5 истин о DeepSeek, которые были неправильно поняты, раскрыты самим ИИ-боссом

Давайте рассмотрим это еще раз: Сяохун полагается на поддержку, а большой красный полагается на жизнь.
DeepSeek стал популярным во время Весеннего фестиваля, и, естественно, когда он станет популярным, проблем будет больше. Китайское происхождение DeepSeek вызвало множество слухов, особенно в связи со сложными изменениями в зарубежной ситуации.
Танишк Мэтью Абрахам, бывший директор по исследованиям Stability AI, вчера выступил вперед и указал на несколько особых моментов DeepSeek как инсайдер отрасли:
1. Производительность на самом деле такая же хорошая, как у OpenAI o1, передовой модели, которая свидетельствует о том, что открытый исходный код действительно догнал закрытый исходный код.
2. По сравнению с другими передовыми моделями, DeepSeek требует относительно низких затрат на обучение.
3. Простой в использовании интерфейс в сочетании с видимыми цепочками мыслей на веб-сайте и в приложениях привлекает миллионы новых пользователей.
Кроме того, он написал длинный пост в блоге в ответ на несколько популярных слухов, анализируя и объясняя (возмутительные) высказывания в адрес DeepSeek.
Ниже приводится сообщение в блоге с отредактированным содержанием:
20 января 2025 года китайская компания, занимающаяся искусственным интеллектом, под названием DeepSeek открыла исходный код и выпустила свою модель вывода R1. Учитывая, что DeepSeek — китайская компания, у США и их компании AGI возникают различные «проблемы национальной безопасности». Из-за этого широко распространилась **дезинформация о нем. **
Цель этой статьи — опровергнуть множество крайне плохих мнений, связанных с ИИ, которые сложились о DeepSeek с момента его выпуска. В то же время, как исследователь ИИ, работающий на переднем крае генеративного ИИ, я предлагаю более сбалансированную точку зрения.
Слух 1: Подозрительно! DeepSeek — внезапно появившаяся китайская компания
Совершенно неверно: к январю 2025 года почти каждый исследователь генеративного ИИ услышит о DeepSeek. DeepSeek даже выпустил предварительную версию R1 за несколько месяцев до ее полного выпуска!
Любой, кто распространяет этот слух, вероятно, не работает в сфере искусственного интеллекта — смешно и чрезвычайно тщеславно думать, что вы знаете все, что нужно знать, если вы не участвуете в этой области.
Первая модель DeepSeek с открытым исходным кодом, DeepSeek-Coder, была выпущена в ноябре 2023 года. В то время это были ведущие в отрасли программы LLM по кодированию (примечание редактора: языковые модели ориентированы на понимание и создание кода). Как показано на диаграмме ниже, DeepSeek продолжал поставляться в течение года, достигнув уровня R1: 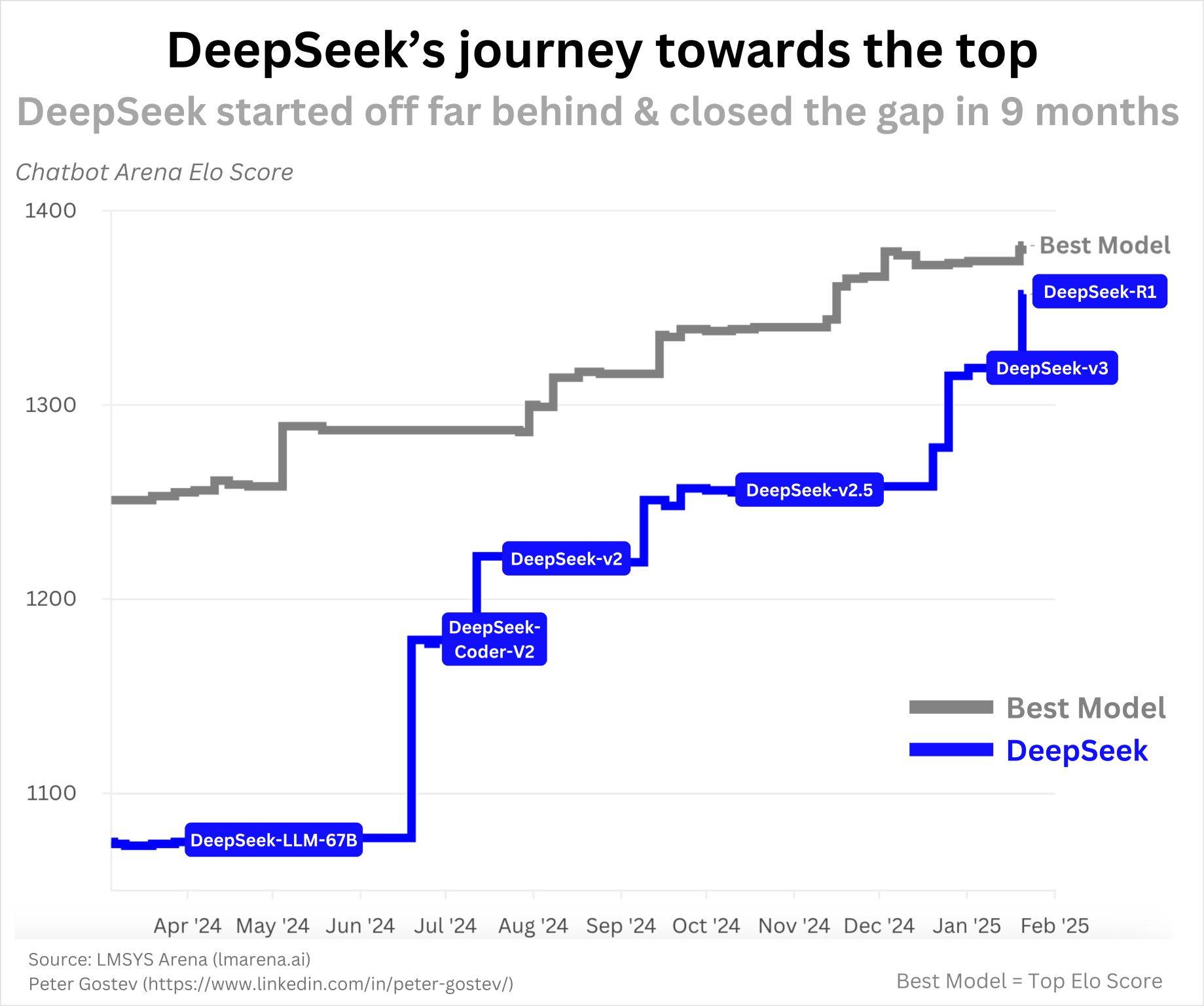
Это не был мгновенный успех, и нет ничего подозрительного в темпах их прогресса. Поскольку ИИ развивается так быстро и у них явно эффективная команда, такой прогресс за год кажется мне очень разумным.
Если вы хотите знать, какие компании находятся вне поля зрения общественности, но весьма перспективны в сфере искусственного интеллекта, я бы рекомендовал обратить внимание на Qwen (Alibaba), YI (Zero Yiwu), Mistral, Cohere, AI2. Важно отметить, что они не выпускают модели SOTA так последовательно, как DeepSeek, но у них обоих есть потенциал выпуска отличных моделей, как они продемонстрировали в прошлом.
Слух 2: Ложь! Эта модель не стоит 6 миллионов долларов.
Это интересный вопрос. Подобные слухи предполагают, что DeepSeek хотела избежать признания того, что у них были незаконные закулисные сделки по получению вычислительных ресурсов, к которым у них не должно быть доступа (из-за экспортного контроля), тем самым лгая о правде о стоимости обучения моделей.
Во-первых, цифра в 6 миллионов долларов заслуживает внимательного рассмотрения. Об этом упоминается в документе DeepSeek-V3, выпущенном за месяц до статьи DeepSeek-R1:

DeepSeek-V3 — это базовая модель DeepSeek-R1, что означает, что DeepSeek-R1 — это DeepSeek-V3 с дополнительным обучением с подкреплением. Таким образом, в некоторой степени стоимость уже является неточной, поскольку не учтены дополнительные затраты на обучение с подкреплением. Но это, вероятно, будет стоить всего несколько сотен тысяч долларов.
Итак, 5,5 миллионов долларов, упомянутые в документе DeepSeek-V3, это неверно? Многочисленные анализы, основанные на стоимости графического процессора, размере набора данных и размере модели, дали аналогичные оценки. Обратите внимание: хотя DeepSeek V3/R1 представляет собой модель с 671 миллиардами параметров, это экспертная смешанная модель, что означает, что любые вызовы функций/переходы модели используют только ~37 миллиардов параметров, что является значением, используемым для расчета стоимости обучения.
Однако стоимость DeepSeek представляет собой оценку стоимости этих графических процессоров, основанную на текущих рыночных ценах. На самом деле мы не знаем стоимость их кластера графических процессоров 2048 H800 (примечание: не H100, это распространенное заблуждение и путаница!). Обычно смежные кластеры графических процессоров стоят дешевле при покупке оптом, поэтому они могут быть даже дешевле.
Но вот в чем загвоздка: в конечном итоге это стоимость его эксплуатации. Прежде чем это удалось, многие эксперименты и абляции, вероятно, проводились в небольших масштабах, что потребовало бы значительных затрат, но здесь об этом не сообщается.
Помимо этого, может быть много других затрат, например, зарплата исследователя. SemiAnaлиз сообщает, что зарплата исследователей DeepSeek, по слухам, составляет около 1 миллиона долларов. Это эквивалентно высоким уровням зарплат в передовых лабораториях AGI, таких как OpenAI или Anthropic.
Обычно при составлении отчета и сравнении затрат на обучение для различных моделей наибольшую озабоченность вызывает окончательная стоимость выполнения обучения. Но из-за плохой риторики и распространения дезинформации люди утверждают, что дополнительные расходы ставят под сомнение недорогой и эффективный характер операций DeepSeek. Это крайне несправедливо. Затраты значительны, как с точки зрения абляции/экспериментов, так и с точки зрения вознаграждения исследователей в других передовых лабораториях AGI, но они часто не упоминаются в подобных обсуждениях!
Слух 3: Так дешево? Все американские AGI-компании тратят деньги, пессимистично настроенные по отношению к Nvidia
Я думаю, что это еще одна довольно глупая идея. DeepSeek действительно более эффективен в обучении, чем многие другие программы LLM. Да, вполне возможно, что многие из передовых лабораторий Америки являются вычислительно неэффективными. Однако это не обязательно означает, что иметь больше вычислительных ресурсов — это плохо.
Честно говоря, всякий раз, когда я слышу подобные мнения, мне становится ясно, что они не понимают ни законов масштабирования, ни образа мышления генерального директора AGI (и любого, кого считают экспертом в области ИИ). Позвольте мне высказать некоторые мысли на эту тему.
Законы масштабирования показывают, что, пока мы продолжаем вкладывать в модель больше вычислительной мощности, мы будем получать более высокую производительность. Конечно, точные методы и аспекты масштабирования ИИ со временем изменились: сначала размер модели, затем размер набора данных, а теперь вычисление времени вывода и синтетические данные.
Общая тенденция увеличения вычислительной мощности, равной лучшей производительности, похоже, продолжается со времен оригинального Transformer в 2017 году.
Более эффективная модель означает, что вы получаете более высокую производительность при заданном бюджете вычислений, но чем больше вычислительных ресурсов, тем лучше. Более эффективная модель означает, что вы можете делать больше, используя меньше вычислительных ресурсов, но делать больше, используя больше вычислительных ресурсов!
У вас может быть собственное мнение о законах масштабирования. Вы можете подумать, что наступает плато. Вы можете подумать, что прошлые результаты не являются показателем будущих результатов, как говорят в финансовом мире.
Но что, если все крупнейшие компании AGI делают ставку на то, что законы масштабирования продлятся достаточно долго, чтобы сделать возможным AGI и ASI. По их твердому убеждению, единственный логический путь действий — это приобретение большей вычислительной мощности.
Теперь вы можете подумать: «Графические процессоры NVIDIA скоро устареют, посмотрите на AMD, Cerebras, Graphcore, TPU, Trainium и т. д.». Существуют миллионы аппаратных продуктов, ориентированных на искусственный интеллект, и все они пытаются конкурировать с NVIDIA. Кто-то из них может победить в будущем. В этом случае, возможно, к ним и обратятся эти AGI-компании — но к успеху DeepSeek это не имеет абсолютно никакого отношения.
Лично я не думаю, что есть убедительные доказательства того, что другие компании будут оспаривать доминирование NVIDIA в чипах для ускорения искусственного интеллекта, учитывая текущее доминирование NVIDIA на рынке и продолжающийся уровень инноваций.
В целом, я не понимаю, почему DeepSeek предполагает, что вы должны быть настроены по-медвежьи в отношении NVIDIA. У вас могут быть и другие причины для медвежьего отношения к NVIDIA, и эти причины могут быть очень вескими и обоснованными, но мне DeepSeek не кажется подходящим.
Слух 4: Это всего лишь имитация! DeepSeek не внес никаких значимых инноваций
ошибка. **В разработке языковых моделей и методах обучения появилось много инноваций, некоторые из которых более важны, чем другие**. Вот некоторые из них (не полный список, более подробную информацию можно прочитать в статьях DeepSeek-V3 и DeepSeek-R1):
Многоголовое скрытое внимание (MLA). LLM обычно относятся к трансформаторам, которые используют так называемый механизм многоголового внимания (MHA). Команда DeepSeek разработала вариант механизма MHA, который более эффективно использует память и обеспечивает лучшую производительность.
GRPO и проверяемые вознаграждения. Специалисты по искусственному интеллекту пытаются воспроизвести o1 с момента его выпуска. Поскольку OpenAI довольно скрытно рассказывает о том, как он работает, людям приходилось изучать множество различных методов для достижения результатов, подобных o1. Были различные попытки, такие как поиск по дереву Монте-Карло (метод, используемый Google DeepMind для победы в Го), который оказался менее многообещающим, чем предполагалось изначально.
DeepSeek демонстрирует, что очень простой конвейер обучения с подкреплением (RL) действительно может достичь результатов, подобных o1. В дополнение к этому они разработали собственный вариант общего алгоритма PPO RL, называемый GRPO, который более эффективен и работает лучше. Думаю, многие в сообществе ИИ задаются вопросом, почему мы не попробовали это раньше?
DualPipe. При обучении модели ИИ на нескольких графических процессорах следует учитывать множество аспектов эффективности. Вам необходимо выяснить, как модель и набор данных распределяются по всем графическим процессорам, как данные проходят через графические процессоры и т. д. Вам также необходимо сократить передачу данных между графическими процессорами, поскольку она очень медленная и, если это возможно, лучше всего обрабатываться на каждом отдельном графическом процессоре. Тем не менее, существует множество способов настройки такого типа обучения с несколькими графическими процессорами, и команда DeepSeek разработала новое, более эффективное и быстрое решение под названием DualPipe.
Нам очень повезло, что DeepSeek полностью открыла исходный код этих инноваций и написала подробные описания, в отличие от американской компании AGI. Теперь каждый может извлечь выгоду из этих инновационных способов улучшить обучение собственной модели ИИ.
Слух 5: DeepSeek «черпает» знания из ChatGPT
Дэвид Сакс (гигант ИИ и криптографии при правительстве США) и OpenAI утверждают, что DeepSeek «осушил» знания ChatGPT с помощью метода, называемого дистилляцией.
Во-первых, здесь очень странно использовано слово «дистилляция». Обычно под дистилляцией подразумевается обучение полным вероятностям (логитам) всех возможных следующих слов (токенов), но эту информацию невозможно раскрыть даже через ChatGPT.
Но ладно, давайте просто скажем, что мы говорим об обучении с использованием текста, сгенерированного ChatGPT, хотя это не типичное использование этого термина.
OpenAI и ее сотрудники утверждают, что DeepSeek сам использует ChatGPT для генерации текста и обучения на нем. Никаких доказательств они не предоставили, но если это правда, то DeepSeek явно нарушил условия обслуживания ChatGPT. Я думаю, что юридические последствия для китайской компании неясны, но я мало что об этом знаю.
Обратите внимание, что это происходит только в том случае, если DeepSeek сам сгенерировал данные, используемые для обучения. Если DeepSeek использует данные, сгенерированные ChatGPT, из других источников (в настоящее время существует множество общедоступных наборов данных), насколько я понимаю, такая «перегонка» или синтетическое обучение данных не запрещено TOS.
Тем не менее, на мой взгляд, это не умаляет достижений DeepSeek. Что впечатлило меня как исследователя больше, чем эффективность DeepSeek, так это то, как они копировали o1. Я очень сомневаюсь, что «дистилляция» ChatGPT поможет. Это сомнение полностью проистекает из того факта, что мыслительный процесс o1 CoT никогда не был обнародован, так как же DeepSeek может его изучить?
Более того, многие LLM действительно обучены ChatGPT (как и другие LLM), и, естественно, в любом новом интернет-контенте, естественно, будет текст AI.
В целом, полагать, что модель DeepSeek работает хорошо просто потому, что она просто отражает точку зрения ChatGPT, значит игнорировать реальность инженерных, эффективных и архитектурных инноваций DeepSeek.
Стоит ли нам беспокоиться по поводу гегемонии Китая в области искусственного интеллекта?
Может быть, немного? Честно говоря, по сравнению с тем, что было два месяца назад, китайско-американское соревнование по искусственному интеллекту по сути не сильно изменилось. Напротив, реакция внешнего мира довольно жесткая, что действительно может повлиять на общий ландшафт ИИ через изменения в финансировании, надзоре и т. д.
Китайцы всегда были конкурентоспособны в области искусственного интеллекта, и теперь DeepSeek делает их невозможными игнорировать.
Типичный аргумент в пользу открытого исходного кода заключается в том, что, поскольку Китай отстает, мы не должны открыто делиться нашими технологиями, чтобы позволить им догнать их. Но очевидно, что Китай догнал, они действительно догнали давным-давно, они фактически лидируют в области открытого исходного кода, поэтому неясно, действительно ли дальнейшее ужесточение наших технологий так сильно поможет.
Обратите внимание, что у таких компаний, как OpenAI, Anthropic и Google DeepMind, модели определенно лучше, чем у DeepSeek R1. Например, результаты тестов модели OpenAI o3 весьма впечатляют, и, возможно, у них уже есть последующая модель в разработке.
Основываясь на этом фундаменте и благодаря значительным дополнительным инвестициям, таким как Project Stargate и предстоящему раунду финансирования OpenAI, OpenAI и другие передовые лаборатории США будут иметь достаточные вычислительные мощности для сохранения своих лидирующих позиций.
Конечно, Китай вложит значительные дополнительные средства в развитие ИИ. В общем, конкуренция накаляется! Но я думаю, что путь для передовых лабораторий AGI в США оставаться впереди по-прежнему весьма многообещающий.
в заключение
С одной стороны, некоторые специалисты по искусственному интеллекту, особенно из OpenAI, пытаются преуменьшить значение DeepSeek. С другой стороны, некоторые критики и самопровозглашенные эксперты слишком остро отреагировали на DeepSeek.
Следует отметить, что OpenAI/Anthropic/Meta/Google/xAI/NVIDIA и т. д. на этом не закончены. Нет, DeepSeek (вероятно) не лгал о том, что они сделали. В любом случае, надо признать: DeepSeek заслуживает признания, R1 — впечатляющая модель.
https://www.tanishq.ai/blog/posts/deepseek-delusions.html
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo