Сделать видео с вашим ртом действительно идет! Это новое приложение, Meta, такое возмутительное
Этот год стал годом большого прогресса для ИИ в области производства изображений и видео.
Кто-то получил награду за цифровое искусство с изображением, сгенерированным ИИ, и победил группу людей-художников; есть приложения, такие как Tiktok, которые генерируют изображения с помощью ввода текста и превращают их в зеленый фон экрана коротких видеороликов; есть новые продукты, которые могут сделать текст Создавайте видео напрямую и напрямую реализуйте эффект «сделай видео своим ртом».
Продукт на этот раз исходит от компании Meta, которая много лет глубоко культивировала искусственный интеллект и некоторое время назад была безумно высмеяна из-за метавселенной.

▲ Мета-Метавселенная была дико высмеяна
Только на этот раз над ним нельзя издеваться, потому что у него действительно есть небольшой прорыв.
Текст в видео, что можно сделать
Теперь вы можете двигать ртом, чтобы сделать видео.
Хотя это немного преувеличено, Make-A-Video от Meta на этот раз, вероятно, действительно движется к этой цели.

В настоящее время Make-A-Video может:
- Преобразование текста в видео — превратите свое воображение в настоящие уникальные видеоролики.
- Преобразование изображений непосредственно в видео — пусть одно или два изображения движутся естественным образом
- Видео Генерация расширенного видео — введите видео, чтобы создать вариант видео
Что касается прямого создания видео из текста, Make-A-Video победил многих профессиональных студентов, изучающих анимационный дизайн. По крайней мере, это может быть любой стиль, а стоимость производства очень низкая.
Хотя официальный веб-сайт не позволяет вам напрямую создавать видео, вы можете сначала предоставить свою личную информацию, а затем Make-A-Video сначала поделится с вами любыми разработками.

На данный момент не так много случаев, которые можно увидеть, а случаи, отображаемые на официальном сайте, все еще имеют некоторые странные места в деталях. Но в любом случае тот факт, что текст можно напрямую превратить в видео, сам по себе является улучшением.
Медвежонок рисует автопортрет, и вы можете увидеть неестественную проекцию руки медведя на затененной части бумаги.

Роботы танцуют на Таймс-сквер.

Кошка держит пульт от телевизора, чтобы переключить канал, кошачьи когти очень похожи на человеческие руки, и иногда на это немного страшно смотреть.

А мохнатый ленивец в оранжевой вязаной шапке возится с ноутбуком, свет от экрана компьютера бьет ему в глаза.

Вышеперечисленные стили сюрреалистичны, а чехлы, более похожие на реальность, легче носить.
Случаи, показанные Make-A-Video, хороши, если они сосредоточены только на локальных областях, таких как крупный план художника, рисующего на холсте, лошадь, пьющая воду, и маленькая рыбка, плавающая в коралловом рифе.



А вот немного более реалистичная молодая пара, идущая под проливным дождем, выглядит очень странно: верхняя часть тела в порядке, а вот ноги нижней части тела мелькают, местами вытягиваются, как в фильме о привидениях.

Есть также видео в стиле живописи с космическими кораблями, приземляющимися на Марсе, парами в смокингах, попавшими в ловушку ливня, солнечным светом на столах и движущимися куклами-пандами. С точки зрения детализации эти видео не идеальны, но благодаря инновационному эффекту преобразования текста в видео ИИ они по-прежнему потрясающие.




Статичные картины также можно анимировать с помощью Make-A-Video — лодка движется по большим волнам.

Черепахи плавают в море.Первоначальная картинка очень естественна, но позже она становится больше похожей на вырезку на зеленом экране, что неестественно.
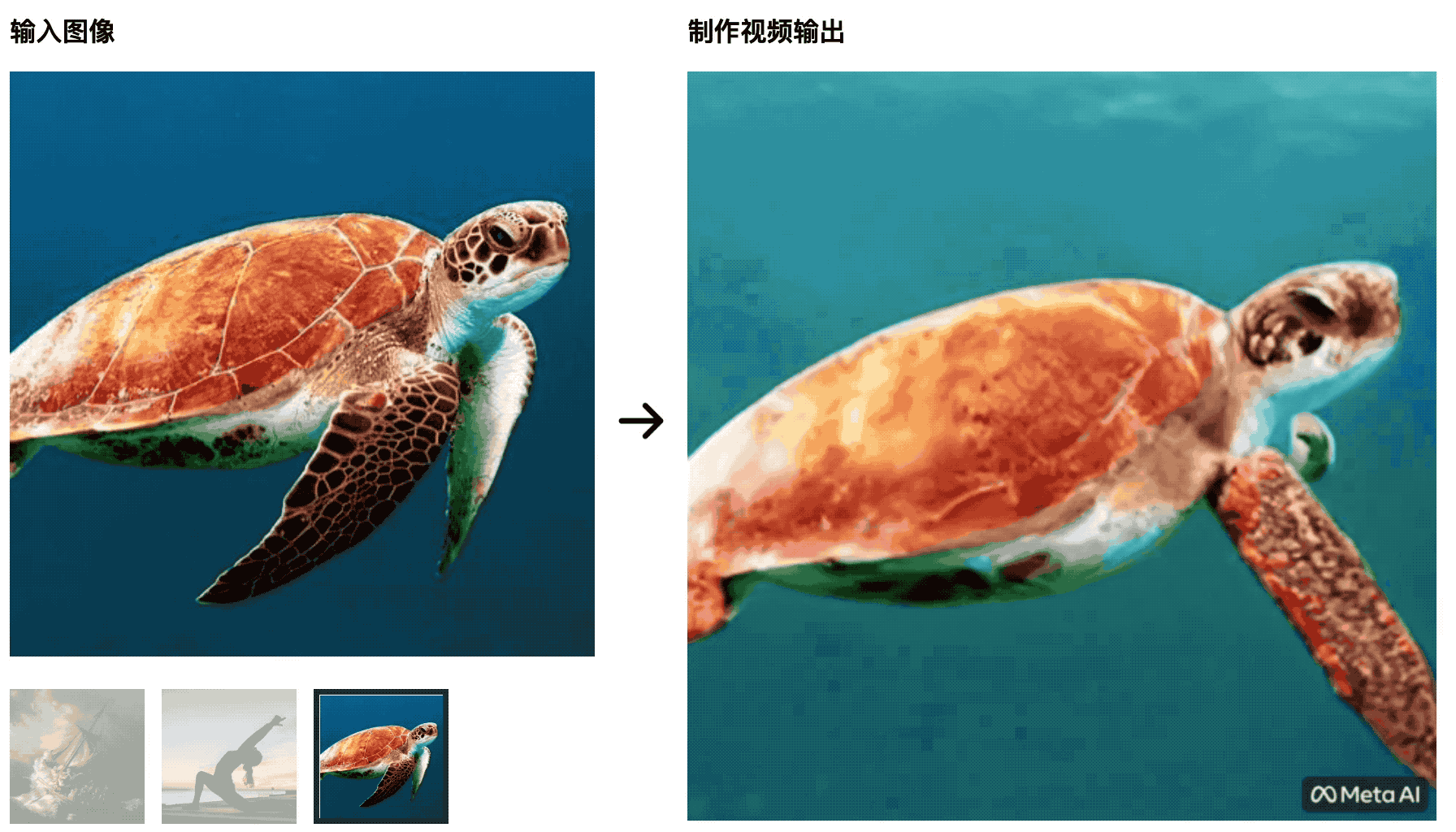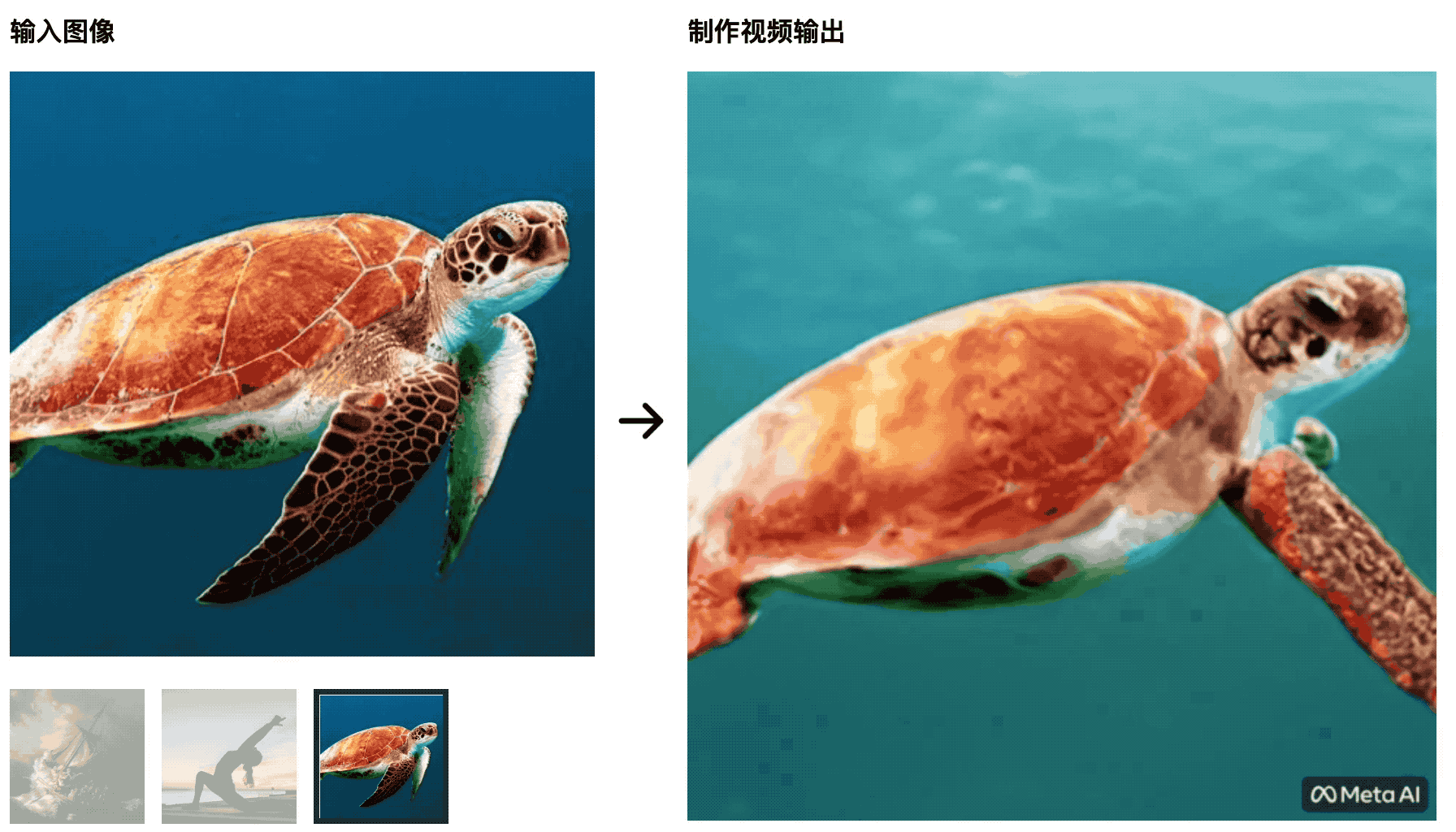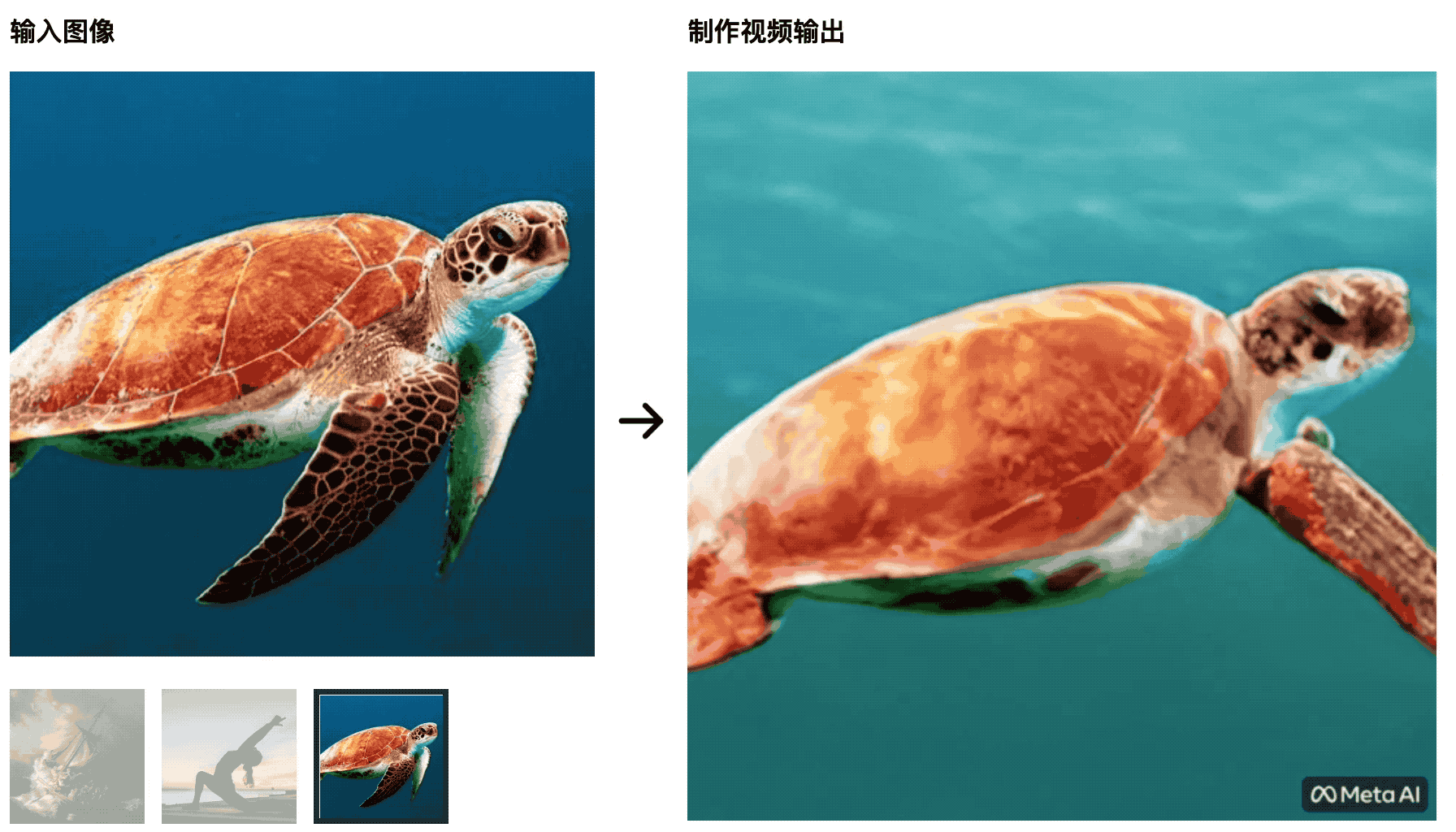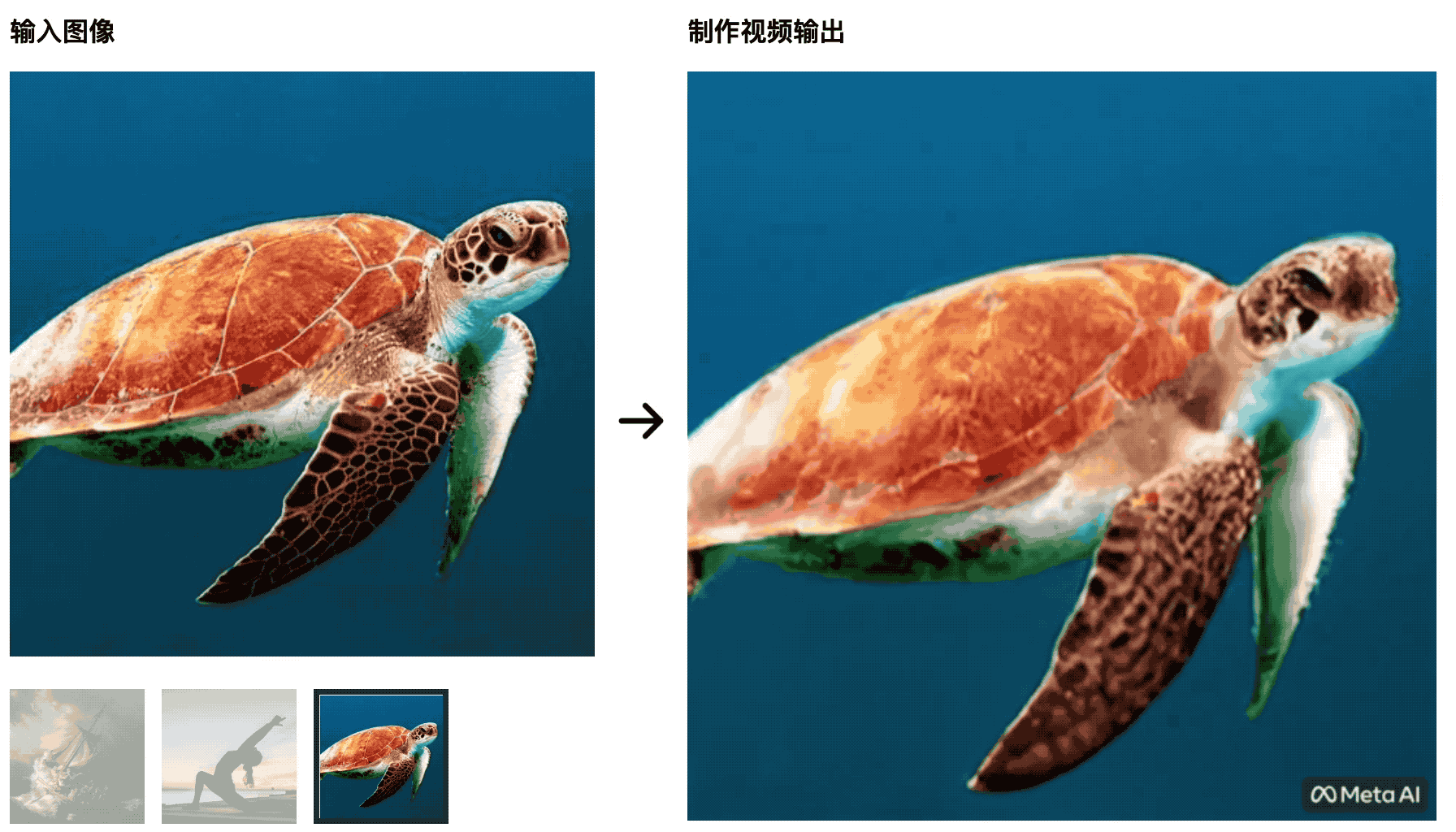
Тренер по йоге разминается под лучами восходящего солнца, а коврик для йоги будет меняться вместе с изменениями видео — этот ИИ не сможет победить студентов, изучающих кино- и телепроизводство, да и контрольные переменные плохо сделаны.

Наконец, введите видео, чтобы имитировать его стиль, чтобы создать варианты видео. Также есть 3 случая.
Одно из изменений относительно менее доработано. Видео космонавтов, порхающих в космосе, было превращено в чуть менее эстетичную версию из 4 черновых версий видео.

В видео танцующего медвежонка довольно много неожиданных изменений, по крайней мере изменилась танцевальная поза.

Что касается последнего видео с кроликом, поедающим траву, то оно самое "анненг различает меня как самца и самку". В последних 5 видео сложно узнать, кто является начальным видео, и оно выглядит очень гармонично.

Как только текст на картинке прогрессирует, видео идет
В разделе « После AlphaGo снова полностью разрушается человеческое познание », мы однажды представили приложение для создания изображений DALL·E. Кто-то использовал его для создания изображений, чтобы конкурировать с людьми-художниками и в конечном итоге победить.
Можно сказать, что Make-A-Video, которое мы видим сейчас, является видеоверсией DALL·E (основная версия) — она похожа на DALL·E 18 месяцев назад, с огромным прорывом, но нынешний эффект может не дать люди довольны.

▲ Расширенная картина, созданная DALL·E
Можно даже сказать, что это продукт, который стоит на плечах гиганта DALL·E и делает успехи. По сравнению с изображениями, сгенерированными текстом, Make-A-Video не внес слишком много новых изменений в серверную часть.
«Мы увидели, что модели, описывающие изображения, сгенерированные текстом, также удивительно эффективны при создании коротких видеороликов», — сообщают исследователи в своей статье.

▲Отмеченные наградами работы, описывающие текстовые изображения.
В настоящее время видеоролики, созданные Make-A-Video, имеют 3 преимущества:
- Ускоренное обучение моделей T2V (текст в видео)
- Нет необходимости в парных данных преобразования текста в видео
- Преобразованное видео наследует стиль исходного изображения/видео.
Недостатки у этих изображений, безусловно, есть, и упомянутая неестественность вся реальна. И они не похожи на видео, рожденные в эту эпоху, качество изображения размыто, движение жесткое, согласование звука не поддерживается, длина видео не более 5 секунд, а разрешение 64 x 64px.

▲ В этом видео есть несколько очень странных кадров языка и рук собаки.
У первой модели CogVideo, способной напрямую синтезировать видео из текста, выпущенной несколько месяцев назад группой исследователей из Университета Цинхуа и Научно-исследовательского института Чжиюань (BAAI), тоже есть такая проблема. Основанный на крупномасштабной предварительно обученной архитектуре Transformer, он предлагает иерархическую стратегию обучения с несколькими частотами кадров, которая может эффективно выравнивать текст и видеоклипы, но не выдерживает тщательной проверки.
Но кто сказал, что 18 месяцев спустя Make-A-Video и CogVideo не будут делать видео лучше, чем большинство других?

▲ Видео, созданное CogVideo — в настоящее время поддерживается только китайское поколение.
Хотя выпущено не так много инструментов для преобразования текста в видео, многие из них находятся в пути. После выпуска Make-A-Video разработчики стартапа StabilityAI публично заявили: «Наше (приложение для преобразования текста в видео) будет быстрее и лучше и применимо для большего количества людей».
Конкуренция лучше, и все более реалистичная функция преобразования текста в изображение является лучшим доказательством.
#Добро пожаловать на официальный аккаунт Айфанер в WeChat: Айфанер (WeChat: ifanr), в ближайшее время вам будет представлен более интересный контент.
Love Faner | Исходная ссылка · Просмотреть комментарии · Sina Weibo