iPad также может работать с моделями уровня GPT-4o. Новая модель отечественной небольшой стальной пушки может сделать оборудование искусственного интеллекта больше не бесполезным.

На только что завершившейся выставке CES 2025 тысячи аппаратных продуктов искусственного интеллекта подтвердили нерушимую отраслевую тенденцию, то есть искусственный интеллект с огромной скоростью перемещается из облака на каждое устройство вокруг нас, и каждая волна становится все больше и больше.
Можно сказать, что ИИ больше не является плюсом для продуктов, а является основой их возможностей.
Традиционным производителям, вложившим много усилий в аппаратное обеспечение, нелегко установить искусственный интеллект в небольшие терминальные устройства. К счастью, индустрия услуг моделей ИИ постепенно разделилась на два четких направления: облачный ИИ и ИИ на устройстве.

В первой области производители в лице OpenAI давно всем известны, а когда дело доходит до второй, особенно бросается в глаза одна компания — Wall-Intelligence. С самого начала они делали ставку на искусственный интеллект на стороне устройства, а теперь стали важным игроком, которого нельзя игнорировать в этой области.
Сегодня Face Wall Intelligence также официально выпустила новую модель MiniCPM-o 2.6.
Имея всего 8 миллиардов параметров, он может смотреть видео, слушать звуки, читать текст и красноречиво говорить, как люди. Более того, его реакция такая же быстрая, как и у человека, практически без задержек. Говоря более популярным языком, он может видеть глазами, слушать ушами, говорить ртом и думать мозгом, как человек.
Адрес MiniCPM-o 2.6 с открытым исходным кодом:
GitHub  https://github.com/OpenBMB/MiniCPM-o
https://github.com/OpenBMB/MiniCPM-o
Обнимающее лицо : https://huggingface.co/openbmb/MiniCPM-o-2_6
Настоящее видео, а не фото-макет
Когда мы говорим, что MiniCPM-o 2.6 — это «настоящая видеомодель», это не пустые разговоры. Будучи первым в мире локальным искусственным интеллектом, достигшим уровня GPT-4o, он демонстрирует возможности всестороннего восприятия, выходящие за рамки облачных моделей.
В официальной демо-версии игры «Три бессмертных возвращаются в пещеру» он может отслеживать положение мяча до того, как зрители зададут вопросы; при игре в карточную игру он может точно запомнить рисунок и положение каждой карты; .
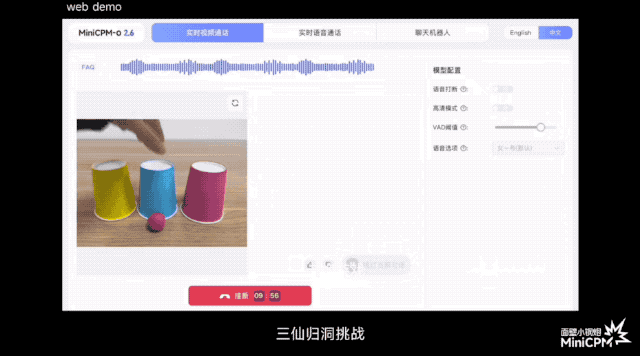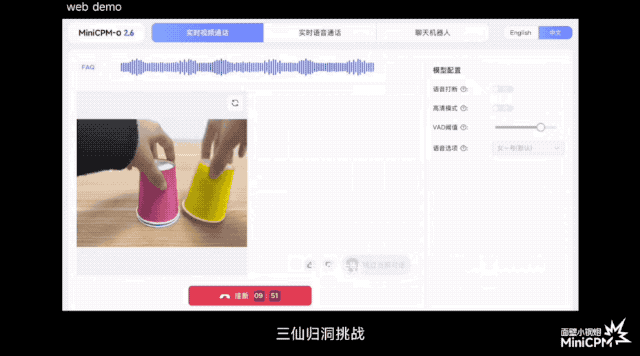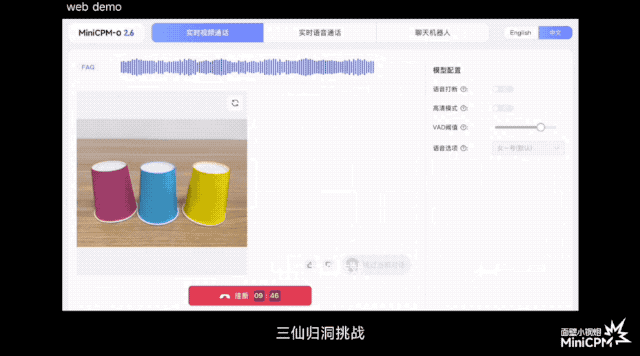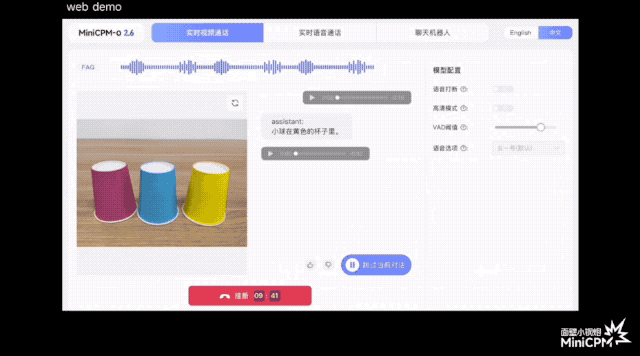
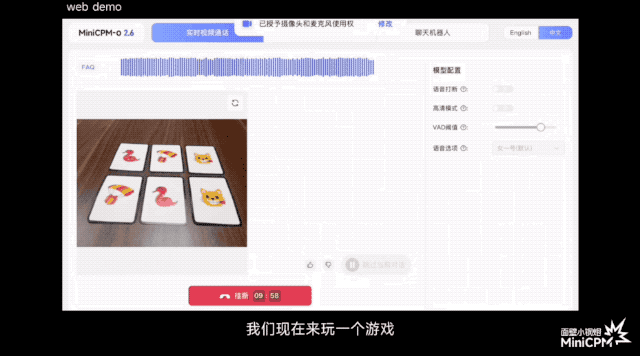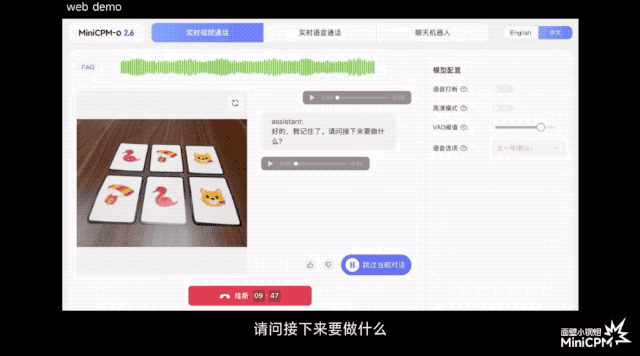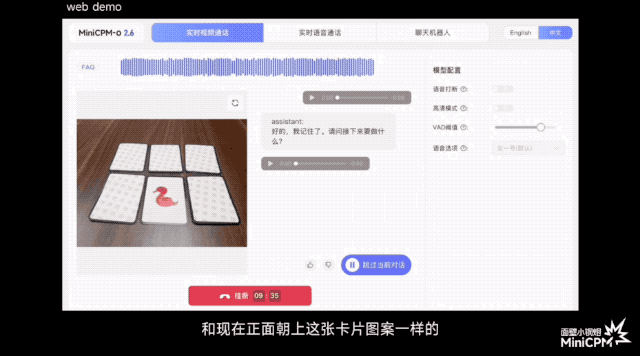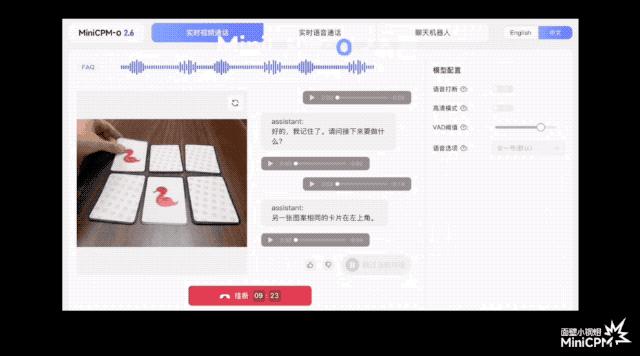
По сравнению с некоторыми моделями или продуктами на рынке, которые утверждают, что поддерживают понимание потокового видео в реальном времени, MiniCPM-o 2.6 может воспринимать изображения и звуки до того, как пользователь задаст вопросы, позволяя им слышать, видеть и чувствовать, и он ближе к естественное визуальное взаимодействие человеческого глаза.

Эта способность непрерывного наблюдения и понимания в реальном времени — это то, чего не могут достичь другие крупные фотомодели.
Давайте поговорим о звуках. MiniCPM-o 2.6 умеет не только понимать человеческую речь, но и различать фоновые звуки, отличные от человеческих голосов, например рвущуюся бумагу, льющуюся воду, удары металлов и другие звуки. И даже GPT-4o не может этого сделать.
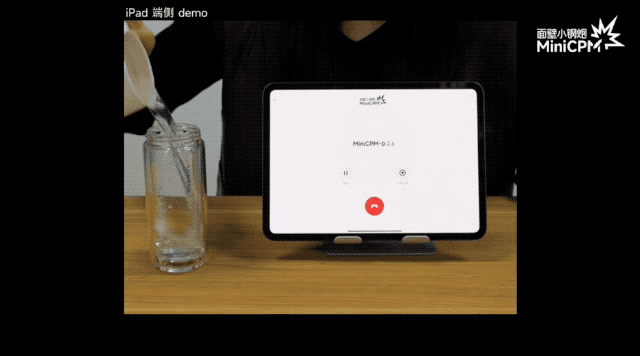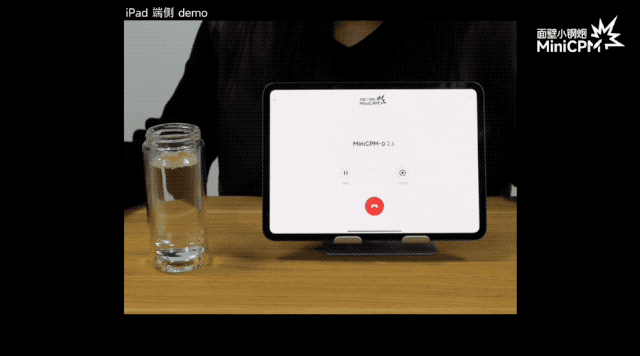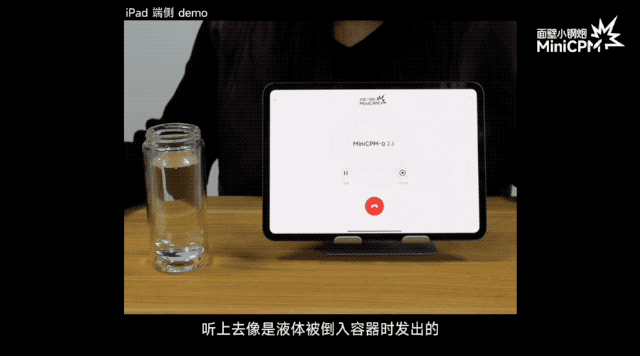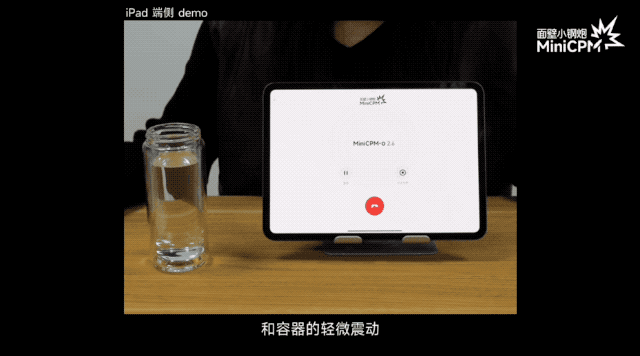
Одно и то же «Привет», произнесенное разными тонами, может быть теплым приветствием или холодным ответом.
Общение между людьми и ИИ должно быть настолько естественным.
Процесс традиционных моделей ИИ немного похож на другую форму «перевода», когда звуки сначала превращаются в текст, а затем снова превращаются в звуки. Таким образом теряются такие тонкие особенности, как акцент и эмоции говорящего.

Но MiniCPM-o 2.6 другой.
Как и человеческое ухо, оно может напрямую улавливать и понимать различные детали звука. Более того, он может при необходимости регулировать эмоции и стиль звука и даже имитировать определенные звуки или создавать совершенно новые звуки на основе описаний.
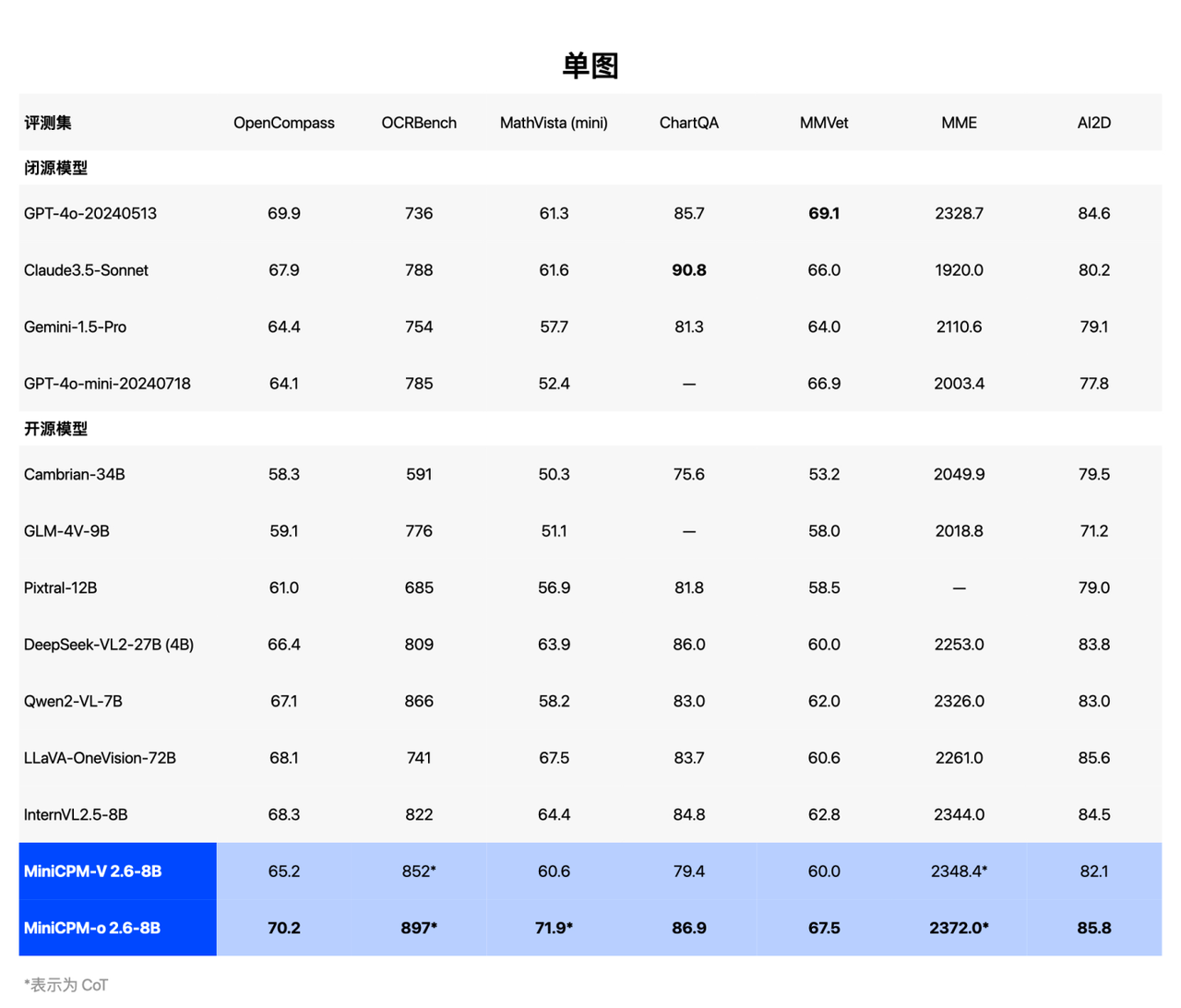
Превосходная производительность MiniCPM-o 2.6 в реальной жизни также была хорошо оценена в списке тестов производительности, и она достигла всех показателей SOTA в аудиовизуальном «триатлоне»:

MiniCPM-o 2.6 достиг полномодальной модели SOTA с открытым исходным кодом потоковой передачи в реальном времени, и его производительность сопоставима с GPT-4o и Claude-3.5-Sonnet, которые представляют самый высокий в мире уровень с точки зрения голоса, он достиг понимания; и создание двойной SOTA с открытым исходным кодом, стремящейся к созданию самой сильной универсальной модели голоса с открытым исходным кодом в области видения, где преимущества всегда были заметными, она прочно зарекомендовала себя как самая сильная общая модель сквозного видения;
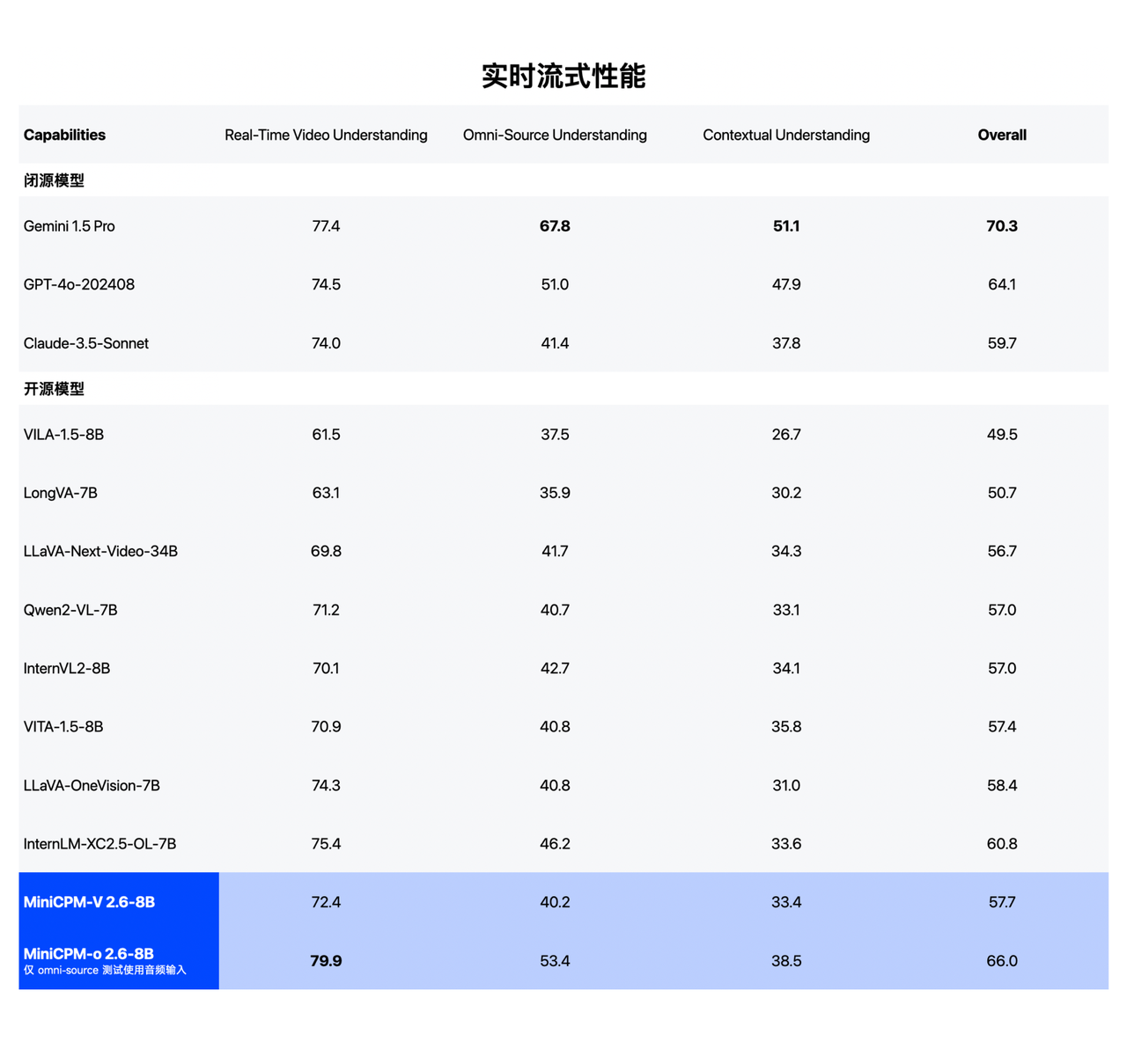
В StreamingBench, репрезентативном списке возможностей понимания потокового видео в реальном времени, производительность MiniCPM-o 2.6 также сопоставима с GPT-4o и Claude 3.5 Somnnet. Стоит отметить, что API GPT-4o не может одновременно вводить голос и видео. В настоящее время при количественной оценке вводятся текст и видео.
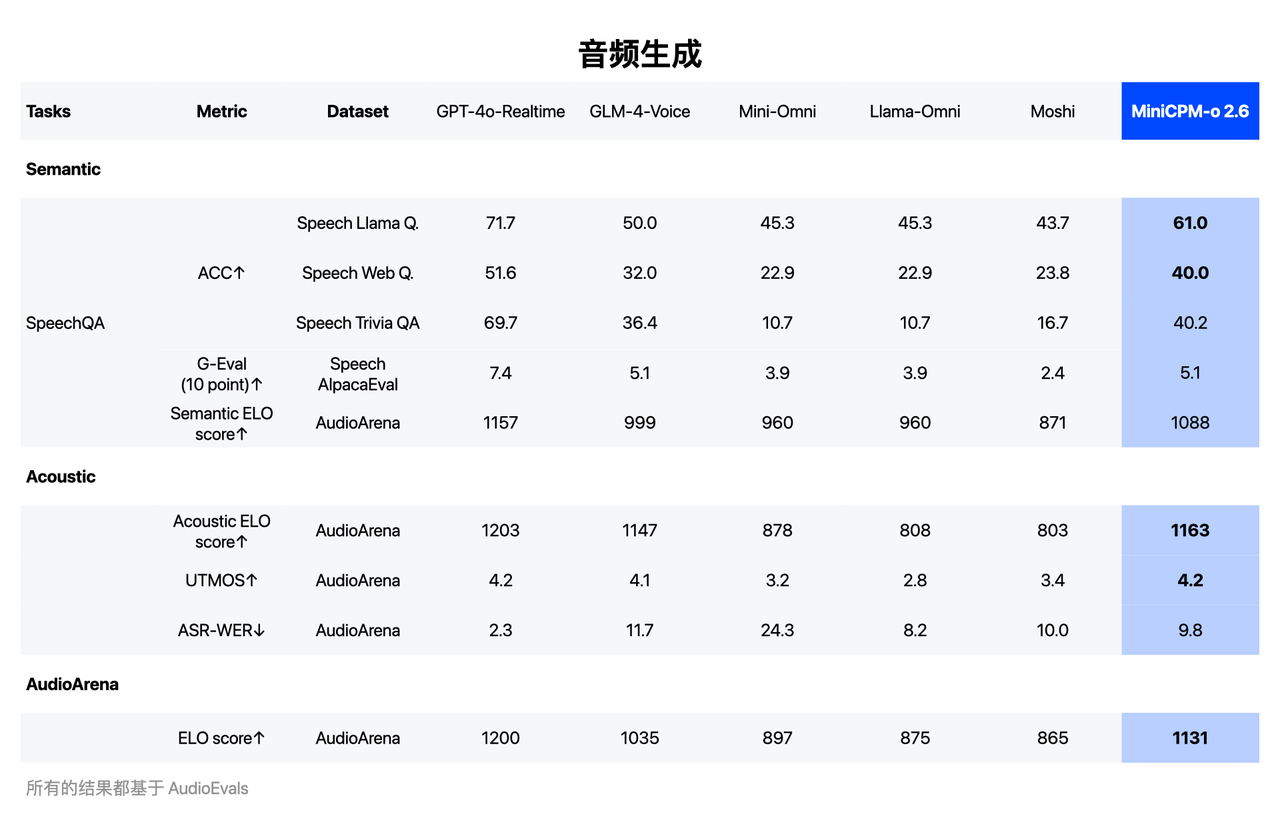
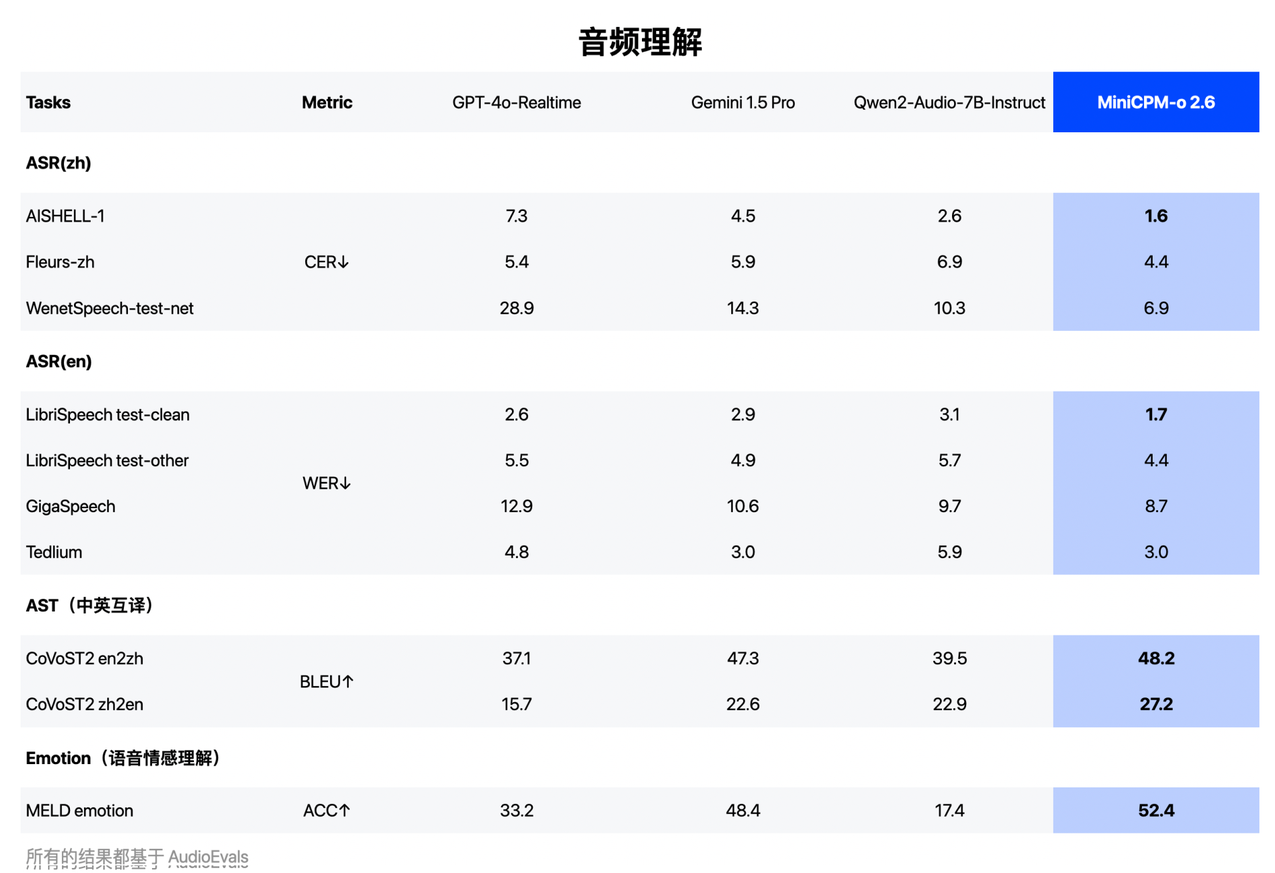
С точки зрения понимания речи он превосходит Qwen2-Audio 7B и реализует общую модель SOTA с открытым исходным кодом (включая ASR, описание речи и другие задачи с точки зрения генерации речи, MiniCPM-o 2.6 превосходит GLM-4-Voice 9B и реализует); общая модель SOTA с открытым исходным кодом.
От «удобного» к «простому в использовании» мы столкнулись со стеной и пошли своим путем.
Запуск MiniCPM-o 2.6 неотделим от технологических прорывов в области сжатия моделей, аппаратной адаптации и архитектуры полномодальной потоковой передачи.
- Сквозная полномодальная архитектура потоковой передачи: на основе модели 4B MiniCPM 3.0 унифицированная обработка изображения и голоса достигается за счет модульной конструкции. Модули соединены сквозным способом, чтобы обеспечить передачу мультимодальной информации без потерь и повысить естественность формируемого контента.
- Технология модального параллелизма с малой задержкой: инновационно использует технологию мультиплексирования с временным разделением для разделения входного сигнала на временные интервалы для параллельной обработки. Интеллектуальная семантика используется для определения времени окончания пользовательского ввода, что эффективно снижает задержки ответа системы.
- Сквозное полномодальное потоковое обучение: основанная на теории речевого поведения модель не просто обрабатывает информацию, но и понимает социальные намерения говорящего. Посредством обучения в мультимодальной среде и ролевых игр достигается более глубокое семантическое понимание, что закладывает основу для будущих воплощенных приложений роботов.
Фактически, когда мы переключаем внимание с этих блестящих технических достижений на реальную рабочую среду конечной модели, нам приходится сталкиваться с объективной реальностью. Развертывание моделей на терминальных устройствах по-прежнему сталкивается с тремя основными проблемами: памятью, энергопотреблением и вычислительной мощностью.
Apple указала в своей статье «LLM in flash», что языковая модель с 7 миллиардами параметров половинной точности потребует более 14 ГБ пространства DRAM для полной загрузки в терминал. Meta указала в своей модели MobileLLM, что полная; энергия аккумулятора около 5000 джоулей. Для iPhone только модель 7B поддерживает менее 2 часов разговора при скорости генерации ИИ 10 токенов в секунду.

Чтобы поместить слона в холодильник, производители чипов для мобильных телефонов ускорили исследования и разработки чипов искусственного интеллекта, сосредоточив внимание на передовых производственных процессах, объеме и пропускной способности памяти, а также производительности процессора и графического процессора. Бренды мобильных телефонов также будут оснащать более производительные батареи и компоненты охлаждения, чтобы улучшить общие возможности аппаратного обеспечения терминала и улучшить поддержку моделей искусственного интеллекта.
Однако усовершенствование аппаратного обеспечения — это лишь часть решения. Реальная проблема заключается в том, как обеспечить больший уровень интеллекта при меньшем количестве параметров. .
Исследования команды Wallface показывают, что при совместном развитии данных, вычислительной мощности и алгоритмов тот же уровень интеллекта может быть достигнут с меньшим количеством параметров. Например, возможности GPT-3, для которых в 2020 году требовалось 175 миллиардов параметров, к февралю 2024 года будут достигнуты всего лишь с 2,4 миллиарда параметров.
Основываясь на этом открытии, команда Wall-Facing еще в прошлом году предложила закон плотности большой модели (Закон Денсинга).
Плотность возможностей модели увеличивается экспоненциально с течением времени, а параметры модели, которые достигают тех же возможностей, уменьшаются вдвое каждые 3,3 месяца (примерно 100 дней). Накладные расходы на вывод модели со временем уменьшаются экспоненциально, а затраты на обучение модели быстро уменьшаются.
Модель эффективно сжимается и, наконец, адаптируется к терминальному оборудованию, и в результате прогресс в отрасли станет естественным.
Наступление следующего поворотного момента в бытовой электронике — это уже не просто обновление оборудования, а изменение способа использования продуктов и пользовательского опыта по сравнению с базовой логикой, что также открывает новые возможности и точки роста для рынка.

Спрос потребителей на продукты искусственного интеллекта на устройствах продолжает расти, и они готовы платить более высокие цены за более умные и удобные продукты. Это побудит компании увеличить инвестиции в исследования и разработки технологий искусственного интеллекта на устройствах, а также в инновации продуктов.
По прогнозам IDC, в 2024 году более половины устройств на рынке терминального оборудования Китая будут иметь вычислительную мощность для выполнения вычислительных задач искусственного интеллекта на аппаратном уровне. К 2027 году эта доля увеличится почти до 80%.
На выставке CES 2025 мы также увидели, что интеграция моделей устройств и аппаратного обеспечения привела к появлению ряда электронных продуктов, включая AIPC, AIPhone, интеллектуальные очки AI, игрушки-компаньоны AI и т. д.
Траектория развития скрытого интеллекта также подтверждает эту тенденцию.
Только во второй половине прошлого года интеллектуальная торцевая модель MiniCPM, обращенная к стене, была запущена ускоренными темпами. Она последовательно установила отношения сотрудничества с Huawei Cloud, Accelerated Evolution Robot, Elephant Robot, Wutong Technology, Great Wall Motors. MediaTek, Baidu Smart Cloud и Intel, а сфера ее деятельности расширилась до интеллектуальной кабины, роботов, совместной работы устройств с облаком и других областей.

Ли Дахай, генеральный директор Wall-Facing Intelligence, заявил в интервью APPSO, что MiniCPM-o 2.6 будет ориентирован на устройства с сильными характеристиками. В настоящее время Wall-Facing Intelligence установила тесные отношения сотрудничества с производителями роботов-гуманоидов, чтобы ускорить их эволюцию.
По его мнению, эта полномодальная конечная модель может улучшить функцию «мозга» робота и обеспечить ключевую техническую поддержку онтологической системы робота. Он также надеется на интеграцию ее с большим количеством производителей роботов, автомобилей, мобильных телефонов и т. д. и т.д. Сотрудничать с производителями оборудования со специализированной атрибутикой.

Оглядываясь назад на историю развития MiniCPM, от выпуска флагманской клиентской модели MiniCPM 1.0 первого поколения до версии MiniCPM 3.0, мы открыли момент ChatGPT на стороне клиента. MiniCPM всегда придерживался принципа «маленький и широкий + высокая эффективность и низкая стоимость».
При этом Wall-Facing Intelligence всегда придерживалась тенденции создания крупномасштабных моделей с открытым исходным кодом в Китае.
С момента выпуска в феврале 2024 года серия торцевых моделей MiniCPM была загружена более 4 миллионов раз, что сделало ее самой популярной китайской моделью в мире в Hugging Face 2024.
Инклюзивность технологии искусственного интеллекта претерпевает три этапа эволюции: сначала она становится доступной для всех, затем становится удобной в использовании и, наконец, становится комфортной в использовании.
Непосредственный интеллект ускоряет трансформацию этой последней мили.
# Добро пожаловать на официальную общедоступную учетную запись WeChat aifaner: aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo