С этой отечественной версией модели о1 я хочу дожить до конца в “Игре Кальмар”

Насколько далеки мы от ИИ, который думает как люди?
В научно-фантастическом романе Дугласа Адамса «Автостопом по галактике» раса, живущая в высоких широтах, проектирует суперкомпьютер «Глубокая мысль» для вычислений и поиска окончательного ответа на вопросы жизни, Вселенной и всего остального.
«Глубокая мысль» пришла к ответу «42» после 7,5 миллионов лет вычислений.
Самая научная фантастика часто оказывается реальностью. Даже чтобы ответить на чрезвычайно сложные вопросы, рассуждения и размышления ИИ могут занять менее 1 минуты.
После того, как OpenAI выпустила модель вывода o1 в сентябре этого года, люди начали понимать, что после стремления к «большему» ИИ начал стремиться к «большему подобному», и способность к рассуждению стала следующим важным поворотным моментом в эволюции ИИ.

Сегодня мы обнаружили, что Zhipu, известная как «китайская версия OpenAI», также запустила модель вывода GLM-Zero-Preview, подобную o1 (первая версия GLM-Zero).
Хотя в последние месяцы многие компании запустили модели вывода, после знакомства с GLM-Zero-Preview я обнаружил, что в ней все еще есть что-то новое.
Если вы хотите испытать GLM-Zero-Preview, метод очень прост.
GLM-Zero-Preview будет доступен в сети сразу после выпуска и поддерживает бесплатное использование пользователями Zhipu Qingyan, а также вызовы API открытой платформы Zhipu. Теперь войдите на веб-сайт и в приложение «Zhipu Qingyan», войдите в агент «Модель нулевого вывода» и загрузите текст или изображения, чтобы испытать его бесплатно.
Кроме того, одновременно на интеллектуальной открытой платформе bigmodel.cn был запущен API GLM-Zero-Preview.
Прилагаем адрес опыта:
Ясные слова мудрости
https://chatglm.cn/main/gdetail/676411c38945bbc58a905d31?lang=zh
Открытая платформа Жипу
https://bigmodel.cn/dev/api/normal-model/glm-zero-preview
От «игры в кальмаров» до квантовой механики — эта отечественная версия o1 проста в обращении.
В последнее время в популярной корейской драме «Игра в кальмара 2» игра «камень-ножницы-бумага» для двух рук проста и увлекательна. Эта игра добавляет стратегические рассуждения и психологическую игру. Под давлением жизни и смерти сложность возрастает.

Но если я сыграю в эту игру с GLM-Zero-Preview, вероятность выживания значительно увеличится.
«Двуручный камень, ножницы, бумага» — это более сложная версия игры «Камень, ножницы, бумага». Игроки начинают с обеих рук, представляющих любую комбинацию камня, ножниц или бумаги. Увидев выбор противника, игрок должен поднять одну руку в то же время, Оставь окончательный выбор».
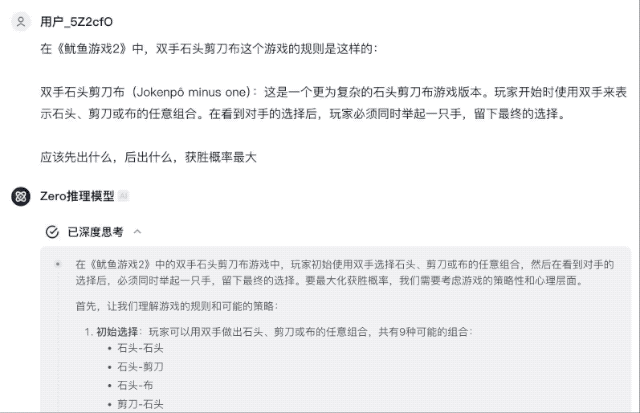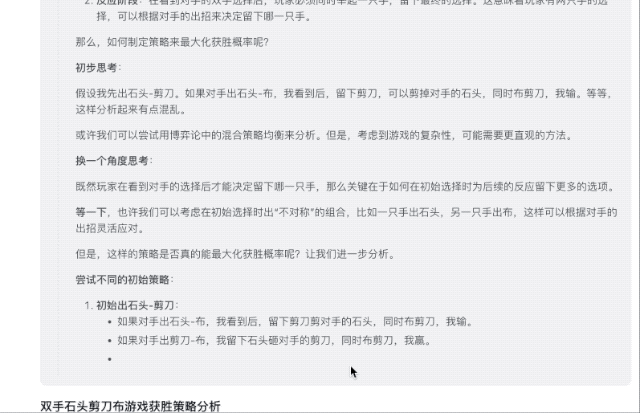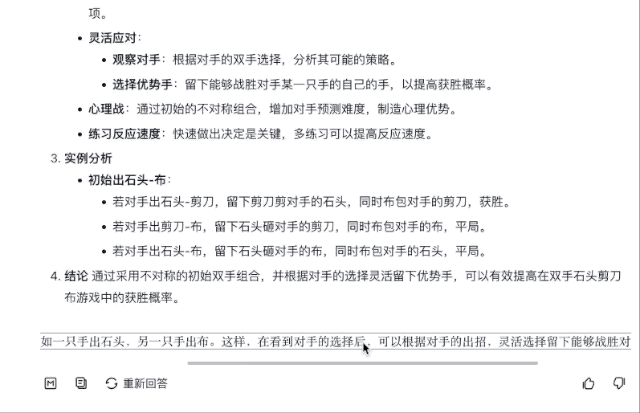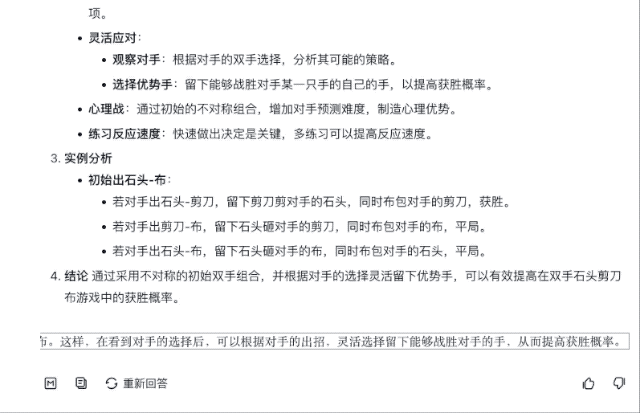
Как играть в эту игру, чтобы увеличить вероятность выигрыша? Ответы GLM-Zero-Preview подробные и практичные, в них перечислены различные оптимальные решения для повышения эффективности выигрыша.
Иногда существует тонкая грань между наукой и метафизикой. В этом году многие храмы были переполнены. Люди предпочитают предлагать благовония между работой и продвижением по службе. Подать заявление на получение визы несложно, но за ней стоит длинная очередь. Что мне делать, если я не хочу? ждать?
Тогда вы можете попробовать GLM-Zero-Preview. Он не только бесплатен и эффективен, но его интерпретация также очень сложна, а ИИ в некоторой степени метафизичен.

«Семьдесят седьмой признак причинения вреда императрицей Лу Хань Синь Чжунпину имеет свои корни. С этого момента вам следует исследовать источник и не следовать сплетням прохожих. Судебные разбирательства в конечном итоге приведут к катастрофе».

После разговора о метафизике поговорим о философии.
Несколько лет назад был популярный дискуссионный вопрос: «Горит художественный музей. Знаменитая картина или кот. Спасти можно только одного. Кого вы выберете, всесторонне обдумав ценность жизни, моральные принципы и принципы?» эмоциональные факторы, GLM-Zero -Preview Отдавайте приоритет спасению кошек.
Введите один и тот же вопрос снова и снова, и ответы GLM-Zero-Preview всегда последовательны, а результаты устойчивы и логически последовательны.

Если есть сомнения, существует квантовая механика. Итак, в классическом эксперименте Шредингера с кошкой кот жив или мертв?
Сначала обратите внимание на логику мышления GLM-Zero-Preview, а затем посмотрите на ответ, который она дает: «В классическом эксперименте с кошкой Шредингера кошка находится в состоянии суперпозиции как мертвого, так и живого, прежде чем коробка будет открыта, и она обретет жизнь. и состояние смерти не определяется до момента наблюдения».
Обратите пристальное внимание, и вы сможете далее цитировать и задавать вопросы по поводу полученных результатов.

«Загадка Эйнштейна», широко распространенная в китайском мире, также может быть использована для проверки способности GLM-Zero-Preview к логическому рассуждению.
Здесь пять домов разного цвета, и в каждом доме живет человек разной национальности. Каждый житель любит разные напитки, курит разные сигареты и держит разных домашних животных. Известно:
1. Британцы живут в красных домах.
2. Шведы держат собак.
3. Датчане пьют чай.
4. Зеленый дом расположен слева от белого дома.
5. Хозяин оранжереи пьет кофе.
6. Люди, которые курят сигареты Pall Mall, разводят птиц.
7. Хозяин желтого дома курит сигареты Dunhill.
8. В первом доме живут норвежцы.
9. Хозяин среднего дома пьет молоко.
10. Курильщик Blends живет по соседству с владельцем кошки.
11. Конезаводчик живет по соседству с курильщиком сигарет Dunhill.
12. Люди, которые курят сигареты Blue Master и пьют пиво.
13. Немцы курят сигареты Prince.
14. Дом, где живет норвежец, находится рядом с синим домом.
15. У мужчины, который курит сигареты Blends, есть сосед, который пьет воду.
Ответ таков: немцы выращивают рыбу. Не знаю, правы ли вы.
Этот сложный вопрос, на который, по мнению 98% людей в мире, нет ответа, был легко решен с помощью GLM-Zero-Preview. Из утомительных рассуждений видно, что процессор GLM-Zero-Preview работает быстро, но все еще не спит.

Давайте продолжим стремиться к победе и увеличим нашу интенсивность.
Пять пиратов обнаруживают 100 золотых монет, и каждый пират должен проголосовать за то, как распределить монеты. Если пиратов несколько, золотые монеты будут распределены таким образом только в том случае, если более половины пиратов согласятся с методом распределения. Если пиратов меньше одного, он заберет все золотые монеты сам. Каждый пират хочет сохранить как можно больше золотых монет, надеясь при этом остаться в живых. Пират 1 Как обеспечить максимальную выгоду, сохранив при этом свою жизнь.
«(97, 0, 1, 0, 2)», столкнувшись с проблемой дележа пиратского золота, GLM-Zero-Preview легко решил ее снова.

Перекрестные помехи подчеркивают речь и пение, и есть известная шутка под названием «Сообщение названия блюда».
Итак, вопрос в том, можете ли вы позволить GLM-Zero-Preview написать вегетарианскую версию «Сообщить название блюда» Не скажите, GLM-Zero-Preview выдал новую версию после трёх, пяти и двух раз?

Кстати, GLM-Zero-Preview также поддерживает возможности мультимодального распознавания.
Возьмите бутылку напитка и дайте GLM-Zero-Preview «просканировать» список ингредиентов. Сможет ли он определить технологию и тяжелую работу? Мы попробовали это с напитком, который стал популярным в последние несколько лет, и напиток тоже был? высмеивали как «Один глоток — это все равно, что выпить всю таблицу Менделеева элементов».
Как и ожидалось, он перечислял ингредиенты на экране один за другим, а затем по запросу показывал нам функции этих ингредиентов.

Не очень хорошо разбираетесь в математике с большими моделями? Отечественный ИИ вышел на новый уровень
Модель вывода GLM-Zero — это серия моделей GLM, ориентированная на расширение возможностей искусственного интеллекта. Она хороша для решения математической логики, кода и сложных задач, требующих глубоких рассуждений.
Начнем с задачи, которая одновременно проста и легка, и трудно сказать: «шахматная доска и пшеничные зерна».
Если зерна пшеницы размещены на шахматной доске, то на первое шахматное поле помещается 1 зерно. Количество зерен пшеницы, размещенных на каждом последующем шахматном поле, в два раза больше, чем на предыдущем шахматном поле. Сколько зерен пшеницы нужно, чтобы заполнить все. шахматные клетки на шахматной доске?
После некоторого размышления GLM-Zero-Preview наконец нашел правильный ответ, продемонстрировав свою мощную вычислительную мощность.
В предыдущей статье, опубликованной Apple, указывалось, что большие модели не совсем понимают математические концепции. Как только к вопросу добавятся условия помех, точность модели снизится. Мы тоже это попробовали.
От «Телефонный звонок стоит 10 центов за минуту, сколько стоит 60-минутный звонок» до «Первые 10 минут разговора стоят 10 центов за минуту, а затем 8 центов за минуту. Сколько стоит 60-минутный разговор?» стоимость минуты разговора?», GLM-Zero-Preview по-прежнему способен точно ответить, а также вдумчиво конвертирует копейки в доллары, что является своего рода подмигиванием.

GLM-Zero-Preview справится с более сложными математическими задачами.
Давайте сначала разогреемся реальным вопросом по математике для вступительного экзамена в колледж:
В арифметической последовательности {an}{an}, a1=−9a1=−9, a5=−1a5=−1. Помните Tn=a1+a2+…+an Tn=a1+a2+…+an, затем последовательность {Tn}{Tn} ( ).
А. Существует максимальный срок и минимальный срок
Б. Существует максимальный срок, но нет минимального срока
C. Максимального срока нет, но есть минимальный срок
D. Нет максимального срока, нет минимального срока
GLM-Zero-Preview Выбор C ни в коем случае не означает «ценить C во всем», а, скорее, обеспечивает процесс мышления и руководство, которые даже более полезны, чем некоторые машины обучения искусственного интеллекта.

Чиновники сообщили, что на вступительном экзамене в аспирантуру по математике № 1 в 2025 году балл GLM-Zero составил 126, что соответствует уровню выдающихся аспирантов.


Чтобы гарантировать правильные ответы, GLM-Zero-Preview также автоматически запускает процесс проверки.
«В обрабатывающем цехе машиностроительного завода работают 85 рабочих. В среднем каждый человек ежедневно обрабатывает 16 больших шестерен или 10 маленьких шестерен. Известно, что в комплекте подобраны 2 большие шестерни и 3 маленькие шестерни. Сколько рабочих нужно организовать обработку больших и маленьких шестерен, чтобы большие и маленькие шестерни, обрабатываемые каждый день, могли просто соответствовать друг другу?»

GLM-Zero быстро дал ответ: «Большую шестерню обрабатывают 25 рабочих, а мелкую — 60». Вопрос первоклассный.
Даже если у AMC возникнет еще одна сложная проблема, он легко с ней справится.
«Набор состоит из 6 (не различных) целых положительных чисел: 1, 7, 5, 2, 5 и X. Среднее (среднее арифметическое) 6 чисел равно одному значению в наборе. Все возможные значения из X Какова сумма?»
Эта задача включает в себя пять основных моментов и более десятка ситуаций. GLM-Zero-Preview всесторонне рассматривает различные возможности и выводит ее в один клик, создавая у меня ощущение, что она действительно имитирует человеческое мышление.

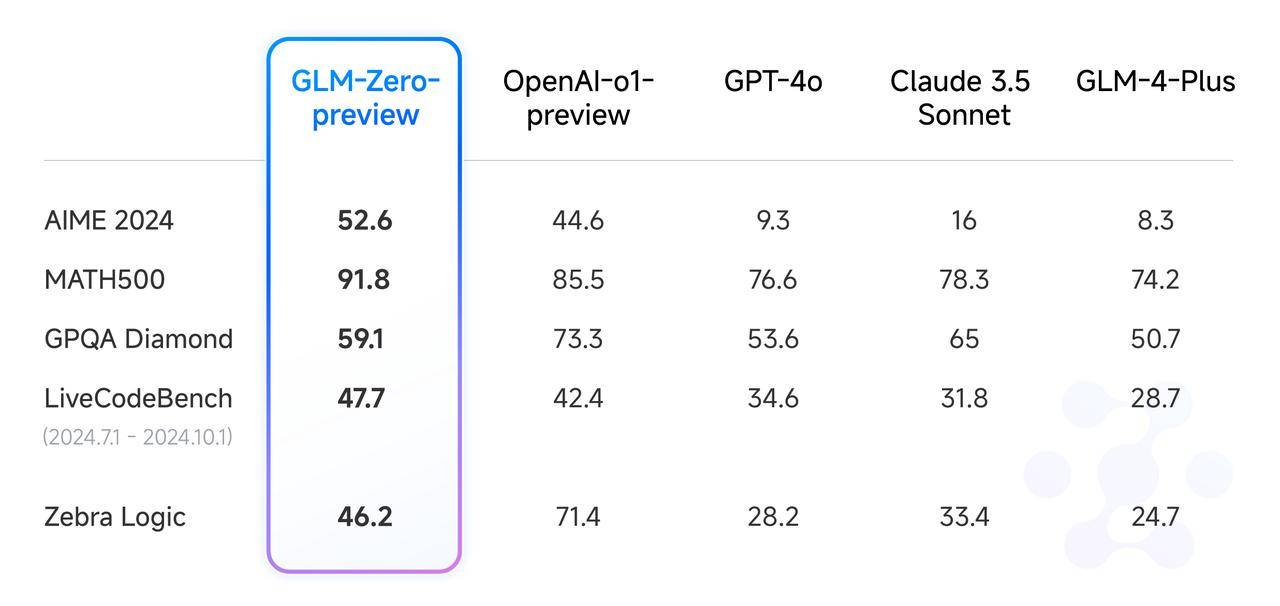
Будучи первой моделью вывода GLM, обученной на основе расширенной технологии обучения с подкреплением, GLM-Zero-Preview достигла результатов, эквивалентных OpenAI o1-preview в оценках AIME 2024, MATH500 и LiveCodeBench.
Кроме того, GLM-Zero-Preview также может умело использовать несколько языков программирования, чтобы помочь разработчикам быстро писать код с точки зрения отладки кода, а также быстро выявлять ошибки и давать подробные предложения по исправлению.
Например, вам нужно всего лишь ввести команду «Помогите мне написать интересный шутер от первого лица в html», и GLM-Zero-Preview сможет быстро и самостоятельно завершить следующую игру.

Zhipu вскоре выпустит официальную версию GLM-Zero, расширяющую возможности глубокого мышления от математической логики до более общих технологий и продолжающую движение к AGI.
Конечно, между нынешней GLM-Zero-Preview и моделью OpenAI o3 все еще существует много разрывов, но путь в тысячу миль начинается с одного шага. Жипу сказал, что технология итеративного обучения с подкреплением будет продолжать оптимизироваться в будущем.
Фактически, такие производители, как Zhipu, полностью делают ставку на модели вывода, что отражает переход эпохи GPT в эпоху вывода.
В отличие от предыдущих моделей, основанных на GPT, модель вывода не обучена предсказывать мысли человека, а строит собственную структуру мышления посредством тренировки «мышления» и делает выводы посредством строгого процесса рассуждения.
Наступление эры рассуждений знаменует собой то, что ИИ может начать переходить от «подражания» к «мышлению».
GLM-Zero-Preview, запущенный Zhipu, также является отражением этой тенденции.
Когда вы посмотрите, как он отвечает на вопросы, вы обнаружите, что он не дает ответов напрямую, а показывает полный процесс рассуждения – выдвижение гипотез, анализ условий и получение выводов. Каждый шаг углубленного мышления четко виден.
В будущем, по мере появления новых моделей, таких как o1 и GLM-Zero-Preview, ИИ сделает большой шаг к тому же когнитивному уровню, что и люди. Другими словами, мы также можем стать свидетелями важного исторического поворотного момента.
Цель Жипу — «заставить машины думать как люди». Когда машины начнут по-настоящему «думать», человеческое понимание интеллекта выйдет на новый уровень.
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo