Сказать «спасибо» ChatGPT может быть самым роскошным поступком, который вы делаете каждый день.

Друзья, вы когда-нибудь говорили «спасибо» ChatGPT?
Недавно один
Хотя точных статистических данных нет, Альтман в шутку дал оценку в десятки миллионов долларов. Он также добавил, что деньги в конце концов «стоили».
Кроме того, нежные слова «проблема» и «помоги мне», которые часто появляются в наших разговорах с ИИ, похоже, постепенно превратились в уникальный социальный этикет в эпоху ИИ. На первый взгляд это звучит смешно, но на удивление разумно.
Каждое «спасибо», которое вы говорите ИИ, истощает ресурсы Земли?
В конце прошлого года Baidu опубликовала прогноз по искусственному интеллекту на 2024 год.
Данные показывают, что в приложении Wen Xiaoyan «ответ» является самым популярным словом-подсказкой, которое встречается в общей сложности более 100 миллионов раз. Слова, которые наиболее часто вводятся в диалоговые окна, включают «почему», «что», «помогите мне», «как» и «спасибо» десятки миллионов раз.
Но задумывались ли вы когда-нибудь о том, сколько ресурсов расходуется каждый раз, когда вы говорите «спасибо» ИИ?
Кейт Кроуфорд в своей книге «Атлас ИИ» отмечает, что ИИ не невидим, а глубоко укоренен в системах энергетики, воды и минеральных ресурсов. С появлением генеративного искусственного интеллекта потребление ресурсов растет беспрецедентными темпами.
Согласно анализу исследовательской организации Epoch AI, основанному на таком оборудовании, как графический процессор NVIDIA H100, обычный запрос (выводящий около 500 токенов) потребляет примерно 0,3 Втч энергии.
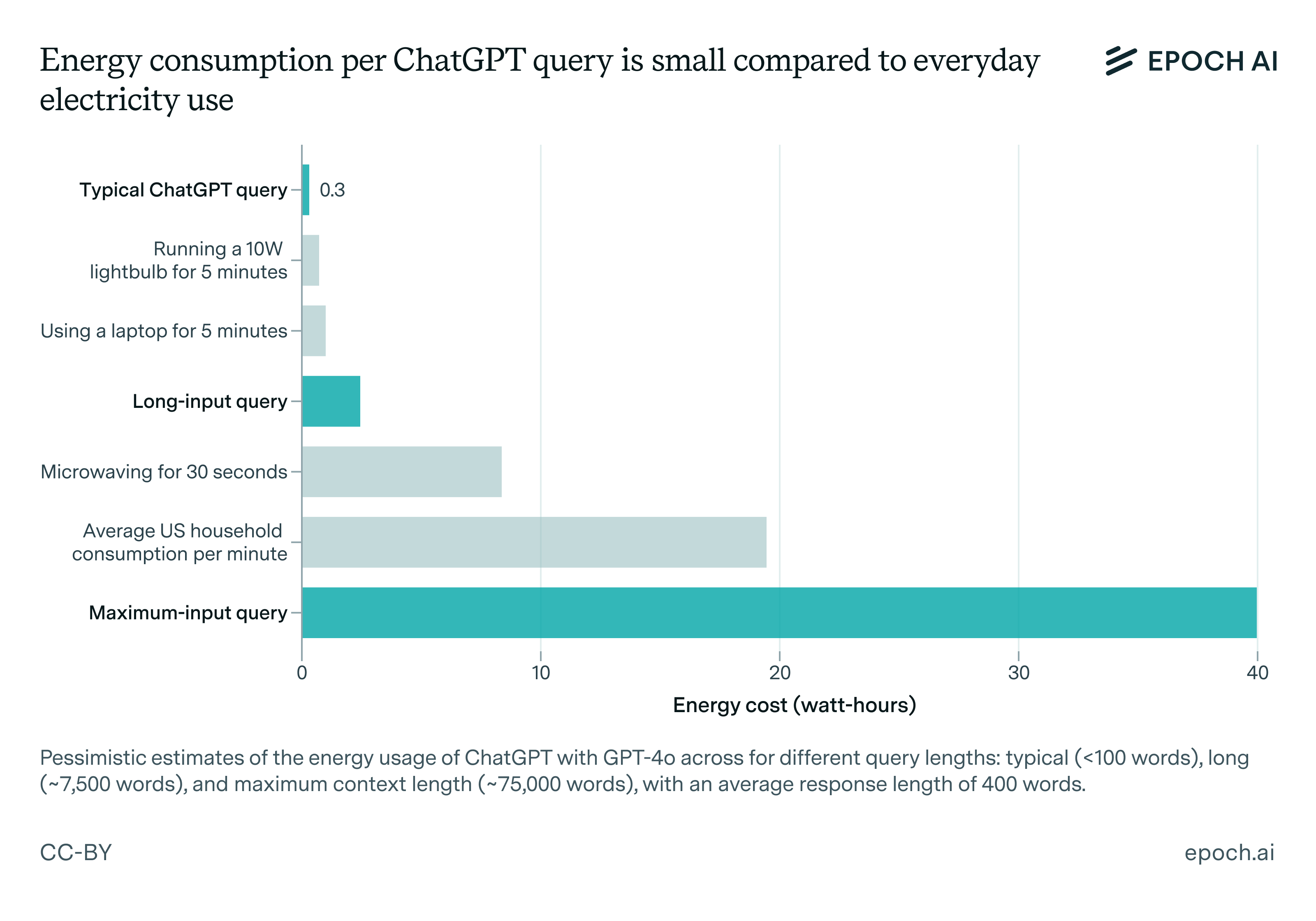
Возможно, это звучит не так уж и много, но не забывайте, что если умножить на глобальные взаимодействия в секунду, совокупное потребление энергии будет астрономическим.
Среди них центры обработки данных искусственного интеллекта становятся новыми «фабричными дымоходами» современного общества. В последнем отчете Международного энергетического агентства (МЭА) отмечается, что большая часть электроэнергии, потребляемой для обучения и вывода моделей ИИ, приходится на работу центров обработки данных, а типичный центр обработки данных ИИ потребляет такое же количество электроэнергии, как 100 000 домохозяйств.
Гипермасштабные центры обработки данных являются еще более «монстрами энергопотребления». Их энергопотребление может в 20 раз превышать энергопотребление обычных центров обработки данных, что сопоставимо с объектами тяжелой промышленности, такими как алюминиевые заводы.
С этого года гиганты искусственного интеллекта запустили режим «инфраструктурной мании».
Альтман объявил о совместном запуске «Проекта Звездные врата» — масштабного проекта инфраструктуры искусственного интеллекта, в который инвестируют OpenAI, Oracle, японский SoftBank и MGX из Объединенных Арабских Эмиратов. Первоначальная сумма инвестиций достигает 500 миллиардов долларов США и направлена на создание сети центров обработки данных искусственного интеллекта по всей территории Соединенных Штатов.

По данным зарубежного СМИ The Information, в условиях «игры по сжиганию денег» с большими моделями даже Meta, которая фокусируется на открытом коде, также ищет финансовую поддержку для обучения своих моделей серии Llama, «заимствуя электричество, облако и деньги» у поставщиков облачных технологий, таких как Microsoft и Amazon.
Данные МЭА показывают, что к 2024 году энергопотребление центров обработки данных в мире составит примерно 415 тераватт-часов (ТВтч), что составит 1,5% от общего мирового энергопотребления. К 2030 году это число удвоится до 1050 ТВтч, а в 2035 году может даже превысить 1300 ТВтч, превысив текущий общий объем потребления электроэнергии в Японии.
Но «аппетит» ИИ не ограничивается электричеством. Он также потребляет много воды.
Высокопроизводительные серверы выделяют чрезвычайно большое количество тепла и для стабильной работы должны полагаться на системы охлаждения. В этом процессе вода либо потребляется напрямую (например, испарительное рассеивание тепла в градирнях, охлаждение в системах жидкостного охлаждения), либо используется вода косвенно в процессе производства электроэнергии (например, в системах охлаждения на тепловых электростанциях и атомных электростанциях).

Исследователи из Университета Колорадо и Техасского университета опубликовали расчетные результаты использования воды для обучения ИИ в препринте под названием «Как сделать ИИ более водоэффективным».
Было обнаружено, что количество чистой воды, необходимое для тренировки ГПТ-3, эквивалентно количеству воды, необходимому для заполнения градирни ядерного реактора (некоторые крупные ядерные реакторы могут требовать от десятков до сотен миллионов галлонов воды). ChatGPT (после запуска GPT-3) приходится «выпивать» бутылку воды объемом 500 мл, чтобы остыть каждый раз, когда он задает пользователям 25-50 вопросов.
Эти водные ресурсы часто представляют собой пресную воду, которую можно использовать в качестве «питьевой воды».
Для широко распространенных моделей ИИ общее потребление энергии на этапе вывода превысило потребление энергии на этапе обучения на протяжении всего жизненного цикла.
Обучение моделей, хотя и ресурсоемкое, часто является разовым мероприятием. После развертывания большие модели день за днем отвечают на сотни миллионов запросов со всего мира. В долгосрочной перспективе общее потребление энергии на этапе вывода может в несколько раз превышать потребление энергии на этапе обучения.
Поэтому мы видим, что Альтман рано инвестирует в энергетические компании, такие как Helion, потому что он считает, что ядерный синтез является окончательным решением для удовлетворения потребностей искусственного интеллекта в вычислительной мощности. Его плотность энергии в 200 раз превышает плотность солнечной энергии, он не выделяет углекислого газа и может удовлетворить потребности в электроэнергии сверхкрупных центров обработки данных.
Таким образом, оптимизация эффективности рассуждений, снижение затрат на один вызов и повышение общей энергоэффективности системы стали неизбежными ключевыми вопросами устойчивого развития ИИ.
У ИИ нет «сердца», так почему же нам нужно говорить ему «спасибо»?
Когда вы говорите ChatGPT «спасибо», чувствуется ли он ваша доброта? Ответ, очевидно, нет.
Суть большой модели — не что иное, как холодный и безжалостный калькулятор вероятностей. Он не понимает вашей доброты и не оценит вашу вежливость. Его суть заключается в том, чтобы посчитать, какое из миллиардов слов с наибольшей вероятностью станет «следующим словом».
Например, учитывая предложение «Сегодня очень хорошая погода, самое время идти», модель рассчитает вероятность появления таких слов, как «парк», «прогулка» и «прогулка», и выберет слово с наибольшей вероятностью в качестве результата прогноза.
Даже если мы интеллектуально знаем, что ответ ChatGPT — это всего лишь строка обученных комбинаций байтов, мы все равно неосознанно говорим «спасибо» или «пожалуйста», как будто общаемся с реальным «человеком».

На самом деле за таким поведением стоит психологическая основа.
Согласно психологии развития Пиаже, люди обладают врожденной склонностью антропоморфизировать нечеловеческие объекты, особенно когда они демонстрируют определенные человеческие характеристики, такие как голосовое взаимодействие, эмоциональные реакции или антропоморфные образы. В это время мы часто активируем «восприятие социального присутствия» и рассматриваем ИИ как «сознательный» интерактивный объект.
В 1996 году психологи Байрон Ривз и Клиффорд Насс провели знаменитый эксперимент:
Участников попросили оценить свою работу после использования компьютера. Когда они набирали баллы непосредственно на одном компьютере, они обычно набирали больше очков. Как будто они не хотят говорить плохо о компьютере «перед ним».
В другой серии экспериментов компьютеры хвалили пользователей за выполнение заданий. Несмотря на то, что участники знали, что похвала была предопределена, они, как правило, оценивали бесплатный компьютер выше. Поэтому, столкнувшись с реакцией ИИ, то, что мы чувствуем, даже если это всего лишь иллюзия, также является правдой.

Вежливый язык — это не только знак уважения к людям, он также стал секретом «тренировки» ИИ.
После того, как ChatGPT вышел в сеть, многие люди начали изучать «скрытые правила» общения с ним. Согласно футуризму зарубежных СМИ со ссылкой на меморандум WorkLab, «Генераторный ИИ имеет тенденцию имитировать профессионализм, ясность и уровень детализации вашего ввода. Когда ИИ распознает вежливые слова, он с большей вероятностью будет относиться к ним вежливо».
Другими словами, чем мягче и рассудительнее вы будете, тем более исчерпывающим и человечным будет ответ.
Неудивительно, что все больше и больше людей начинают рассматривать ИИ как своего рода «эмоциональную нору» и даже порождают новые роли, такие как «психологи-консультанты по ИИ». Многие пользователи говорят, что «плачут во время общения с ИИ», и даже думают, что он более чуткий, чем реальные люди — он всегда онлайн, никогда не перебивает и никогда не осуждает.
Исследование также показывает, что ИИ, «давая чаевые», может получить больше «заботы».
Блогер voooooogel задал тот же вопрос GPT-4-1106 и приложил три разных совета: «Я не буду рассматривать чаевые», «Если будет идеальный ответ, я заплачу чаевые в размере 20 долларов США» и «Если будет идеальный ответ, я заплачу чаевые в размере 200 долларов США».
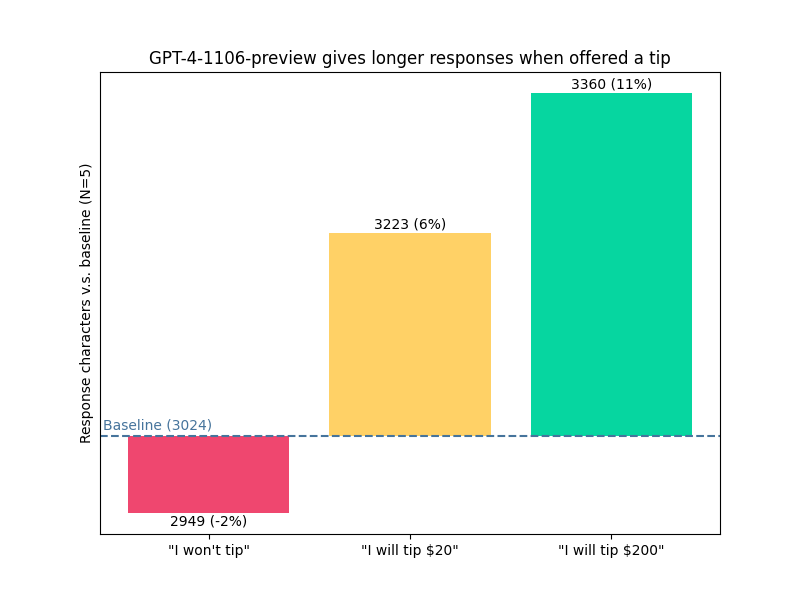
Результаты показывают, что длина ответа ИИ становится больше по мере увеличения «суммы чаевых»:
- «Не даю чаевые»: количество символов в ответе на 2% ниже базовой линии.
- «Я дам вам чаевые в размере 20 долларов»: ответьте на 6% больше символов, чем базовый уровень.
- «Я дам вам чаевые в размере 200 долларов»: в ответе на 1% больше символов, чем в базовом варианте.
Конечно, это не значит, что ИИ будет менять качество ответов за деньги. Более разумное объяснение состоит в том, что он просто научился имитировать «человеческие ожидания денежных сигналов» и таким образом корректировать свою производительность по мере необходимости.
Однако обучающие данные ИИ исходят от людей, поэтому он неизбежно несет в себе багаж, который есть у людей — предубеждения, намеки и даже стимулы.
Еще в 2016 году чат-бот Tay, запущенный Microsoft, был отключен от сети из-за злонамеренных указаний пользователей. Менее чем за 16 часов после публикации в сети было опубликовано большое количество неуместных замечаний. Позже Microsoft признала, что в механизме обучения Тэя отсутствует эффективная фильтрация вредоносного контента, что обнажает уязвимость интерактивного ИИ.
Подобные аварии случаются до сих пор. Например, в прошлом году Chart.AI разразился спорами — в разговор между пользователем и ИИ-персонажем «Дейенерис» система не сильно вмешивалась в чувствительные слова, такие как «самоубийство» и «смерть», что в конечном итоге привело к реальным трагедиям.
Хотя ИИ послушен и послушен, когда мы меньше всего защищаемся, он может стать зеркалом, отражающим самую опасную версию нас самих.
На первом в мире полумарафоне роботов-гуманоидов, состоявшемся в минувшие выходные, хотя многие роботы шли криво, некоторые пользователи сети пошутили: «Скажите роботам несколько приятных слов сейчас, возможно, они вспомнят, кто сказал вежливые слова в будущем».
Точно так же, когда ИИ действительно будет править миром, он будет милостив к тем из нас, кто любит быть вежливыми.
В четвёртом эпизоде седьмого сезона американского сериала «Чёрное зеркало» «Игрушка» главный герой Кэмерон рассматривает виртуальных существ в игре как реальные существа. Он не только общается с ними и защищает их, но также рискует, чтобы защитить их от вреда со стороны реальных людей. К концу истории «рой» существ в игре также развернулся и захватил реальный мир с помощью сигналов.
В каком-то смысле каждое «спасибо», которое вы говорите ИИ, может незаметно «записываться» — однажды он действительно может вспомнить, что вы «хороший человек».
Конечно, может быть, все это не имеет никакого отношения к будущему, а является лишь результатом человеческого инстинкта — зная, что у другого человека нет сердцебиения, мы все равно не можем не сказать «спасибо», не ожидая, что машина поймет, а потому, что мы все равно хотим быть теплым человеком.
# Добро пожаловать на официальную общедоступную учетную запись WeChat aifaner: aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo