрос был выполнен в ChatGPT, но эффект изображения был немного хуже, особенно ночью, когда детали толпы были почти неразличимы.

Конечно, эта проблема больше связана с эстетическими различиями. Нет проблем с определением ключевых элементов. Он может даже фиксировать мелкие детали, такие как «Книжный магазин Цутая», а генерация шрифтов также довольно стабильна.
Помимо непосредственной генерации текста, вы также можете загружать картинки для модификации — вот и самый шокирующий эпизод.
После загрузки логотипа APPSO в формате png первым делом нужно просто изменить его на 3D.

Эффект нормальный, направление тени неоднородно, но соответствует самому свету. Далее внесите некоторые коррективы.

Шокирует! Подсказки для этих двух настроек состоят всего из двадцати слов.

(Даже цифровые продукты по умолчанию производятся Apple, а некоторые неупомянутые атрибуты действительно скрыты.)
Последующая доводка под малыми углами также очень точна.

▲ Подсказка: отрегулируйте угол так, чтобы красный логотип стал фронтальным, а все остальное осталось без изменений.
Детальная точная настройка — очень важная особенность этого обновления, которая позволяет точно связывать инструкции с соответствующими деталями для выполнения точных локальных модификаций.

▲ Подсказка: отрегулируйте угол, объектив снимает спереди справа, общий свет тускнеет, луч яркого света освещает часть машины справа, рядом с ней кофейные зерна
Инструкции включают ключевое содержание, такое как световые эффекты, ракурсы камеры и дополнения к элементам. Модель можно точно идентифицировать и целостно скорректировать. Я устал говорить о том, какие четыре слова изменить.
Самым удивительным в этом обновлении должна стать возможность быстрого переключения между необработанными изображениями и необработанным текстом в одном сеансе.
Например, на рисунке ниже самая ранняя инструкция — создать руководство по упаковке подарков.

Первым делом была предоставлена картинка и текстовая версия – что не является ошибкой. Я не уточнил, хочу ли я сделать фото-текстовую версию или текстовую версию. Инструкции были очень расплывчатыми.
После создания текстовой версии ChatGPT заранее спросил, хочет ли он создать графическую версию. После получения ответа-подтверждения он предоставил графическую версию.

Это означает, что точная реакция модели отражается не только в понимании одной инструкции, но также в понимании потенциальных намерений пользователя и «мышлении на шаг больше», чем пользователь .
Фактически, это также способность, продемонстрированная Deep Research, когда она была выпущена ранее. Глубокий поиск OpenAI — одна из немногих моделей, которая активно просит пользователей уточнить детали выполнения задачи.
На этот раз аналогичные возможности были перенесены в необработанные изображения. С точки зрения пользовательского опыта они более интуитивны и ощутимы, чем у Deep Research.
Например, его можно использовать для создания ежедневных уведомлений и инструкций с изображениями и текстами в одном месте.
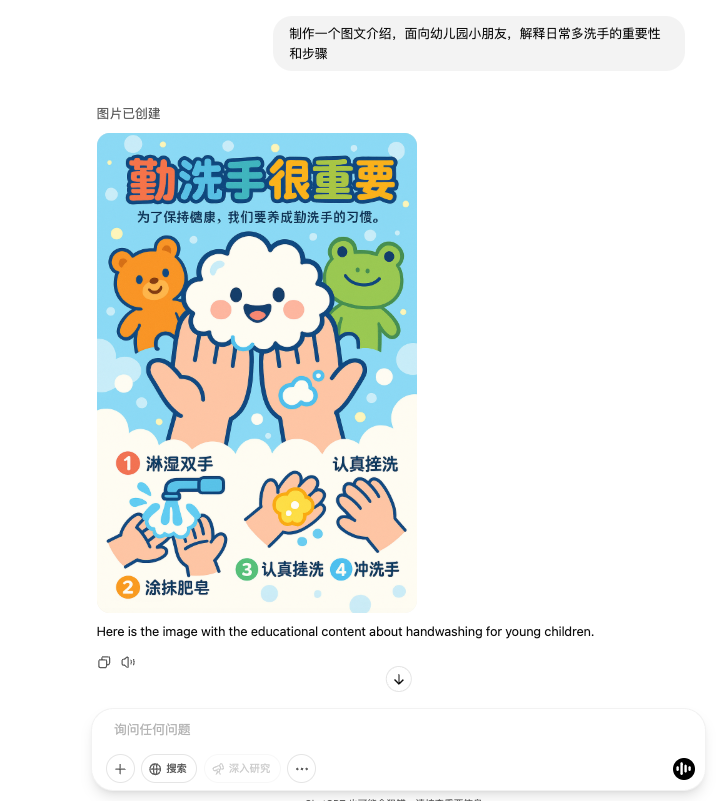
В целом, самое удивительное на этот раз, наверное, — это синхронизация последовательности и следования инструкциям.
Как обычно, в каждом обзоре должно быть несколько «руководств по использованию» — на этот раз я действительно не нашел никаких мер предосторожности. Все, что вам нужно сделать, это следовать своим собственным идеям, нажимать на клавиатуру и вводить текст. Никаких «хитростей» или «хитростей» нет.
Последовательность создания и изменения рисунков с помощью подсказок — очень важная проблема в рисовании Винсента. Это связано как с возможностями модели, так и с инженерными возможностями. До того, как соблюдение и последовательность инструкций достигли такого большого прогресса, эта проблема решалась в основном с помощью подсказок, и давление оказывалось на стороне пользователя .
Поэтому будут различные шаблоны-подсказки и стратегии, которые научат вас «обращаться с моделями». Но это не то состояние, в котором должно находиться взаимодействие на естественном языке. Когда модель сталкивается с людьми, она принимает только самые прямые инструкции от пользователя, позволяя людям сначала научиться писать подсказки, что действительно обескураживает.
Недавние обновления Gemini и OpenAI сделали трек по созданию фотографий, который стал менее популярным, снова оживился. Они также демонстрируют одно и то же: прошли те времена, когда некоторые продукты для модификации изображений повышали управляемость необработанных изображений путем добавления кнопок и входов для борьбы с иллюзией моделей .
Проблема согласованности решает не только проблему генерации изображений, но и мелкие неприятности в процессе «использования функции генерации изображений». В каком-то смысле это тоже оптимизация инженерного уровня.
Модификация и генерация могут быть достигнуты с помощью точного понимания моделью текстовых инструкций — на этом уровне по-прежнему сохраняется принцип «модель — это продукт».
# Добро пожаловать на официальную общедоступную учетную запись WeChat Айфанера: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo