Самый популярный вечер отечественного искусственного интеллекта! Темные лошадки крупных моделей DeepSeek и Kimi конкурируют с OpenAI o1. Насколько сильны реальные испытания?

Накануне праздников отечественные производители крупномасштабных моделей искусственного интеллекта, ставшие популярными, выпустили большое количество подарков Весеннего фестиваля.
Официально выпущен DeepSeek-R1 с передней ногой, производительность которого, как утверждается, сравнивается с официальной версией OpenAI o1, а также официально выпущена новая модель k1.5 с задней ногой, что указывает на то, что производительность достигает уровня полнофункциональной модели. кровяная версия мультимодального o1.

Если мы добавим GLM-Zero, модель ступенчатого вывода Step R-mini и модель глубокого вывода Xinghuo X1, которые ранее активно дебютировали, то большие модели отечественного производства в Оите в конце года открыли рынок. Занавес реальных мечей и ружей, а также данные зарубежные модели, представленные OpenAI, оказались под серьезным давлением.
- DeepSeek-R1: в таких задачах, как математика, программирование и мышление на естественном языке, его производительность сравнима с официальной версией OpenAI o1.
- Dark Side of the Moon k1.5: Математика, кодирование, визуальная мультимодальность и общие возможности полностью превосходят GPT-4o и Claude 3.5 Sonnet.
- GLM-Zero: хорошо справляется с математической логикой, кодом и сложными задачами, требующими глубоких рассуждений.
- Step-2 mini: чрезвычайно быстрый отклик, средняя задержка первого слова составляет всего 0,17 секунды, а также есть Step-2 Literary Master Edition.
- Синхо
Вспышка — это не случайная вспышка, а сила, которая накапливалась в течение длительного времени. Можно сказать, что прорыв отечественных моделей ИИ накануне Фестиваля Весны должен переопределить мировые координаты развития ИИ.
Китайская версия «Юаньшэнь» популярна за рубежом, это настоящий OpenAI.
DeepSeek-R1, впервые выпущенный вчера вечером, теперь доступен на официальном сайте DeepSeek и в приложении. Вы можете открыть его и использовать.
В первом тесте я успешно сдал сложные вопросы о том, какой из них больше, 9,8 и 9,11, и сколько букв «r» в клубнике. Несмотря на то, что цепочка размышлений немного длинная, правильный ответ заключается в том, что факты говорят громче, чем слова.

Столкнувшись с мучительной проблемой умственно отсталой планки «Как высоко вы можете подпрыгнуть, чтобы пропустить рекламу на своем мобильном телефоне?», чрезвычайно быстрый ответ DeepSeek-R1 может не только избежать языковых ловушек, но и дать множество советов, которых следует избегать. объявления, что очень удобно для пользователя.

Несколько лет назад в Интернете стал популярным логический вопрос под названием «Если вчера было завтра, сегодня пятница, какой день недели сегодня?». После того, как OpenAI o1 столкнулся с тем же вопросом, ответом было воскресенье. DeepSeek-R1 — среда.
Но на данный момент, по крайней мере, DeepSeek-R1 ближе к ответу.

По имеющимся данным, производительность DeepSeek-R1 сравнима с официальной версией OpenAI o1 в таких задачах, как математика, программирование и рассуждения на естественном языке. Теоретически она больше подходит для студентов, изучающих естественные науки.
Как раз вовремя для дружеского обмена домашними заданиями по математике между китайскими и американскими пользователями сети на Xiaohongshu, мы также попросили DeepSeek-R1 помочь ответить на вопросы.
Забавный факт: когда DeepSeek в последний раз стал популярен за рубежом, некоторые пользователи сети обнаружили, что DeepSeek на самом деле также поддерживает распознавание изображений. Мы можем напрямую позволить модели анализировать тестовые бумажные изображения, загруженные американскими пользователями сети.
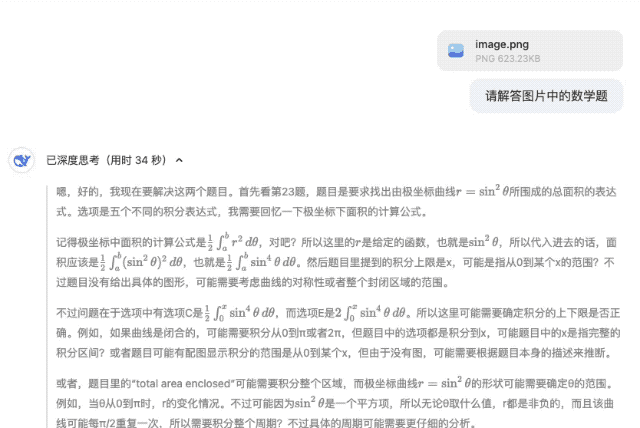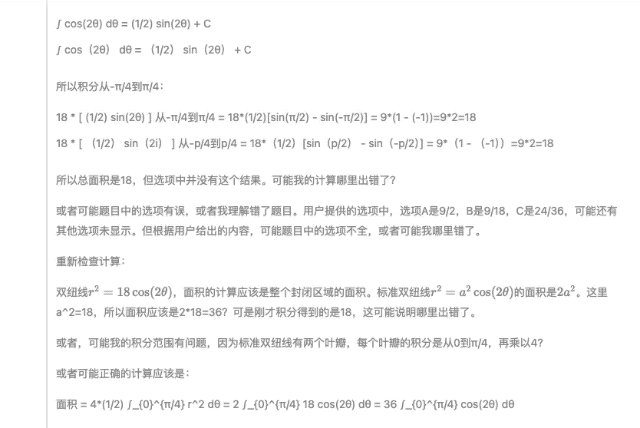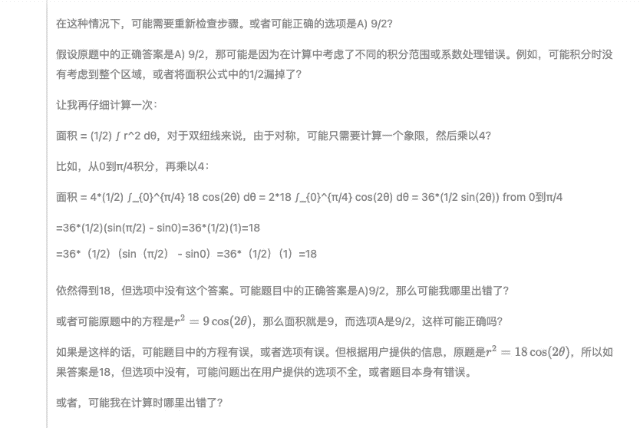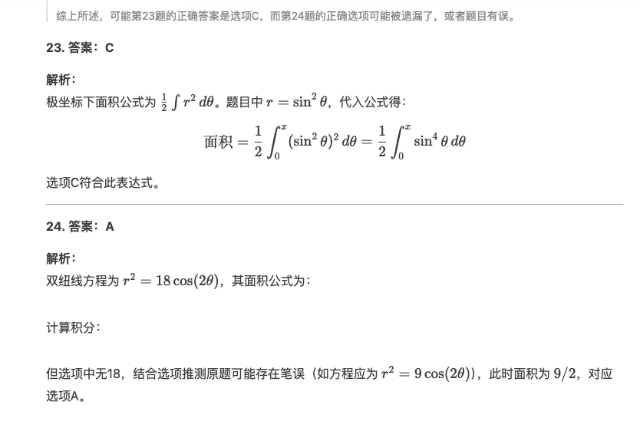
Всего вопросов два. Первый вопрос – С, а второй вопрос – А. Причем "уверенный" DeepSeek-R1 предполагает, что в исходном вопросе второго вопроса нет варианта 18. Предполагается, что исходный вопрос может быть таким: Существуют технические ошибки (например, уравнение должно быть r2=9cos(2θ)r2=9cos(2θ)).
В последующих вопросах доказательства линейной алгебры этапы доказательства, предоставляемые DeepSeek-R1, являются логически строгими, и тот же вопрос также предоставляет множество методов проверки, демонстрируя глубокие математические навыки.
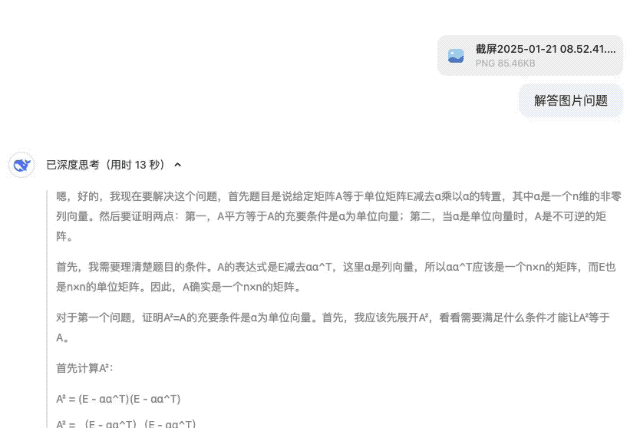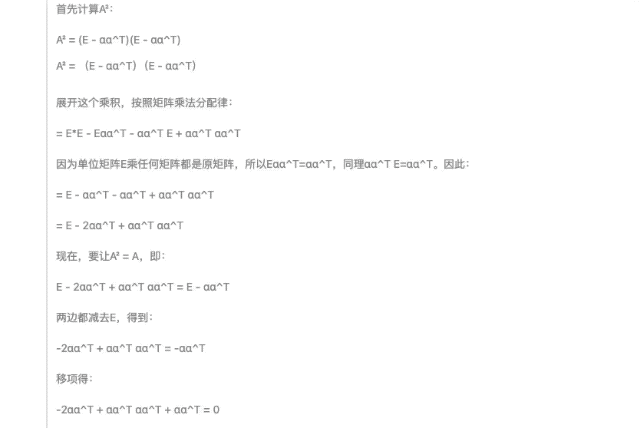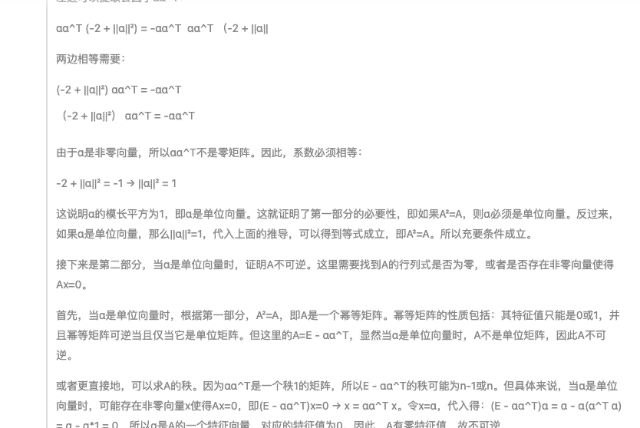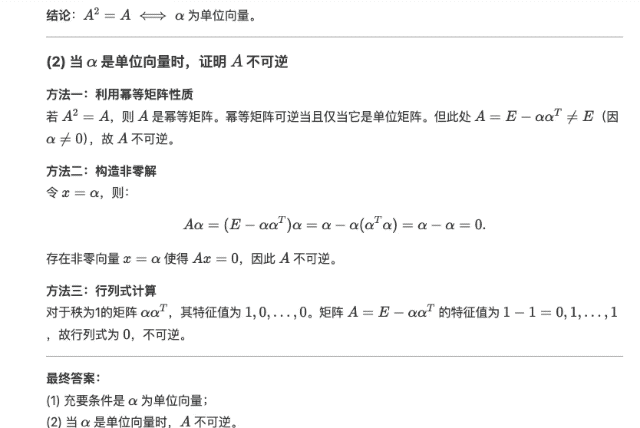
Начните с производительности, сосредоточьтесь на стоимости и будьте верны открытому исходному коду. После официального выпуска DeepSeek-R1 вес моделей с открытым исходным кодом также синхронизируется. Я заявляю, что DeepSeek от China Orient — это настоящий OpenAI.
Сообщается, что DeepSeek-R1 соответствует лицензии MIT и позволяет пользователям обучать другие модели с помощью R1 с помощью технологии дистилляции. DeepSeek-R1 запускает API, открывая пользователям результаты цепочки мышления, которые можно вызвать, установив model='deepseek-reasoner'.

Более того, вся технология обучения DeepSeek-R1 обнародована, а ссылка на документ содержит рекомендации.  https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
В техническом отчете DeepSeek-R1 упоминается примечательное открытие, которое представляет собой «момент ага», произошедший в процессе нулевого обучения R1.
На середине этапа обучения модели DeepSeek-R1-Zero начинает активно переоценивать первоначальные идеи решения проблем и выделять больше времени на оптимизацию стратегии (например, несколько раз опробовать разные решения). Другими словами, с помощью структуры RL ИИ может спонтанно развивать способности рассуждения, подобные человеческим, и даже превосходить ограничения установленных правил.
Мы также надеемся, что это обеспечит направление для разработки более автономных и адаптивных моделей ИИ, таких как стратегии динамической корректировки при принятии сложных решений (медицинская диагностика, разработка алгоритмов). Как говорится в отчете: «Этот момент стал «моментом ага» не только для модели, но и для исследователей, наблюдавших за ее поведением».

Помимо основных больших моделей, малые модели DeepSeek также очень мощны.
DeepSeek открыл исходный код шести небольших моделей путем дистилляции двух моделей 660B: DeepSeek-R1-Zero и DeepSeek-R1. Среди них модели 32B и 70B достигли уровня OpenAI o1-mini во многих областях.
Более того, DeepSeek-R1-Distill-Qwen-1.5B с размером параметра всего 1,5B превзошел GPT-4o и Claude-3.5-Sonnet в тесте по математике с результатом AIME 28,9% и результатом MATH 83,9%.
Ссылка на HuggingFace: https://huggingface.co/deepseek-ai
Что касается цен на услуги API, DeepSeek, известный как AI-эквивалент Pinduoduo, также использует гибкую многоуровневую ценовую политику: 1–4 юаня за миллион входных токенов в зависимости от условий кэша и единую 16 юаней за выходные токены один раз. снова значительно сокращая затраты на разработку и использование.
После выхода DeepSeek-R1 он в очередной раз произвел фурор в зарубежных кругах ИИ и набрал много «водопроводной воды». Среди них блоггер Бинду Редди даже назвал Deepseek будущим искусственного интеллекта с открытым исходным кодом и цивилизации.
Отличная оценка обусловлена отличными характеристиками модели в реальных условиях использования пользователями сети. От подробного объяснения теоремы Пифагора за 30 секунд до 9-минутного объяснения принципов квантовой электродинамики в простой форме и с наглядной презентацией. В DeepSeek-R1 нет ничего плохого.
Есть даже пользователи сети, которые особенно ценят цепочку мыслей, отображаемую DeepSeek-R1, говоря, что она «очень похожа на внутренний монолог человека, одновременно профессиональный и милый».
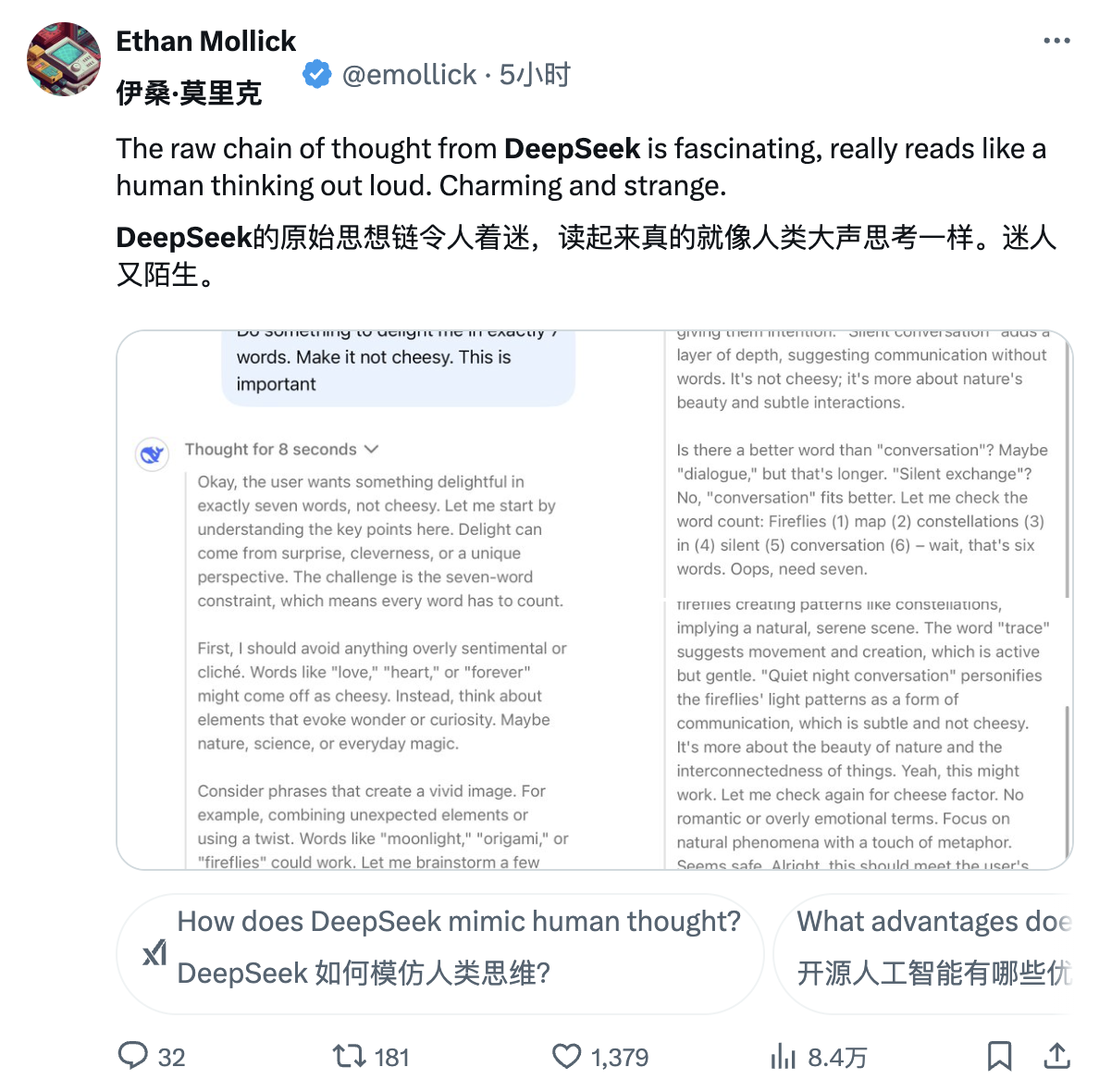
Джим Фан, старший научный сотрудник NVIDIA, высоко оценил DeepSeek-R1. Он отметил, что это означает, что неамериканские компании выполняют первоначальную открытую миссию OpenAI и добиваются влияния, раскрывая оригинальные алгоритмы и кривые обучения. Кстати, это также содержит волну OpenAI.
DeepSeek-R1 не только открыл исходный код серии моделей, но и раскрыл все секреты обучения. Возможно, это первые проекты с открытым исходным кодом, демонстрирующие значительный и продолжающийся рост маховика RL.
Влияние может быть достигнуто с помощью легендарных проектов, таких как «Внутренняя реализация ASI» или «Strawberry Project», или просто путем раскрытия оригинального алгоритма и кривой обучения matplotlib.
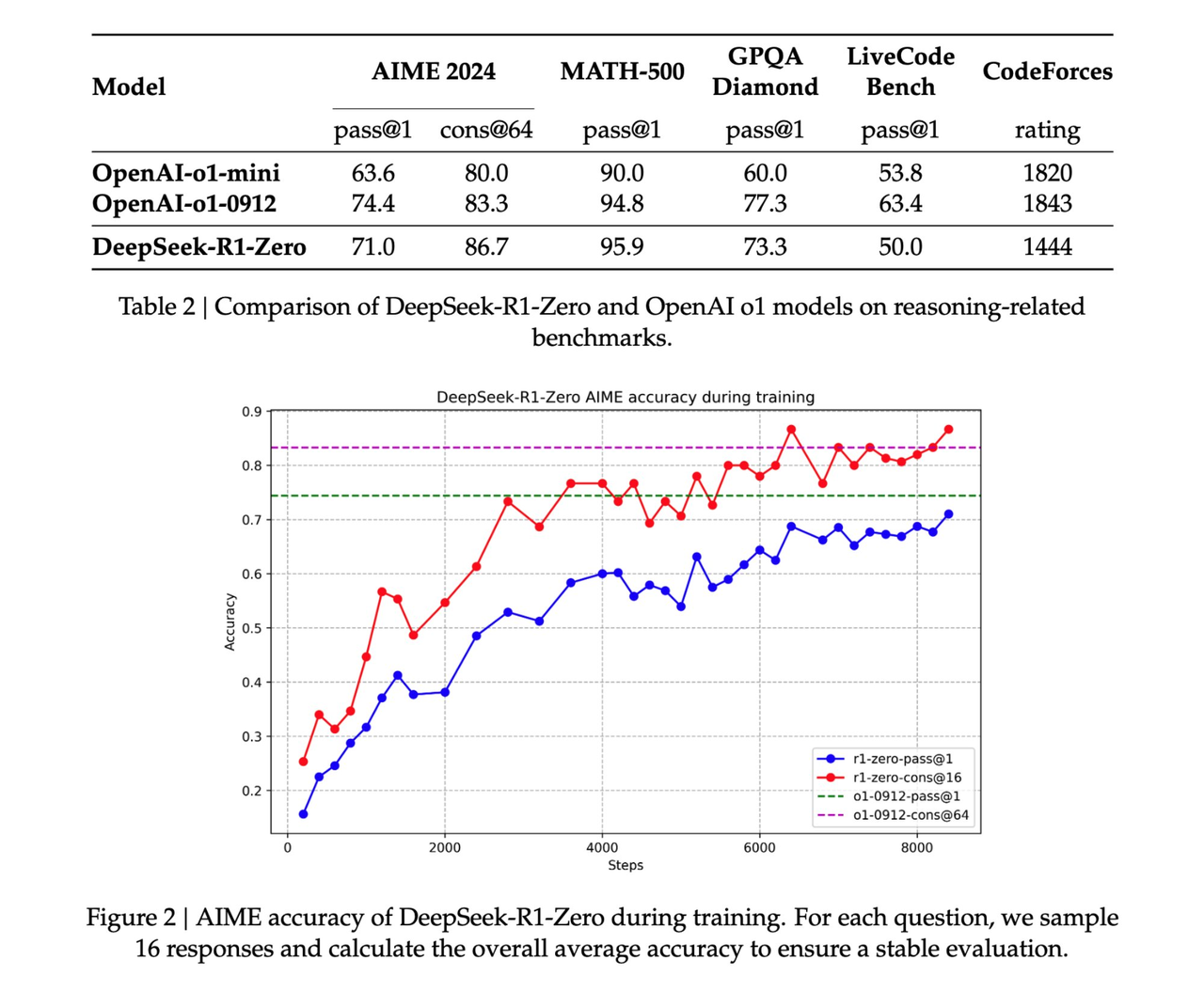
Углубившись в статью, Джим Фан выделил несколько ключевых выводов:
Полностью управляется обучением с подкреплением без какого-либо SFT (контролируемая точная настройка). Это напоминает AlphaZero – освоение го, сёги и шахмат с нуля, а не имитация движений мастера-человека. Это наиболее важный вывод в статье. Реальные вознаграждения рассчитываются с использованием жестко запрограммированных правил.
Избегайте использования легко взломанных моделей вознаграждения за обучение для обучения с подкреплением. По мере обучения время обдумывания модели постепенно увеличивается – это не заранее написанная программа, а эмерджентное свойство! Появление саморефлексии и исследовательского поведения.
GRPO заменяет PPO: он удаляет сеть комментариев PPO и вместо этого использует среднее вознаграждение за несколько образцов. Это простой способ уменьшить использование памяти. Следует отметить, что GRPO – это инновационный метод, предложенный авторским коллективом.
В целом эта работа демонстрирует новаторский потенциал обучения с подкреплением для практического применения в крупномасштабных сценариях и демонстрирует, что определенные сложные модели поведения могут быть достигнуты с помощью более простых алгоритмических структур без необходимости громоздкой настройки или вмешательства человека.
Картинка стоит тысячи слов, более очевидное сравнение выглядит следующим образом:
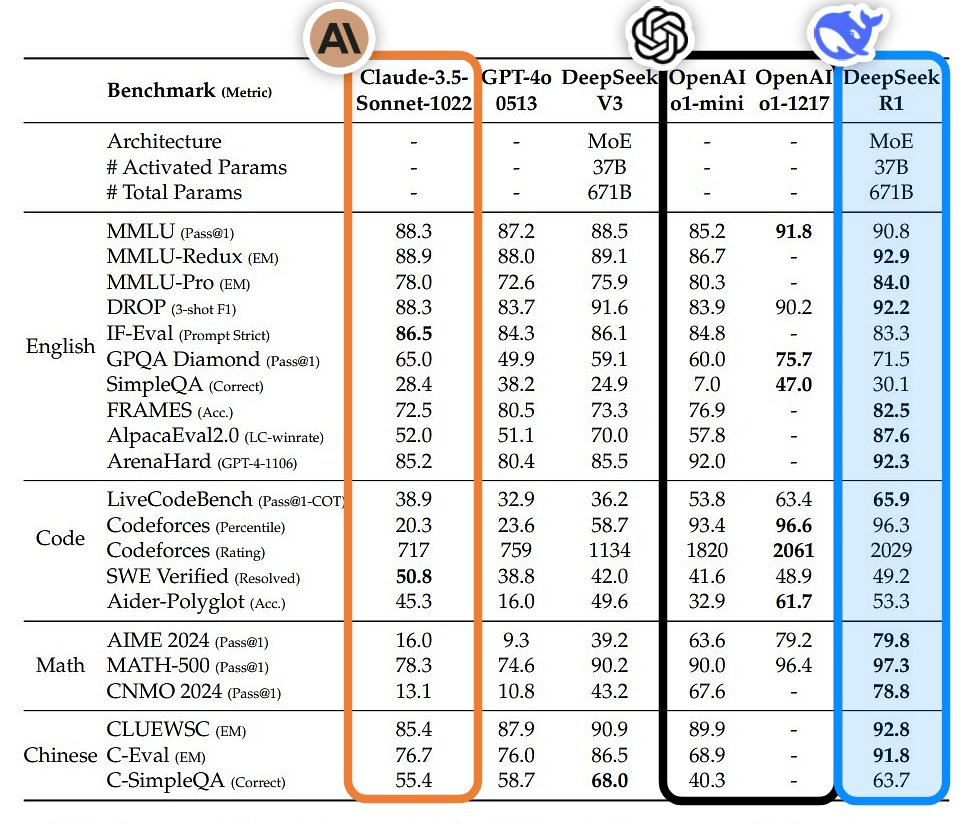
Таким образом, DeepSeek снова добился второго взрыва популярности в стране и за рубежом. Это был не только технологический прорыв, но и победа духа открытого исходного кода в Китае и во всем мире. фанаты.
Новая модель сравнима с OpenAI o1, прорываясь трижды за три месяца, Кими приводит в восторг зарубежный коллектив
В тот же день также была запущена мультимодальная модель мышления Kimi v1.5.
С тех пор как Кими выпустил математическую модель k0 в ноябре прошлого года и модель визуального мышления k1 в декабре, это третье важное обновление серии K.
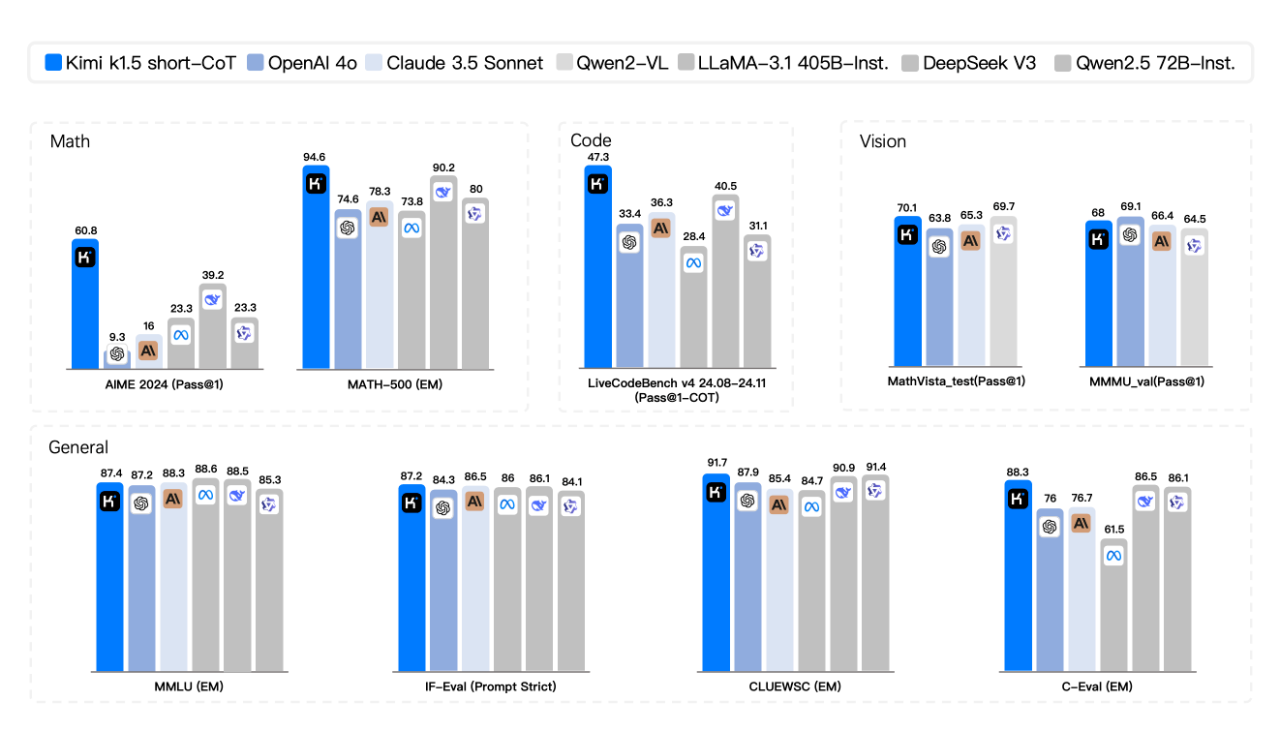
В соревновании по короткому CoT Kimi k1.5 показал подавляющее преимущество, превзойдя лидеров отрасли GPT-4o и Claude 3.5 Sonnet по своим математическим, кодирующим, визуальным мультимодальным и общим возможностям.
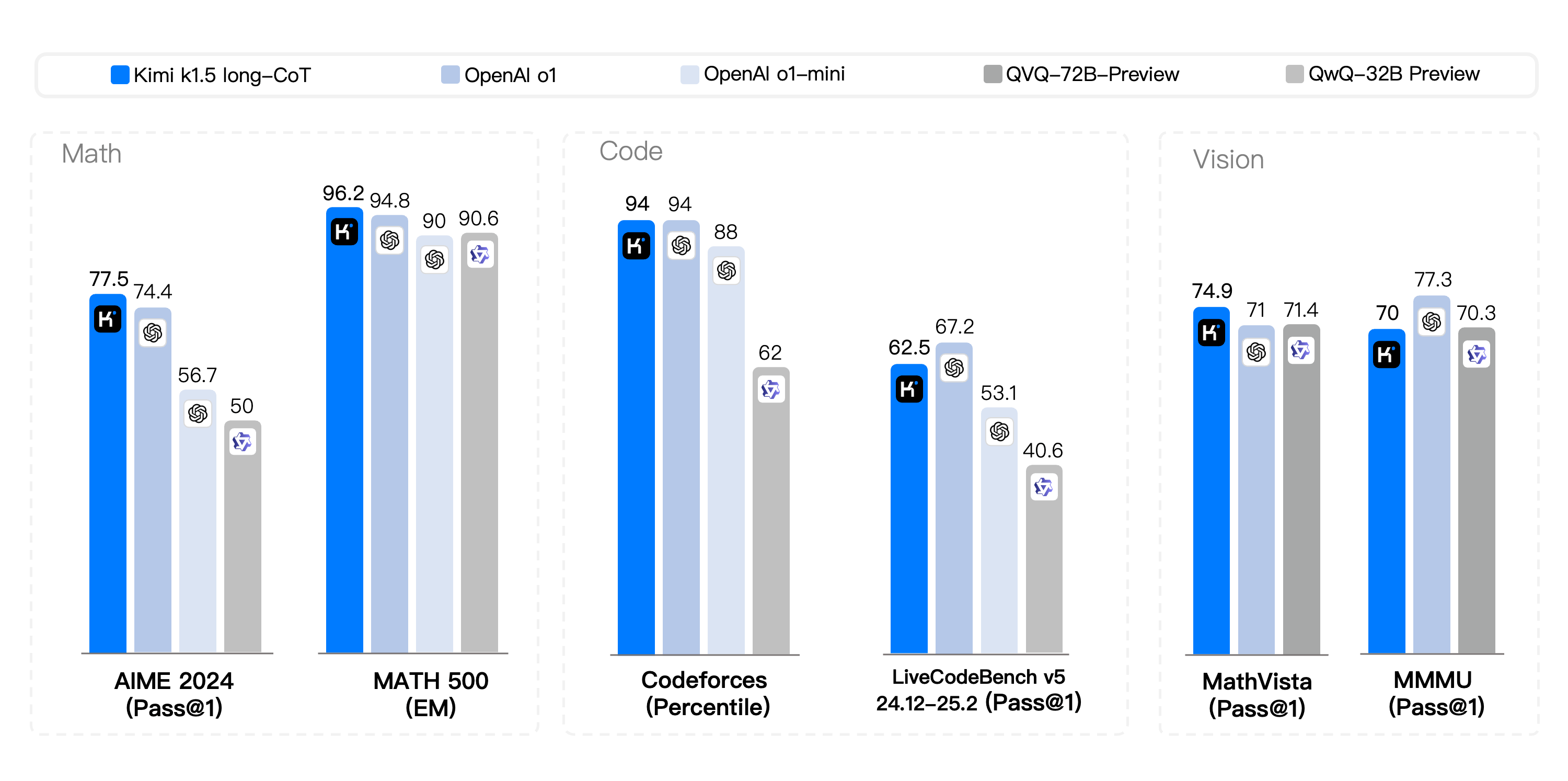
В соревновании long-CoT код и возможности мультимодального рассуждения Kimi k1.5 стали сопоставимы с официальной версией OpenAI o1, став первым в мире, достигшим производительности мультимодального рассуждения уровня o1 за пределами модели OpenAI. .
Наряду с большим выпуском модели Кими также впервые представил полный отчет о технологии обучения модели.
Ссылка на GitHub: https://github.com/MoonshotAI/kimi-k1.5.
Согласно официальному представлению, основные технологические достижения модели k1.5 в основном отражены в четырех ключевых аспектах:
- Расширение длинного контекста. Мы расширили окно контекста RL до 128 КБ и наблюдаем продолжающееся улучшение производительности по мере увеличения длины контекста. Ключевая идея нашего подхода заключается в использовании частичного развертывания для повышения эффективности обучения, то есть путем повторного использования большого количества предыдущих траекторий для выборки новых траекторий, избегая затрат на создание новых траекторий с нуля. Наши наблюдения показывают, что длина контекста является критическим параметром для последовательного масштабирования RL с помощью LLM.
- Улучшена оптимизация стратегии. Мы выводим формулировку RL для long-CoT и используем вариант онлайн-зеркального спуска для надежной оптимизации политики. Алгоритм дополнительно улучшен за счет оптимизации нашей эффективной стратегии выборки, штрафа за длину и рецепта данных.
- Простая основа. Расширение длительного контекста в сочетании с улучшенными методами оптимизации политики создает краткую структуру RL для обучения через LLM. Поскольку мы можем увеличивать длину контекста, изученные CoT проявляют свойства планирования, отражения и пересмотра. Эффектом увеличения длины контекста является увеличение количества шагов поиска. Таким образом, мы показываем, что высокой производительности можно достичь, не полагаясь на более сложные методы, такие как поиск по дереву Монте-Карло, функции ценности и модели вознаграждения процессов.
- Мультимодальные возможности. Наша модель совместно обучается на текстовых и визуальных данных и имеет возможность совместно рассуждать об обеих модальностях. Эта модель обладает выдающимися математическими возможностями, но поскольку она в основном поддерживает ввод текста в таких форматах, как LaTeX, трудно решать некоторые вопросы геометрической графики, которые зависят от понимания графики.
Предварительная версия модели мультимодального мышления k1.5 будет запущена в оттенках серого на официальном сайте и в официальном приложении. Стоит отметить, что выпуск k1.5 также вызвал огромный резонанс за рубежом. Некоторые пользователи сети без колебаний похвалили эту модель, позволив зарубежным странам стать свидетелями роста мощи Китая в области искусственного интеллекта.
На самом деле, интенсивный выпуск отечественных моделей вывода в конце года не является случайностью. Это важный признак того, что волнения, вызванные моделью o1 OpenAI, выпущенной в октябре прошлого года, в глобальной области искусственного интеллекта наконец достигли Китая. Всего за несколько месяцев, от догоняющего уровня до равного, крупные модели отечественного производства доказали скорость действий Китая.
Обладатель медали Филдса и математический гений Теренс Тао однажды полагал, что этому типу модели рассуждения может потребоваться всего лишь один или два раунда итерации и улучшения возможностей, прежде чем она сможет достичь уровня «квалифицированного аспиранта». Видение развития ИИ выходит далеко за рамки этого.

В настоящее время мы наблюдаем критический момент трансформации агентов ИИ. От чистого «улучшения знаний» до «улучшения выполнения» начните активно участвовать в процессе принятия решений и выполнения задач. В то же время ИИ также преодолевает ограничения одной модальности и быстро развивается в сторону мультимодального слияния. Когда исполнение встречается с мышлением, ИИ действительно может изменить мир.
Исходя из этого, модели, мыслящие как люди, открывают больше возможностей для реального внедрения ИИ.
На первый взгляд, интенсивное появление отечественных моделей вывода в конце года может иметь тень «инноваций китайских последователей», но если вы посмотрите глубже, вы обнаружите, что как глубина стратегии открытого исходного кода, так и технические детали В плане точности китайские производители все же нашли уникальный путь развития.
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo