OpenAI заявляет, что у нее есть доказательства нарушений DeepSeek, а генеральный директор Anthropic публикует сообщение длиной в 10 000 слов, призывающее к ужесточению контроля в США.

В последнее время у DeepSeek возникли проблемы.
По сообщению зарубежного СМИ Financial Times, в OpenAI заявили, что есть доказательства того, что DeepSeek использовала модель OpenAI для разработки собственных продуктов искусственного интеллекта с открытым исходным кодом, что могло нарушать условия обслуживания OpenAI.
В индустрии искусственного интеллекта принято разрабатывать новые модели с помощью технологии «дистилляции». Однако OpenAI считает, что поведение DeepSeek превысило допустимый диапазон, поскольку они используют технологию OpenAI для создания конкурирующего продукта.
На момент публикации OpenAI отказалась вдаваться в подробности этих обвинений.
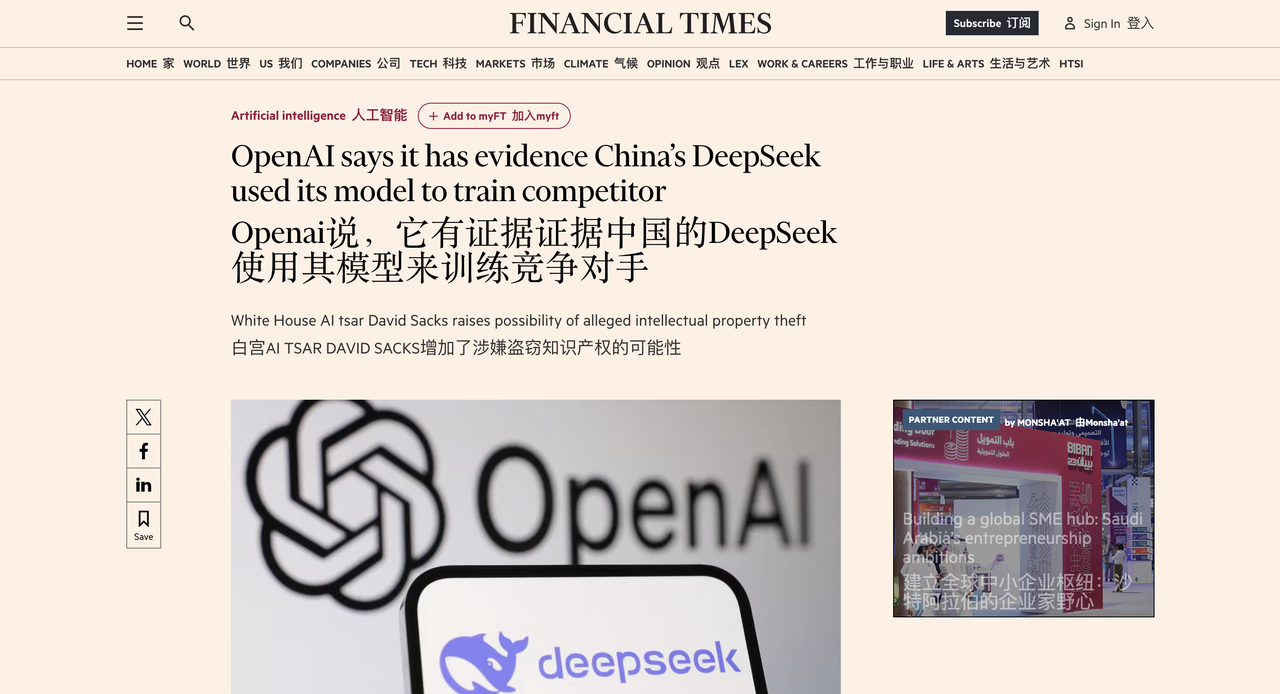
Вчера агентство Bloomberg сообщило, что OpenAI и ее партнер Microsoft начали расследование в отношении нескольких учетных записей, которые использовали API OpenAI в прошлом году, и закрыли доступ к учетным записям, подозреваемым в дистилляции моделей, на том основании, что такое поведение нарушает условия обслуживания.
Одна волна не утихла, а поднялась другая волна.
По данным зарубежного СМИ Techcrunch, компания DeepSeek подала заявку на товарный знак в Ведомство по патентам и товарным знакам США (USPTO), надеясь зарегистрировать бренд своих чат-ботов, продуктов и инструментов с искусственным интеллектом. Однако его заявка поступила поздно.
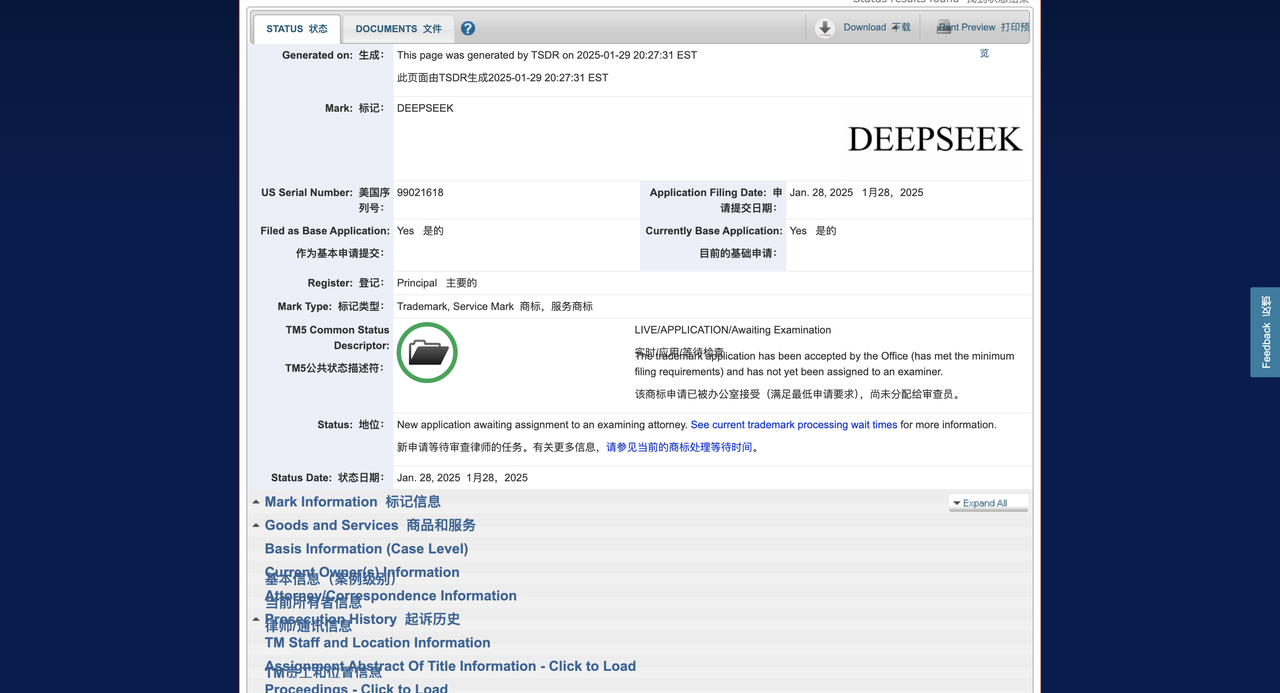
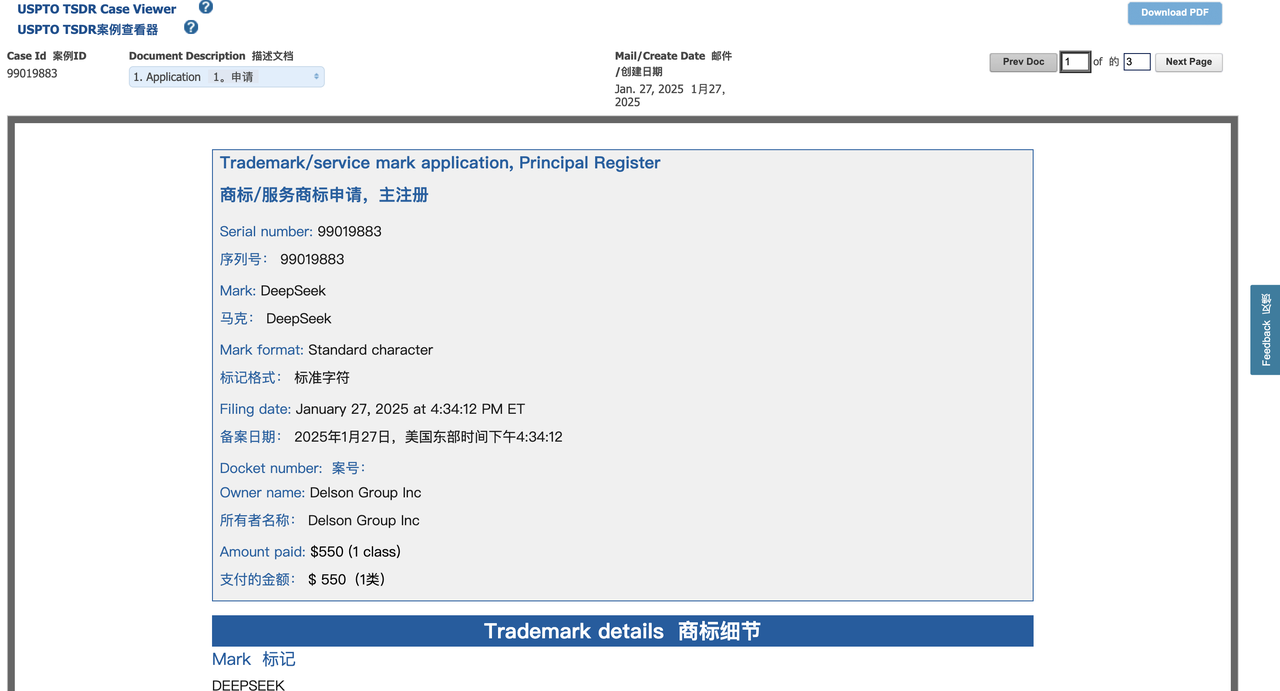
Всего 36 часов назад компания Delson Group Inc. из Делавэра стала инициатором подачи заявки на товарный знак DeepSeek.
Delson Group утверждает, что продает продукты искусственного интеллекта под брендом DeepSeek с 2020 года. Зарегистрированным адресом компании в заявке на регистрацию товарного знака является дом в Купертино, а ее основателем и генеральным директором является Вилли Лу.
Интересно, что Лу и основатель DeepSeek Лян Вэньфэн оба являются выпускниками Чжэцзянского университета. Согласно профилю Лу в LinkedIn, он утверждает, что является профессором-консультантом на пенсии в Стэнфордском университете, а также работает консультантом Федеральной комиссии по связи США (FCC). Его карьера сосредоточена на области беспроводной связи.
Расследование TechCrunch показало, что Лу также проводил образовательный курс под названием «Суперинтеллект искусственного интеллекта» в Лас-Вегасе под брендом DeepSeek, стоимость билетов начиналась от 800 долларов. Веб-сайт курса также указан в заявке на товарный знак Delson Group и утверждает, что Лу имеет около 30 лет опыта работы в области информационно-коммуникационных технологий (ИКТ) и искусственного интеллекта (ИИ).
Когда TechCrunch связался с Лу по электронной почте, указанной в заявке на товарный знак, он предложил встретиться в Пало-Альто или Саратоге, Калифорния (репортер находился в Нью-Йорке), чтобы обсудить этот вопрос. Но Лу не ответил на дальнейшие просьбы о комментариях.
Поиск в базе данных Совета по рассмотрению споров и апелляций по товарным знакам ВПТЗ США (TTAB) показывает, что Delson Group ранее имела более 20 споров по товарным знакам со многими известными компаниями, включая GSMA, Tencent и TracFone Wireless. Компания добровольно отказалась от некоторых заявок на товарные знаки или отменила их, но также успешно зарегистрировала некоторые товарные знаки.
Поиск в более широкой базе данных товарных знаков USPTO показывает, что Delson Group зарегистрировала 28 товарных знаков, включая товарные знаки известных китайских компаний. Например, компания зарегистрировала товарные знаки Geely и China Mobile, брендов, принадлежащих китайскому автопроизводителю и гонконгскому телекоммуникационному гиганту соответственно.
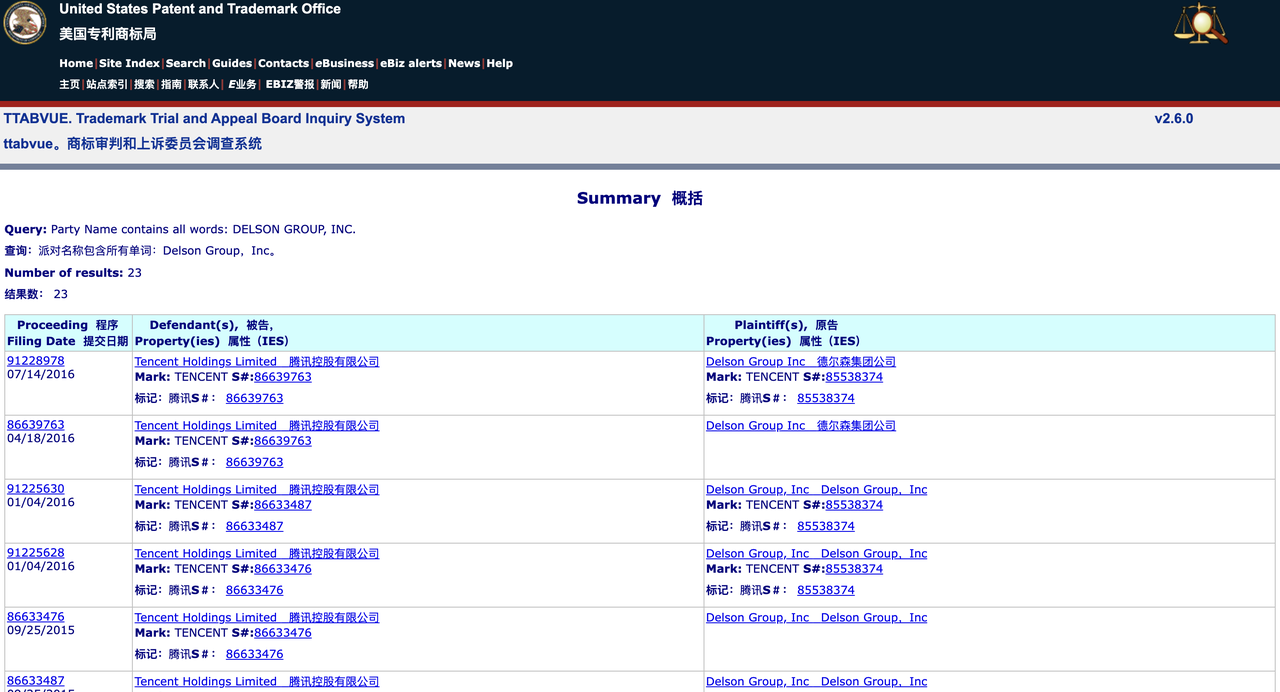
Эта закономерность предполагает, что Delson Group может заниматься «сквоттингом товарных знаков», то есть заранее регистрировать товарные знаки, чтобы продать их позже или получить прибыль от узнаваемости бренда.
В настоящее время права на товарные знаки DeepSeek в США находятся в невыгодном положении. Согласно законодательству США, первая компания, использующая товарный знак, обычно считается законным владельцем товарного знака, если только не будет доказано, что другая сторона зарегистрировала его недобросовестно.
Джош Гербен, юрист по интеллектуальной собственности и основатель Gerben IP Firm, заявил в интервью TechCrunch, что Delson Group имеет преимущества во многих аспектах:
- Время подачи заявки раньше (подано на 36 часов раньше, чем DeepSeek);
- Утверждает, что использует бренд с 2020 года (в заявке на товарный знак DeepSeek указано, что компания была основана в 2023 году);
- Иметь поддающуюся проверке деятельность, связанную с ИИ (включая учебные курсы и веб-сайт).
Гербен отметил, что Delson Group может даже подать иск о «обратной путанице (Reverse Confusion)», утверждая, что быстрый рост DeepSeek заставит общественность ошибочно полагать, что DeepSeek является истинным владельцем товарного знака. Кроме того, Delson Group также может подать в суд на DeepSeek и потребовать от нее прекратить использование бренда DeepSeek на рынке США.

«DeepSeek действительно может столкнуться с серьезными проблемами в отношении товарных знаков», — сказал Гербен, — «Delson Group, как потенциальный «предварительный правообладатель», может иметь веские основания для судебного разбирательства о нарушении прав на товарный знак. "
Стоит отметить, что DeepSeek — не единственная компания, занимающаяся искусственным интеллектом, которая столкнулась с проблемами, связанными с товарными знаками. Например, OpenAI пыталась зарегистрировать товарный знак «GPT», но в феврале прошлого года ВПТЗ США отклонило его на том основании, что этот термин был слишком общим.
Как мы уже сообщали ранее, OpenAI все еще находится в судебном споре с технологическим предпринимателем Гаем Рэвином по поводу товарного знака «Open AI». Рэвин утверждал, что он предложил эту концепцию товарного знака еще в 2015 году (год основания OpenAI) и надеялся создать платформу искусственного интеллекта с «открытым исходным кодом».
Кроме того, сегодня рано утром генеральный директор Anthropic Дарио Амодей опубликовал статью объемом 10 000 слов о платформе X, отвечая на многочисленные недавние беспорядки вокруг DeepSeek.
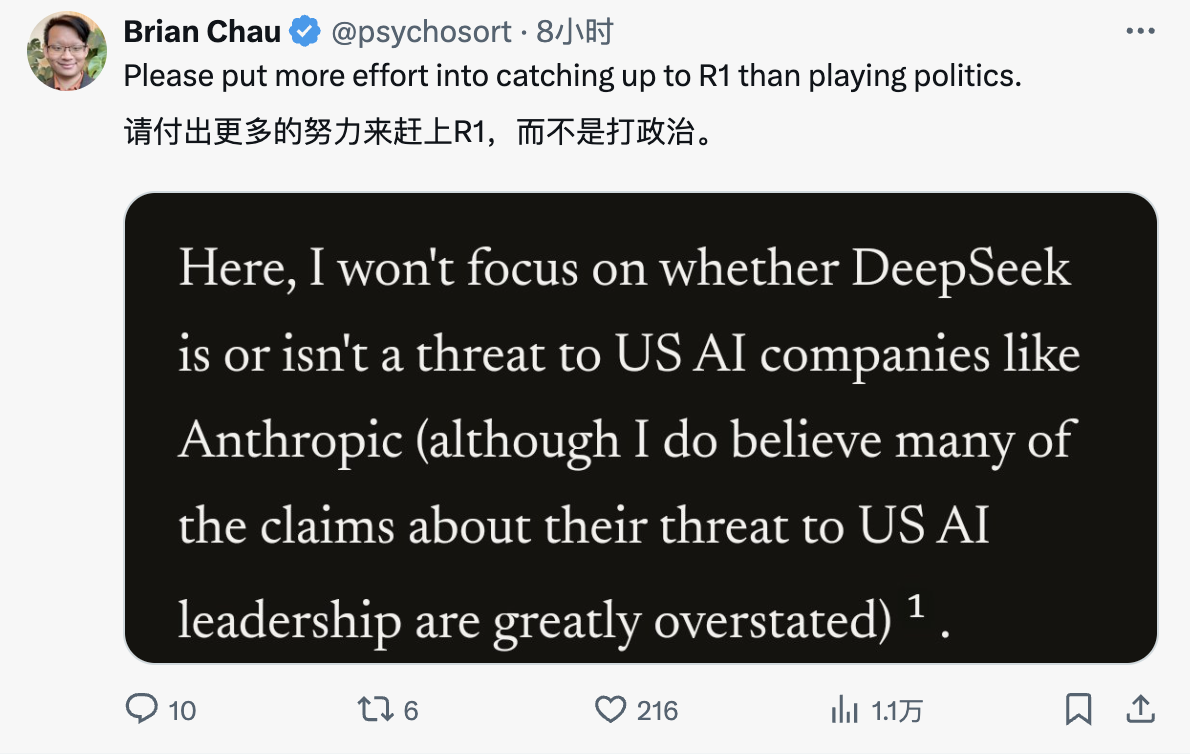
Столкнувшись с предполагаемым нарушением защиты Амодеем, пользователь сети X написал в комментариях:
Прилагается подборка оригинального текста (с удалениями) ~
Несколько недель назад я предложил усилить контроль за экспортом чипов из США в Китай. Сегодня китайская компания DeepSeek, занимающаяся искусственным интеллектом, фактически приближается к самым передовым моделям искусственного интеллекта в Соединенных Штатах с меньшими затратами в некоторых аспектах.
В этой статье я не буду обсуждать, действительно ли DeepSeek угрожает американским ИИ-компаниям, таким как Anthropic (хотя я считаю, что некоторые утверждения о том, что китайский ИИ захватит лидерство в Америке, преувеличены)¹. Вместо этого я хочу изучить вопрос: подрывает ли технологический прорыв DeepSeek необходимость контроля за экспортом чипов? Мой ответ — нет. На самом деле, я думаю, это усиливает важность экспортного контроля².
Основная цель экспортного контроля — обеспечить, чтобы демократические страны оставались на шаг впереди в развитии ИИ. Необходимо прояснить, что политика регулирования не направлена на то, чтобы избежать китайско-американской конкуренции в области искусственного интеллекта. В конечном счете, если Соединенные Штаты и другие демократические страны надеются доминировать в сфере ИИ, им придется иметь более продвинутые модели, чем Китаю. Но в то же время мы не должны позволять китайскому правительству получить технологическое преимущество, когда этого можно избежать.
Три основные динамики развития ИИ
Прежде чем обсуждать политические вопросы, я хотел бы представить три ключевых события в системах искусственного интеллекта, которые имеют решающее значение для понимания отрасли искусственного интеллекта:
1. Законы масштабирования
Основное правило в области ИИ заключается в том, что по мере увеличения масштаба обучения производительность модели будет продолжать неуклонно улучшаться. Мои соучредители и я были первыми, кто задокументировал и подтвердил этот феномен во время работы в OpenAI.
Проще говоря, при прочих равных условиях увеличение объема обучающих вычислений (вычислений) заставит ИИ лучше выполнять различные когнитивные задачи. Например:
- Искусственный интеллект стоимостью 1 миллион долларов потенциально может решить 20% важнейших задач программирования
- Искусственный интеллект стоимостью 10 миллионов долларов может решить 40% проблем
- Искусственный интеллект стоимостью 100 миллионов долларов может решить 60%
Эти различия окажут огромное влияние на практические приложения — 10-кратное увеличение расчетов может означать, что уровень ИИ повышается от студентов до докторантов. В результате компании вкладывают огромные суммы денег в обучение более сильных моделей.
2. Повышение эффективности вычислений (сдвиг кривой)
В области ИИ постоянно появляются различные большие и маленькие инновации, делающие обучение ИИ и получение выводов более эффективными. Эти инновации могут включать улучшения архитектуры модели (например, оптимизацию структуры трансформатора), более эффективные методы вычислений (улучшение использования оборудования) и новое поколение вычислительных микросхем искусственного интеллекта.
Эти оптимизации повысят общую эффективность обучения ИИ, что называется «Сдвиг кривой»:
Если определенная технология обеспечивает двукратное улучшение вычислений (Compute Multiplier, CM), то 40%-ная способность решения кода, обучение которой первоначально стоило 10 миллионов долларов США, теперь стоит всего 5 миллионов долларов США; 60%-ная способность решения кода, которая первоначально стоила 100 миллионов долларов США, теперь стоит всего 50 миллионов долларов США.
Крупные компании, занимающиеся искусственным интеллектом, продолжают обнаруживать такие улучшения CM:
- Небольшая оптимизация (около 1,2 раза): обычная оптимизация тонкой настройки
- Умеренная оптимизация (около 2 раз): улучшения архитектуры или оптимизация алгоритмов.
- Существенная оптимизация (около 10 раз): крупный технологический прорыв
Поскольку повышение уровня интеллекта ИИ имеет чрезвычайно высокую ценность, такое повышение эффективности обычно не снижает общую стоимость обучения, а вместо этого побуждает компании вкладывать больше денег в обучение более сильных моделей. Многие люди ошибочно полагают, что ИИ будет «сначала дорогим, а затем дешевле», как традиционные продукты, но ИИ не является товаром фиксированного качества: когда эффективность вычислений повысится, отрасль не будет сокращать потребление вычислений, а будет быстрее стремиться к созданию более мощного ИИ.
В 2020 году моя команда опубликовала статью, в которой говорится, что скорость повышения вычислительной эффективности, вызванная развитием алгоритмов, составляет примерно 1,68 раза в год. Но нынешние темпы, возможно, ускорились до 4 раз в год, и эта оценка не учитывает влияние усовершенствований аппаратного обеспечения.
3. Снижение затрат на вывод
Повышение эффективности обучения также повлияет на выводы ИИ (т. е. на вычислительные затраты модели во время выполнения). За последние несколько лет мы стали свидетелями того, как стоимость вывода в ИИ продолжает падать, а производительность продолжает улучшаться. Например, Claude 3.5 Sonnet (выпущенный через 15 месяцев после GPT-4) превосходит GPT-4 почти во всех тестах производительности, но его цена API составляет всего 1/10 от GPT-4.

3. Смена парадигмы
Метод расширения обучения ИИ не является статичным. Иногда в процессе обучения меняются основные объекты расширения или вводятся новые методы расширения.
В период с 2020 по 2023 год основным направлением расширения обучения ИИ являются модели предварительного обучения. Эти модели в основном обучаются на основе крупномасштабных текстовых данных Интернета, и на этой основе проводится небольшое дополнительное обучение для улучшения конкретных возможностей.
В 2024 году использование моделей обучения с подкреплением (RL) для создания цепочки мыслей (CoT) станет новым направлением обучения ИИ.
Такие компании, как Anthropic, DeepSeek и OpenAI (предварительная модель o1, выпущенная в сентябре 2024 года), обнаружили, что этот метод обучения может значительно улучшить производительность модели при выполнении определенных объективно измеримых задач, особенно в математических рассуждениях, соревнованиях по программированию и сложных логических рассуждениях, подобных математике и программированию.
В новой парадигме обучения применяется двухэтапный подход: сначала проводится обучение традиционной модели предварительного обучения, чтобы оснастить ее базовыми возможностями. Во-вторых, способность модели к рассуждению повышается за счет обучения с подкреплением (RL).
Поскольку этот метод обучения RL все еще является новым, все компании в настоящее время вкладывают меньше средств в этап RL и, следовательно, все еще находятся на ранних стадиях масштабирования. Увеличение инвестиций в обучение со 100 000 до 1 миллиона долларов может привести к огромному повышению производительности.
Предприятия быстро продвигают расширение обучения RL, которое, как ожидается, вскоре достигнет сотен миллионов или даже миллиардов долларов. В настоящее время мы находимся на уникальной «точке перехода», когда обучение ИИ претерпевает важный сдвиг парадигмы, когда можно достичь быстрого прорыва в производительности за короткий период времени, поскольку обучение RL все еще находится на ранних стадиях развития.
Модель DeepSeek
Вышеупомянутые три основные тенденции развития ИИ могут помочь нам понять модели, недавно выпущенные DeepSeek.
Около месяца назад DeepSeek запустила «DeepSeek-V3», которая представляет собой чисто модель предварительного обучения, модель первого этапа, упомянутую в пункте 3 выше. Затем, на прошлой неделе, они выпустили «R1», в котором добавлен второй этап обучения на базе V3. Хотя внутренние детали этих моделей не полностью доступны внешнему миру, вот мое лучшее представление об обоих запусках.
DeepSeek-V3 — это настоящая недавняя инновация DeepSeek, и она заслуживала внимания еще месяц назад (и мы тогда это заметили).
Будучи чисто предварительно обученной моделью, DeepSeek-V3 по производительности при выполнении некоторых ключевых задач близок к самым передовым моделям искусственного интеллекта в США, но стоимость обучения намного ниже. (Однако мы обнаружили, что Сонет Клода 3.5 по-прежнему значительно лучше справляется с некоторыми ключевыми задачами, особенно с реальным программированием.)
Команда DeepSeek может достичь этого, главным образом, опираясь на ряд действительно выдающихся инженерных инноваций, особенно с точки зрения оптимизации эффективности вычислений, включая инновационную оптимизацию управления «кешем ключей и значений», которая повышает эффективность модели в процессе вывода, и революционное применение технологии «Mixture of Experts (MoE)», которая позволяет ей работать лучше, чем когда-либо, в крупномасштабных моделях искусственного интеллекта.
Однако нам необходимо проанализировать более тщательно:
DeepSeek не «добился с помощью 6 миллионов долларов⁵ того, на что американские компании, занимающиеся искусственным интеллектом, потратили миллиарды долларов». Насколько я могу говорить об Anthropic, Claude 3.5 Sonnet — это модель среднего размера, обучение которой обходится в десятки миллионов долларов (точную сумму не назову). Кроме того, слухи о том, что во время обучения 3.5 Sonnet использовались более крупные и дорогие модели, не соответствуют действительности. Обучение Sonnet проводилось 9–12 месяцев назад, а модель DeepSeek проходила обучение в период с ноября по декабрь прошлого года.
Несмотря на это, Sonnet остается явным лидером во многих внутренних и внешних обзорах. Поэтому более точным утверждением должно быть следующее: «DeepSeek обучил модель по относительно низкой цене, которая близка к производительности американской модели 7–10 месяцев назад, но стоимость не так низка, как говорят люди».
Если в соответствии с прошлыми тенденциями затраты на обучение ИИ снижались примерно в 4 раза в год, то при нормальных обстоятельствах — таких как тенденция снижения затрат в 2023 и 2024 годах — мы можем ожидать, что текущая стоимость обучения модели должна быть в 3–4 раза ниже, чем 3,5 Sonnet или GPT-4o. Производительность DeepSeek-V3 по-прежнему уступает этим передовым американским моделям — примерно в 2 раза хуже (для DeepSeek-V3 эта оценка весьма щедра). Это означает, что если стоимость обучения DeepSeek-V3 в 8 раз ниже, чем у топовой американской модели годичной давности, это нормально и соответствует тенденции, а не является неожиданным прорывом.
Фактически, снижение стоимости DeepSeek-V3 даже меньше, чем снижение цены вывода (в 10 раз) от GPT-4 до Claude 3.5 Sonnet, который сам по себе даже сильнее, чем GPT-4. Все это показывает, что DeepSeek-V3 не является ни революционным прорывом в технологии, ни изменением экономической модели больших языковых моделей (LLM). Это всего лишь обычный случай, соответствующий существующей тенденции снижения затрат.
Разница в том, что на этот раз именно китайская компания взяла на себя инициативу по реализации ожидаемого снижения затрат. Это происходит впервые в истории и поэтому имеет большое геополитическое значение. Однако американские ИИ-компании вскоре последуют этому тренду, и сделают они это не путем копирования DeepSeek, а потому, что сами тоже движутся по сложившейся кривой снижения издержек.
И DeepSeek, и американские ИИ-компании сейчас имеют больше средств и чипов, чем при обучении своих существующих основных моделей. Эти дополнительные чипы используются для разработки новых технологий моделей и иногда используются для обучения больших моделей, которые еще не выпущены или требуют нескольких попыток для совершенствования.
Сообщалось (хотя мы не можем подтвердить его подлинность), что DeepSeek на самом деле имеет 50 000 графических процессоров поколения Hopper⁶, и, по моим оценкам, это примерно от 1/2 до 1/3 размера графических процессоров крупных ИИ-компаний США (например, это число в 2–3 раза меньше, чем у кластера xAI «Colossus»)⁷. Стоимость этих 50 000 графических процессоров Hopper составляет примерно 1 миллиард долларов США.
Таким образом, общий объем инвестиций DeepSeek как компании (а не только стоимость обучения одной модели) не сильно отстает от инвестиций американских исследовательских лабораторий искусственного интеллекта.
Стоит отметить, что анализ «кривой масштабирования» на самом деле несколько упрощен. Разные модели имеют свои особенности и специализируются в разных областях, а значение кривой расширения представляет собой лишь грубое среднее значение, игнорирующее многие детали.
Насколько я понимаю модель Anthropic, как я уже упоминал ранее, Клод отлично умеет генерировать код и качественно взаимодействовать с пользователями, причем многие даже используют ее для личных советов или поддержки. В этом отношении, а также по некоторым другим конкретным задачам DeepSeek просто не может сравниться, и эти разрывы не отражаются напрямую в данных кривой масштабирования.
Выпуск R1 на прошлой неделе привлек большое внимание общественности и привел к падению курса акций Nvidia примерно на 17%. Но с инновационной и инженерной точки зрения R1 далеко не так интересен, как V3.
R1 просто добавляет второй этап обучения — обучение с подкреплением (об этом упоминалось в пункте 3 предыдущего раздела), который по сути является репликацией метода OpenAI в версии o1 (масштаб и эффект обоих кажутся схожими)⁸. Однако, поскольку мы все еще находимся на ранних стадиях кривой масштабирования, вполне возможно, что несколько компаний смогут обучать аналогичные модели, при условии, что у них есть надежная предварительно обученная базовая модель.
Стоимость обучения R1 на базе существующей V3 может быть очень низкой. Таким образом, мы находимся на интересном «перекрестке», где несколько компаний могут обучать модели с отличными возможностями вывода. Но такая ситуация продлится недолго, поскольку модель продолжает развиваться вверх по кривой расширения, и это окно «нижнего порога» скоро закончится.
Контроль над экспортом чипов в Китай
Приведенный выше анализ на самом деле является лишь подготовкой к теме, которая меня действительно волнует – контроль экспорта чипов в Китай. В сочетании с предыдущими фактами я думаю, что текущая ситуация выглядит следующим образом:
Тенденция в обучении искусственному интеллекту такова, что компании будут вкладывать все больше и больше денег в обучение более мощных моделей. Хотя стоимость обучения моделей с тем же уровнем интеллекта продолжает падать, экономическая ценность моделей ИИ настолько высока, что сэкономленные средства почти сразу же реинвестируются в обучение более мощных моделей, в то время как общие расходы остаются на том же высоком уровне.
Если метод оптимизации эффективности, разработанный DeepSeek, не будет освоен американскими лабораториями, то вскоре его будут использовать лаборатории в США и Китае для обучения моделей ИИ стоимостью в миллиарды долларов. Эти новые модели будут работать лучше, чем модели стоимостью в несколько миллиардов долларов, которые первоначально планировалось обучить, но инвестиции по-прежнему будут составлять миллиарды долларов, и это число будет продолжать расти до тех пор, пока уровень интеллекта ИИ не превысит возможности почти каждого почти во всех областях.
Для создания такого ИИ, который умнее почти всех остальных, потребуются миллионы чипов, как минимум десятки миллиардов долларов финансирования, и, скорее всего, он будет реализован в 2026-2027 годах. Последнее заявление DeepSeek не изменит эту тенденцию, поскольку сокращение затрат все еще находится в пределах ожидаемого диапазона, который уже давно учтен в долгосрочных расчетах отрасли.
Это означает, что к 2026–2027 годам мир может оказаться в двух совершенно разных ситуациях. В Соединенных Штатах у нескольких компаний обязательно будут необходимые миллионы чипов (стоимостью десятки миллиардов долларов). Вопрос в том, будет ли Китай также иметь доступ к миллионам чипов⁹.
Если Китай сможет приобрести миллионы чипов, мы вступим в биполярный мир, где и США, и Китай будут иметь мощные модели искусственного интеллекта, стимулирующие развитие науки и технологий беспрецедентными темпами – то, что я называю «странами гениев в центре обработки данных».

Но биполярный мир не может долго оставаться сбалансированным. Даже если Китай и США временно будут эквивалентны в технологиях искусственного интеллекта, Китай может вложить больше талантов, средств и энергии в применение технологий искусственного интеллекта в военной области. В сочетании с огромной промышленной базой и военно-стратегическими преимуществами Китая это может позволить Китаю не только добиться доминирования в области искусственного интеллекта, но даже занять лидирующие позиции в различных областях по всему миру.
Если Китай не сможет приобрести миллионы чипов, мы, по крайней мере временно, вступим в однополярный мир, в котором только Соединенные Штаты и их союзники будут иметь самые передовые модели искусственного интеллекта. Сохранится ли эта однополярная ситуация, неизвестно, но, по крайней мере, возможно, что кратковременное преимущество может превратиться в долгосрочное преимущество, поскольку системы ИИ помогают создавать более сильный ИИ¹⁰. В этом сценарии Соединенные Штаты и их союзники могут добиться решающего и долгосрочного доминирования на мировой арене.
Таким образом, строгое соблюдение экспортного контроля¹¹ является единственным эффективным средством предотвращения получения Китаем миллионов чипов, а также является наиболее важным фактором, определяющим, станет ли мир в конечном итоге однополярным или биполярным.

Успех DeepSeek не означает, что экспортный контроль провалился. Как я уже говорил ранее, DeepSeek на самом деле обладает значительными ресурсами чипов, поэтому неудивительно, что они смогли разработать и обучить мощную модель. Они не более ограничены в ресурсах, чем американские компании, занимающиеся искусственным интеллектом, и экспортный контроль не является основной причиной их «инноваций». Они просто очень хорошие инженеры, и это как раз показывает, что Китай является серьёзным конкурентом США в сфере ИИ.
Успех DeepSeek не означает, что Китай всегда может получить необходимые ему чипы путем контрабанды или что в экспортном контроле существуют лазейки, которые невозможно закрыть. Я считаю, что экспортный контроль никогда не был направлен на то, чтобы помешать Китаю получить десятки тысяч чипов. Экономическую деятельность на миллиард долларов можно скрыть, но деятельность на 10 или даже миллиарды долларов скрыть гораздо труднее, а хитрая доставка миллионов чипов может быть физически чрезвычайно трудной.
Мы также можем посмотреть на типы чипов, которые, как сообщается, есть у DeepSeek. Согласно анализу SemiAnaанализа, существующие 50 000 чипов искусственного интеллекта DeepSeek представляют собой смесь H100, H800 и H20.
- H100 подлежат экспортному контролю с момента их появления, поэтому, если у DeepSeek есть H100, они, должно быть, были получены контрабандой. (Однако стоит отметить, что Nvidia заявила, что прогресс DeepSeek в области искусственного интеллекта «полностью соответствует правилам экспортного контроля»).
- H800 все еще можно было экспортировать в соответствии с первоначальной политикой экспортного контроля в 2022 году, но он был запрещен после обновления политики в октябре 2023 года, поэтому эти чипы могли быть отправлены до того, как запрет вступил в силу.
- H20, который менее эффективен при обучении, но более эффективен при выводе (выборке), по-прежнему разрешен к экспорту, но я думаю, что его также следует запретить.
Подводя итог, можно сказать, что чипы ИИ, принадлежащие DeepSeek, в основном включают в себя чипы, которые в настоящее время не запрещены (но должны быть запрещены), чипы, полученные до запрета, и небольшое количество чипов, которые могут быть получены путем контрабанды.
На самом деле это показывает, что экспортный контроль работает и его корректируют: если бы экспортный контроль был совершенно неэффективен, у DeepSeek, вероятно, уже была бы целая партия первоклассных чипов H100. Однако это не так, что показывает, что политика постепенно закрывает лазейки. Если мы ужесточим контроль достаточно быстро, мы сможем помешать Китаю получить доступ к миллионам чипов, увеличивая вероятность того, что Соединенные Штаты сохранят свое лидерство в области искусственного интеллекта и создадут однополярный мир.
Что касается экспортного контроля и национальной безопасности США, я хочу внести ясность:
Я не считаю DeepSeek конкурентом и не нацелен конкретно на эту компанию. Судя по интервью, исследователи DeepSeek производят впечатление умных и любопытных инженеров, которые просто хотят разработать полезную технологию.
Экспортный контроль – один из самых мощных инструментов, которые у нас есть, чтобы предотвратить это. Некоторые думают, что тот факт, что технологии искусственного интеллекта становятся все более мощными и экономически эффективными, является поводом для ослабления экспортного контроля – но это совершенно неразумно.
сноска
- 1 По поводу дистилляции моделей: В этой статье я не буду комментировать сообщения о том, перегоняет ли DeepSeek западные модели. Я предполагаю, основываясь исключительно на информации, представленной в документе DeepSeek, что они действительно обучили модель так, как они заявили.
- 2 Выпуск DeepSeek не влияет на Nvidia: На самом деле, я думаю, что выпуск модели DeepSeek явно не окажет негативного влияния на Nvidia, и падение цены акций Nvidia примерно на 17% в результате сбивает меня с толку. Логично, что выпуск DeepSeek окажет даже меньшее влияние на Nvidia, чем на другие компании, занимающиеся искусственным интеллектом. Но в любом случае основная цель моей статьи – защита политики экспортного контроля.
- 3 Подробности о том, как обучается R1. Точнее, R1 представляет собой предварительно обученную модель и подвергается лишь небольшому обучению с подкреплением (RL), что часто встречается в моделях до изменения парадигмы вывода.
- 4 DeepSeek хорошо справляется с некоторыми конкретными задачами, но эти задачи очень ограничены по объему.
- 5 Что касается «стоимости обучения в 6 миллионов долларов», упомянутой в документе DeepSeek: Эти данные приведены в документе DeepSeek, я принимаю их здесь на данный момент и не подвергаю сомнению их подлинность. Однако я сомневаюсь в правомерности этого прямого сравнения с затратами на обучение в американских компаниях, занимающихся искусственным интеллектом. 6 миллионов долларов относятся только к стоимости обучения конкретной модели, но общая стоимость исследований и разработок в области ИИ намного превышает эту цифру. Кроме того, мы не можем быть полностью уверены в подлинности $6 млн — хотя масштаб модели можно проверить, такие факторы, как количество токенов, используемых при обучении, проверить сложно.
- 6 Поправка по существующим чипам DeepSeek: В некоторых интервью я как-то говорил, что у DeepSeek «50 000 штук H100», но на самом деле это неточное изложение соответствующих отчетов, и я хотел бы исправить это здесь. H100 в настоящее время является самым известным чипом архитектуры Hopper, поэтому я предположил, что в отчете речь идет о H100. Но на самом деле в серию Hopper также входят H800 и H20, а у DeepSeek есть смесь этих трех чипов, всего 50 000 чипов. Хотя этот факт не меняет общей ситуации, его все же стоит уточнить. Я проанализирую проблемы с H800 и H20 более подробно, когда буду обсуждать экспортный контроль.
- 7 Ожидается, что разрыв в чипах между США и Китаем будет еще больше увеличиваться в вычислительных кластерах следующего поколения, в первую очередь из-за воздействия экспортного контроля.
8 Одна из основных причин, почему R1 получил широкое внимание: я думаю, что одна из причин, по которой R1 привлек огромное внимание, заключается в том, что это первая модель, которая показывает пользователю процесс «цепочки рассуждений», в то время как o1 OpenAI показывает только окончательный ответ. DeepSeek демонстрирует, что пользователи заинтересованы в прозрачных процессах рассуждения для ИИ. Чтобы внести ясность, это просто выбор дизайна пользовательского интерфейса (UI) и не имеет ничего общего с самой моделью. - 10 Цель экспортного контроля: здесь должно быть ясно, что цель не состоит в том, чтобы лишить Китай возможности извлечь выгоду из технологического прогресса ИИ — прорывы ИИ в науке, здравоохранении, качестве жизни и других областях должны принести пользу всем. Настоящая цель – не дать этим странам достичь военного господства.
Прилагаем соответствующие ссылки на отчет:
https://x.com/DarioAmodei/status/1884636410839535967
https://darioamodei.com/on-deepseek-and-export-controls
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo