Apple работает с Nvidia, чтобы сделать ИИ более отзывчивым

Недавно Apple и NVIDIA объявили о сотрудничестве по ускорению и оптимизации производительности вывода больших языковых моделей (LLM).
Чтобы улучшить низкую эффективность и малую пропускную способность традиционных рассуждений авторегрессии LLM, ранее в этом году исследователи машинного обучения Apple выпустили и открыли исходный код спекулятивной технологии декодирования под названием « ReDrafter » (Recurrent Drafter, циклическая черновая модель).
▲Источник: GitHub
В настоящее время ReDrafter интегрирован в масштабируемое решение NVIDIA TensorRT-LLM . Последнее представляет собой библиотеку с открытым исходным кодом, основанную на платформе глубокого обучения TensorRT, предназначенную для оптимизации вывода LLM и поддерживающую спекулятивное декодирование, включая метод Medusa.
Однако, поскольку алгоритмы, включенные в ReDrafter, используют операторы, которые никогда раньше не использовались, NVIDIA добавила новые операторы или представила существующие операторы, что значительно улучшает адаптируемость TensorRT-LLM к сложным моделям и методам декодирования.
▲Источник: GitHub
Сообщается, что спекулятивное декодирование ReDrafter ускоряет процесс рассуждения LLM за счет трех ключевых технологий :
- Проект модели РНС
- Алгоритм динамического внимания дерева
- Обучение дистилляции знаний
Черновой вариант модели RNN является «основным» компонентом ReDrafter. Он использует рекуррентную нейронную сеть для прогнозирования последовательности токенов, которые могут появиться следующими, на основе «скрытого состояния» LLM. Он может улавливать зависимость от местного времени, тем самым повышая точность прогнозирования.
Принцип работы этой модели таков: LLM сначала генерирует начальный токен в процессе генерации текста, а затем черновой вариант модели RNN использует токен и последнее скрытое состояние LLM в качестве входных данных для выполнения поиска луча (Beam Search), а затем генерирует последовательность нескольких токенов-кандидатов.
В отличие от традиционного авторегрессионного LLM, который генерирует только один токен за раз, ReDrafter может генерировать несколько токенов на каждом этапе декодирования посредством прогнозных результатов черновой модели RNN, что значительно сокращает количество раз, когда необходимо вызывать проверку LLM, тем самым улучшая общая скорость рассуждений.
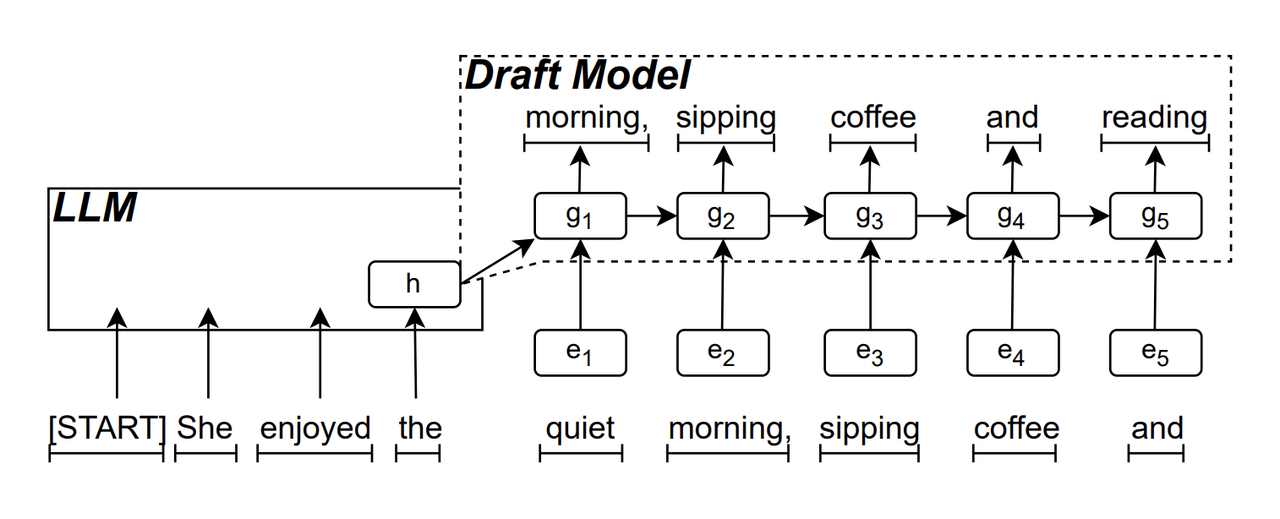
▲Источник изображения: arXiv
Динамическое дерево внимания — это алгоритм, оптимизирующий результаты поиска лучей.
Мы уже знаем, что в процессе поиска луча будет сгенерировано несколько последовательностей-кандидатов, и эти последовательности часто имеют общие префиксы. Алгоритм динамического внимания к дереву идентифицирует эти общие префиксы и удаляет их из токенов, требующих проверки, тем самым уменьшая объем данных, которые LLM необходимо обрабатывать.
В некоторых случаях этот алгоритм может сократить количество токенов, которые необходимо проверить, на 30–60%. Это означает, что после использования алгоритма динамического внимания к дереву ReDrafter может более эффективно использовать вычислительные ресурсы и дополнительно повысить скорость вывода.
▲Источник изображения: NVIDIA
Дистилляция знаний — это технология сжатия моделей, которая может «перерабатывать» знания из большой и сложной модели (модель учителя) в меньшую и более простую модель (модель ученика). В ReDrafter черновой вариант модели RNN служит моделью студента и учится на основе LLM (модели учителя) посредством дистилляции знаний.
В частности, в процессе обучения дистилляции LLM предоставит серию «распределений вероятностей» следующих возможных слов. Разработчики обучат черновую модель RNN на основе этих данных распределения вероятностей, а затем вычислят разницу между распределениями вероятностей этих двух слов. модели и минимизировать эту разницу с помощью алгоритмов оптимизации.
В этом процессе черновая модель RNN постоянно изучает режим вероятностного прогнозирования LLM, чтобы в практических приложениях генерировать текст, аналогичный LLM.
Благодаря обучению по дистилляции знаний черновой вариант модели RNN лучше отражает законы и закономерности языка, тем самым более точно прогнозируя выходные данные LLM, и значительно повышает производительность ReDrafter на ограниченном оборудовании из-за его меньшего размера и более низкой общей производительности вычислений. в условиях.
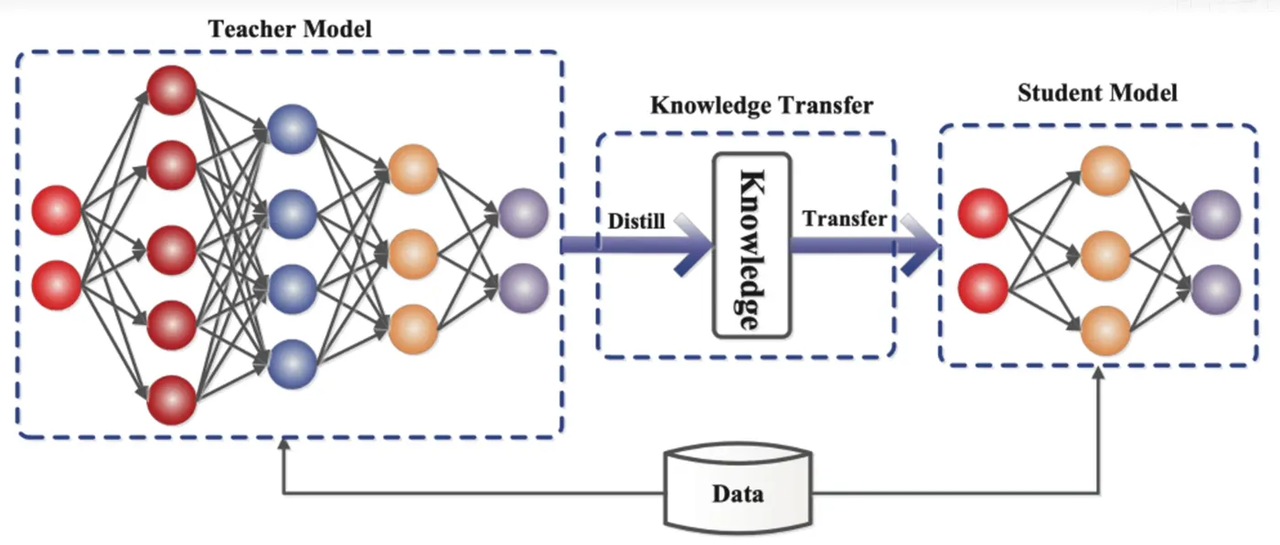
▲Источник изображения: сообщество разработчиков облака Alibaba.
Результаты тестов Apple показывают, что при использовании TensorRT-LLM, интегрированного с ReDrafter, на производственной модели с миллиардами параметров на графическом процессоре NVIDIA H100 количество токенов, генерируемых в секунду с помощью Greedy Decoding, увеличилось в 2,7 раза.
Кроме того, ReDrafter может добиться увеличения скорости вывода в 2,3 раза на собственном графическом процессоре Apple M2 Ultra Metal. Исследователи Apple заявили, что «LLM все чаще используется для управления производственными приложениями, а повышение эффективности вывода может как повлиять на вычислительные затраты, так и снизить задержку на стороне пользователя».
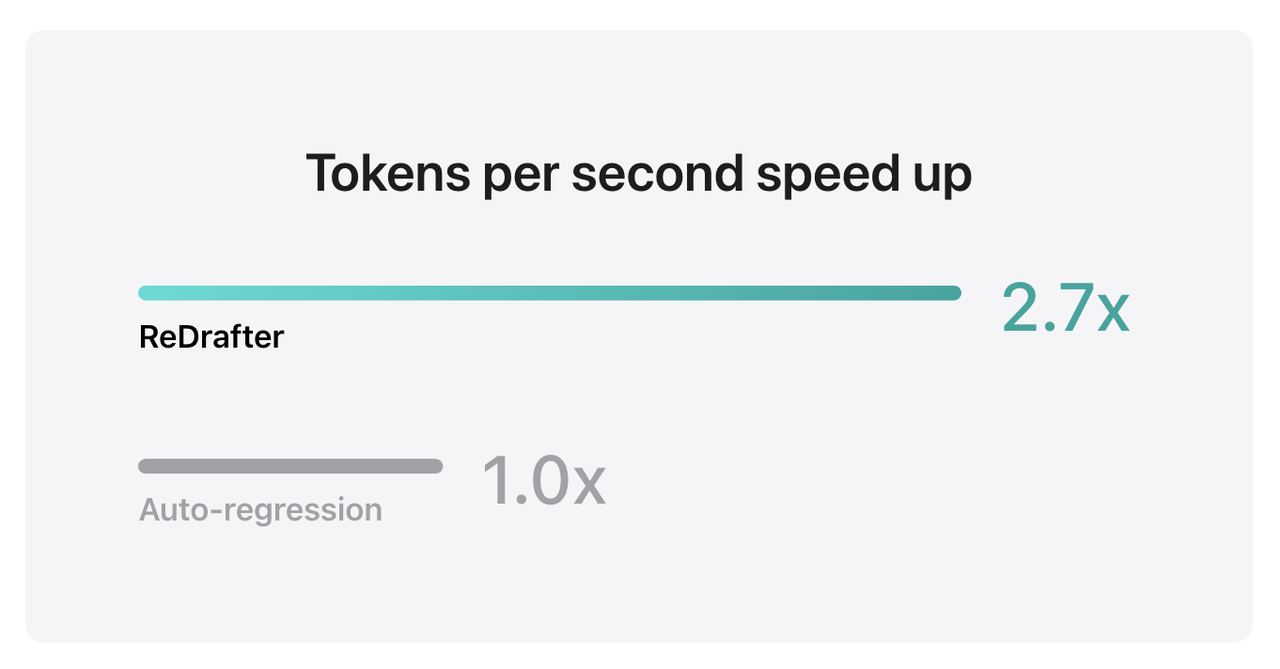
▲Источник: Apple
Стоит отметить, что, сохраняя качество вывода, ReDrafter снижает потребность в ресурсах графического процессора, что позволяет LLM эффективно работать в средах с ограниченными ресурсами и предоставляет возможности для использования LLM на различных аппаратных платформах. Новые возможности.
Apple теперь выложила исходный код этой технологии на GitHub, и Nvidia, вероятно, будет единственной компанией, которая выиграет от нее в будущем.
# Добро пожаловать на официальную общедоступную учетную запись WeChat aifaner: aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo