DeepSeek доминирует в App Store: неделя, на которой китайский искусственный интеллект вызвал землетрясение в технологическом мире США

На прошлой неделе модель DeepSeek R1 из Китая всколыхнула весь зарубежный круг ИИ.
С одной стороны, он достигает производительности, сравнимой с OpenAI o1, при меньших затратах на обучение, демонстрируя преимущества Китая в инженерных возможностях и масштабных инновациях, с другой стороны, он также поддерживает дух открытого исходного кода и стремится делиться техническими подробностями;
Недавно исследовательская группа Цзяи Пана, кандидата наук из Калифорнийского университета в Беркли, успешно воспроизвела ключевую технологию DeepSeek R1-Zero — «Ага Момент» — по очень низкой цене (меньше, чем в США). 30 долларов).

Поэтому неудивительно, что генеральный директор Meta Цукерберг, обладатель премии Тьюринга Янн ЛеКун и генеральный директор Deepmind Демис Хассабис высоко отзывались о DeepSeek.
Поскольку популярность DeepSeek R1 продолжает расти, сегодня днем приложение DeepSeek App временно столкнулось с ситуацией с занятостью сервера из-за резкого увеличения числа посещений пользователей и даже на какое-то время «зависло».
Генеральный директор OpenAI Сэм Альтман только что попытался раскрыть лимит использования o3-mini, чтобы привлечь внимание к заголовкам международных СМИ — участники ChatGPT Plus могут запрашивать 100 раз в день.
Однако мало что известно о том, что до того, как она приобрела известность, материнская компания DeepSeek Huanfang Quantitative фактически была одной из ведущих компаний в отечественной сфере прямых количественных прямых инвестиций.
Модель DeepSeek шокировала Силиконовую долину, а содержание золота в ней продолжает расти
26 декабря 2024 года DeepSeek официально выпустила большую модель DeepSeek-V3.
Эта модель показала отличные результаты в многочисленных тестах производительности, превосходя ведущие модели в отрасли, особенно в таких областях, как вопросы и ответы на знания, обработка длинного текста, генерация кода и математические возможности. Например, в таких интеллектуальных задачах, как MMLU и GPQA, производительность DeepSeek-V3 близка к международной топ-модели Claude-3.5-Sonnet.
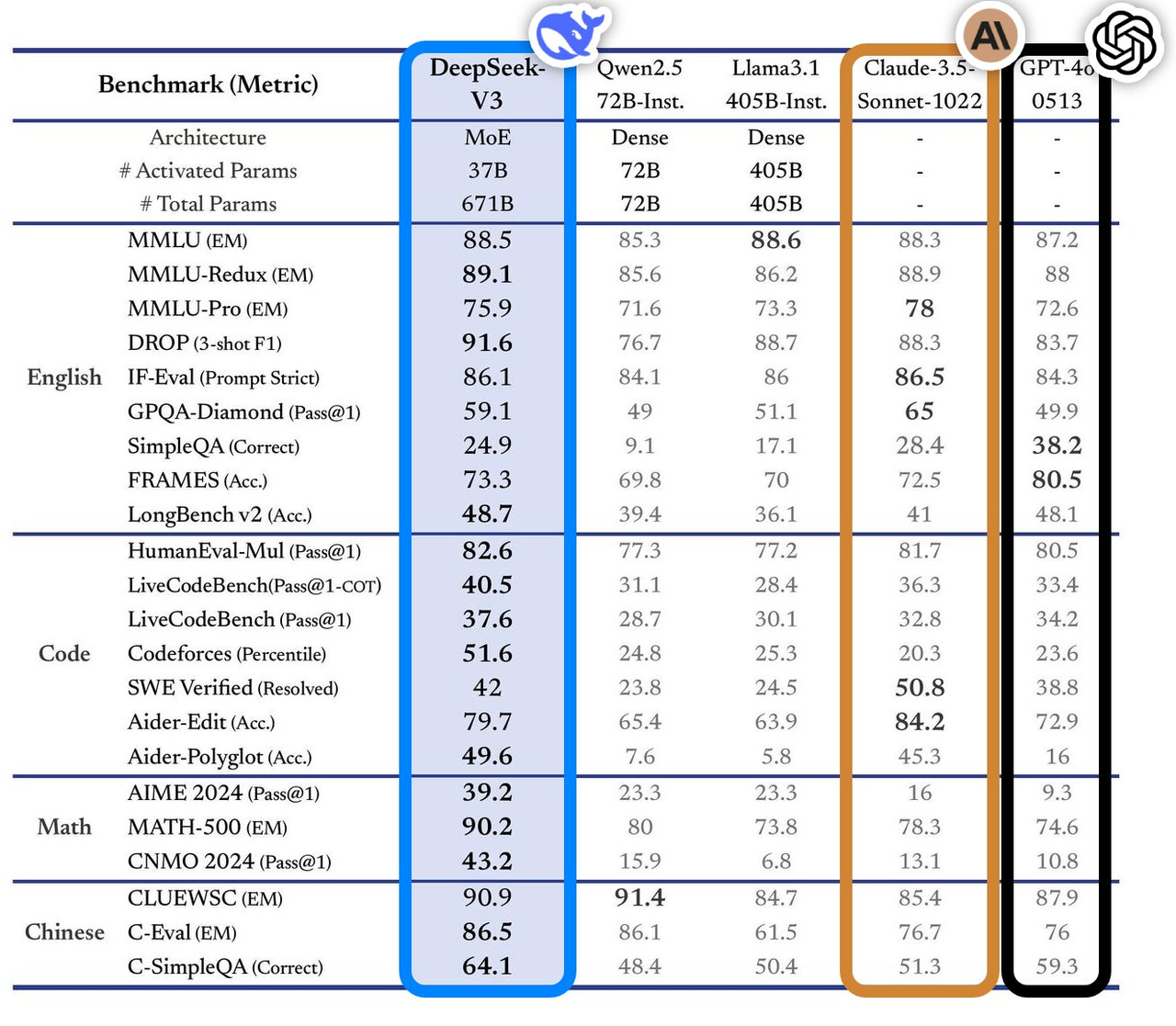
С точки зрения математических способностей он установил новые рекорды в таких тестах, как AIME 2024 и CNMO 2024, превзойдя все известные модели с открытым и закрытым исходным кодом. При этом скорость его генерации увеличилась на 200% по сравнению с предыдущим поколением, достигнув 60 TPS, что значительно улучшает пользовательский опыт.
Согласно анализу независимого оценочного сайта Artificial Analysis, DeepSeek-V3 превосходит другие модели с открытым исходным кодом по многим ключевым показателям и по производительности находится на одном уровне с лучшими в мире моделями с закрытым исходным кодом GPT-4o и Claude-3.5-Sonnet.
Основные технические преимущества DeepSeek-V3 включают в себя:
- Смешанная экспертная архитектура (MoE): DeepSeek-V3 имеет 671 миллиард параметров, но в реальной работе для каждого входа активируется только 37 миллиардов параметров. Этот метод выборочной активации значительно снижает вычислительные затраты при сохранении высокой производительности.
- Многоголовое скрытое внимание (MLA). Эта архитектура была проверена в DeepSeek-V2 и позволяет обеспечить эффективное обучение и вывод.
- Стратегия балансировки нагрузки без вспомогательных потерь. Эта стратегия предназначена для минимизации негативного влияния балансировки нагрузки на производительность модели.
- Цель обучения прогнозированию мультитокенов: эта стратегия улучшает общую производительность модели.
- Эффективная среда обучения. Используя структуру HAI-LLM, она поддерживает 16-канальный конвейерный параллелизм (PP), 64-канальный экспертный параллелизм (EP) и параллелизм данных ZeRO-1 (DP), а также снижает затраты на обучение за счет различных методов оптимизации. .
Что еще более важно, стоимость обучения DeepSeek-V3 составляет всего 5,58 миллиона долларов США, что намного ниже, чем GPT-4, стоимость обучения которого составляет 78 миллионов долларов США. Более того, цены на услуги API в прошлом по-прежнему остаются дружелюбными к людям.
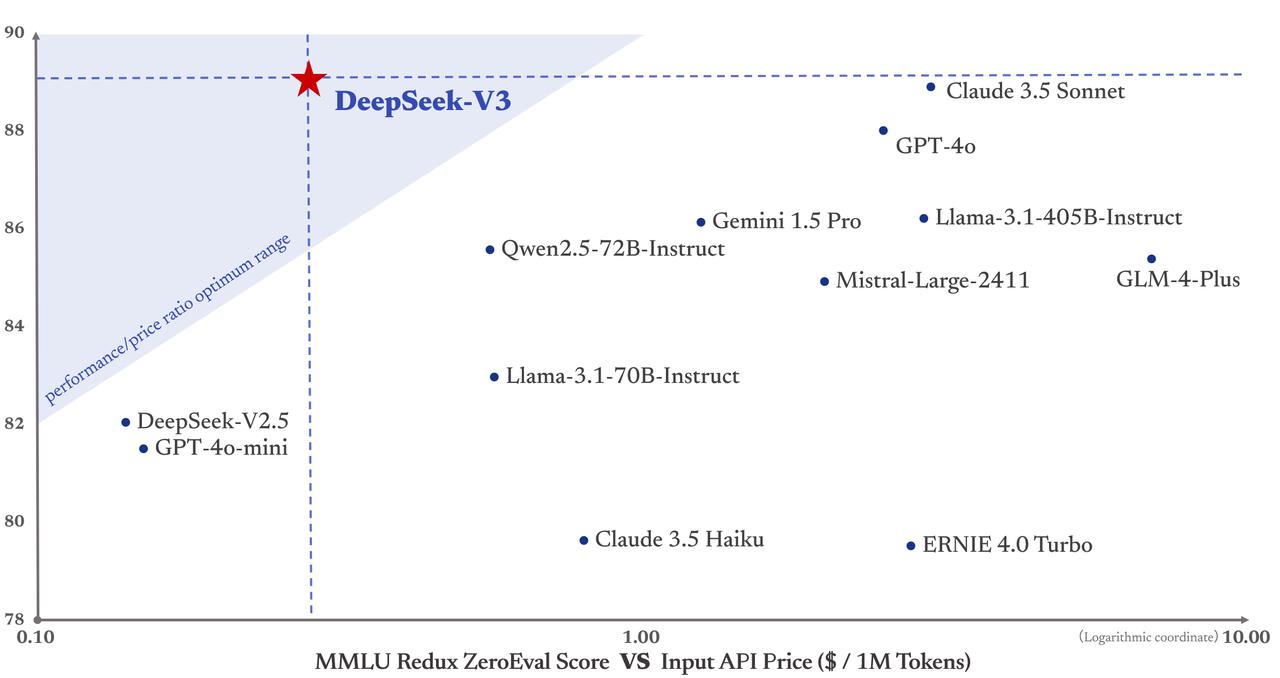
Входные токены стоят всего 0,5 юаня (попадание в кэш) или 2 юаня (промах в кэше) за миллион, а выходные токены стоят всего 8 юаней за миллион.
Газета Financial Times охарактеризовала его как «тёмную лошадку, которая шокировала международное технологическое сообщество» и полагала, что его производительность сопоставима с показателями американских конкурирующих моделей, таких как хорошо финансируемая OpenAI. Основатель Maginative Крис Маккей далее отметил, что успех DeepSeek-V3 может переопределить устоявшиеся методы разработки моделей ИИ.
Другими словами, успех DeepSeek-V3 также рассматривается как прямой ответ на экспортные ограничения США на вычислительную мощность. Это внешнее давление вместо этого стимулировало инновации в Китае.
Основатель DeepSeek Лян Вэньфэн, скромный гений из Чжэцзянского университета
Рост DeepSeek лишил Силиконовую долину бессонницы Лян Вэньфэн, основатель этой модели, всколыхнувшей мировую индустрию искусственного интеллекта, прекрасно объясняет траекторию роста гениев в традиционном китайском понимании — успех молодых, длительный успех.
Хороший руководитель компании, занимающейся искусственным интеллектом, должен понимать как технологии, так и бизнес, быть одновременно дальновидным и прагматичным, иметь смелость для инноваций и обладать инженерной дисциплиной. Этот вид сложного таланта сам по себе является дефицитным ресурсом.
В 17 лет он поступил в Чжэцзянский университет по специальности информационная и электронная инженерия. В 30 лет он основал Hquant и начал возглавлять команду по исследованию полностью автоматизированной количественной торговли. История Лян Вэньфэна доказывает, что гений всегда делает правильные вещи в нужное время.

- 2010: С запуском фьючерсов на фондовый индекс CSI 300 количественные инвестиции открыли возможности для развития. Команда Huanfang воспользовалась моментом, и ее самостоятельные фонды быстро выросли.
- 2015: Лян Вэньфэн вместе со своими выпускниками стал соучредителем Magic Square Quantification. В следующем году он запустил первую модель искусственного интеллекта и запустил торговые позиции, созданные с помощью глубокого обучения.
- 2017: Huanfang Quantitative заявила о реализации комплексной инвестиционной стратегии на основе искусственного интеллекта.
- 2018: Сделать искусственный интеллект основным направлением развития компании.
- 2019: Масштаб управления фондом превысил 10 млрд юаней, став одним из «четырех гигантов» отечественного количественного прямых инвестиций.
- 2021: Huanfang Quantitative становится первой отечественной количественной частной инвестиционной компанией, объем которой превышает 100 миллиардов долларов.
Вы не можете просто добиться успеха и думать о компании, которая последние несколько лет сидела в стороне. Однако, как и трансформация компаний, занимающихся количественной торговлей, в ИИ, это может показаться неожиданным, но на самом деле это логично — ведь все они представляют собой высокотехнологичные отрасли, основанные на данных.
Хуан Жэньсюнь хотел продавать игровые видеокарты только для того, чтобы заработать деньги для тех из нас, кто плохо играет в игры, но он не ожидал, что станет крупнейшим в мире арсеналом ИИ. Это похоже на выход Хуанфана в область ИИ. Такая эволюция более жизнеспособна, чем крупномасштабные модели искусственного интеллекта, которые в настоящее время применяются механически во многих отраслях.
Magic Square Quantitative накопила большой опыт обработки данных и оптимизации алгоритмов в процессе количественных инвестиций. Она также имеет большое количество чипов A100, которые обеспечивают надежную аппаратную поддержку для обучения моделей искусственного интеллекта. С 2017 года Huanfang широко развернула вычислительные мощности искусственного интеллекта и создала высокопроизводительные вычислительные кластеры, такие как «Yinghuo 1» и «Yinghuo 2», чтобы обеспечить мощную вычислительную мощность для обучения моделей искусственного интеллекта.

В 2023 году компания Magic Square Quantification официально учредила DeepSeek, чтобы сосредоточиться на разработке крупных моделей искусственного интеллекта. DeepSeek унаследовала накопленные Magic Quantitative технологии, таланты и ресурсы и быстро заняла свое место в области искусственного интеллекта.
В подробном интервью Undercurrent основатель DeepSeek Лян Вэньфэн также продемонстрировал уникальное стратегическое видение.
В отличие от большинства китайских компаний, которые предпочитают копировать архитектуру Llama, DeepSeek начинает непосредственно со структуры модели, просто чтобы достичь амбициозной цели AGI.
Лян Вэньфэн не скрывает существующего разрыва. В настоящее время существует значительный разрыв между ИИ Китая и ведущими международными уровнями. Огромный разрыв в структуре модели, динамике обучения и эффективности данных требует в 4 раза большей вычислительной мощности для достижения того же эффекта.

▲Изображение из скриншота CCTV News
Такое отношение к решению проблем напрямую связано с многолетним опытом Лян Вэньфэна в Хуанфане.
Он подчеркнул, что открытый исходный код — это не только обмен технологиями, но и выражение культуры. Настоящий ров заключается в постоянной способности команды к инновациям. Уникальная организационная культура DeepSeek поощряет инновации снизу вверх, преуменьшает значение иерархии и ценит энтузиазм и креативность талантов.
Команда в основном состоит из молодых людей из ведущих университетов и использует модель естественного разделения труда, позволяющую сотрудникам исследовать и сотрудничать независимо. При подборе персонала мы ценим энтузиазм и любопытство сотрудников, а не опыт и опыт в традиционном смысле этого слова.
Что касается перспектив отрасли, Лян Вэньфэн считает, что ИИ переживает период бурного развития технологических инноваций, а не бурного применения. Он подчеркнул, что Китаю нужно больше оригинальных технологических инноваций, и он не может вечно оставаться на стадии имитации. Ему нужно, чтобы люди стояли на переднем крае технологий.
Несмотря на то, что такие компании, как OpenAI, в настоящее время лидируют, возможности для инноваций все еще существуют.

Переворачивая Силиконовую долину, Deepseek вызывает беспокойство в зарубежных кругах искусственного интеллекта
Хотя в отрасли существуют разные мнения о DeepSeek, мы также собрали некоторые комментарии от инсайдеров отрасли.
Джим Фан, руководитель проекта NVIDIA GEAR Lab, высоко оценил DeepSeek-R1.
Он отметил, что это означает, что неамериканские компании выполняют первоначальную открытую миссию OpenAI и добиваются влияния, раскрывая оригинальные алгоритмы и кривые обучения. Кстати, это также содержит волну OpenAI.
DeepSeek-R1 не только открыл исходный код серии моделей, но и раскрыл все секреты обучения. Возможно, это первые проекты с открытым исходным кодом, демонстрирующие значительный и продолжающийся рост маховика RL.
Влияние может быть достигнуто с помощью легендарных проектов, таких как «Внутренняя реализация ASI» или «Strawberry Project», или просто путем раскрытия оригинального алгоритма и кривой обучения matplotlib.
Марк Андрисен, основатель A16Z, ведущей венчурной компании Уолл-стрит, считает, что DeepSeek R1 — это один из самых удивительных и впечатляющих прорывов, которые он когда-либо видел. Будучи открытым исходным кодом, это далеко идущий подарок миру.
Лу Цзин, бывший старший научный сотрудник Tencent и научный сотрудник в области искусственного интеллекта в Пекинском университете, проанализировал ситуацию с точки зрения накопления технологий. Он отметил, что DeepSeek не стал вдруг популярным. Он унаследовал многие инновации в версии модели предыдущего поколения. Соответствующая архитектура модели и инновации в алгоритмах были многократно проверены, и это неизбежно потрясет отрасль.
Янн ЛеКун, лауреат премии Тьюринга и главный научный сотрудник Меты в области искусственного интеллекта, выдвинул новую точку зрения:
«Для тех, кто после просмотра результатов DeepSeek думает, что «Китай превосходит США в области искусственного интеллекта», ваша интерпретация неверна. Правильная интерпретация должна звучать так: «Модель с открытым исходным кодом превосходит проприетарную модель». "
Комментарии генерального директора Deepmind Демиса Хассабиса выразили некоторую обеспокоенность:
«То, чего он (DeepSeek) достиг, очень впечатляет, и я думаю, что нам нужно подумать о том, как сохранить лидерство западных передовых моделей. Я думаю, что Запад все еще впереди, но, безусловно, Китай обладает чрезвычайно сильными инженерными возможностями и возможностями масштабирования. "
Генеральный директор Microsoft Сатья Наделла заявил на Всемирном экономическом форуме в Давосе, Швейцария, что DeepSeek эффективно разработал модель с открытым исходным кодом, которая не только хорошо работает в вычислениях, но и чрезвычайно эффективна в суперкомпьютерах.
Он подчеркнул, что Microsoft должна отреагировать на эти прорывные события в Китае с наивысшим приоритетом.
Оценка генерального директора Meta Цукерберга была более глубокой. Он считал, что техническая мощь и производительность, продемонстрированные DeepSeek, были впечатляющими, и отметил, что разрыв в области искусственного интеллекта между Китаем и Соединенными Штатами уже минимален, и полный спринт Китая добился успеха. конкуренция более жесткая.
Реакция конкурентов, пожалуй, лучшая поддержка DeepSeek. Согласно сообщениям сотрудников Meta анонимного рабочего сообщества TeamBlind, появление DeepSeek-V3 и R1 повергло команду Meta по генеративному искусственному интеллекту в панику.
Мета-инженеры спешат проанализировать технологию DeepSeek и попытаться скопировать из нее любую возможную технологию.
Причина в том, что стоимость обучения DeepSeek-V3 составляет всего 5,58 миллиона долларов США, что даже меньше годовой зарплаты некоторых руководителей Meta. Такое несоответствие в соотношении «затраты-выпуск» ставит руководство Meta под огромное давление, когда он объясняет свой огромный бюджет на исследования и разработки в области искусственного интеллекта.

Международные средства массовой информации также уделили большое внимание развитию DeepSeek.
Газета Financial Times отметила, что успех DeepSeek подорвал традиционное понимание того, что «исследования и разработки в области ИИ должны опираться на огромные инвестиции», и доказывает, что точные технические маршруты также могут привести к отличным результатам исследований. Что еще более важно, самоотверженный обмен технологическими инновациями со стороны команды DeepSeek сделал эту компанию, которая уделяет больше внимания исследовательской ценности, исключительно сильным конкурентом.
The Economist заявил, что, по его мнению, быстрые прорывы Китая в экономической эффективности технологий искусственного интеллекта начали подрывать технологические преимущества Соединенных Штатов, что может повлиять на повышение производительности и потенциал экономического роста Соединенных Штатов в следующем десятилетии.

The New York Times рассматривает это с другой стороны. DeepSeek-V3 по производительности эквивалентен высокопроизводительным чат-ботам американских компаний, но стоимость значительно снижается.
Это показывает, что даже в условиях контроля над экспортом чипов китайские компании могут конкурировать за счет инноваций и эффективного использования ресурсов. Более того, политика правительства США по ограничению использования чипов может оказаться контрпродуктивной, поскольку вместо этого она будет способствовать инновационным прорывам Китая в области технологий искусственного интеллекта с открытым исходным кодом.
DeepSeek «сообщил не о той двери», заявив, что это GPT-4.
На фоне похвал DeepSeek также столкнулся с некоторыми противоречиями.
Многие посторонние считают, что DeepSeek могла использовать выходные данные таких моделей, как ChatGPT, в качестве учебных материалов в процессе обучения. С помощью технологии дистилляции моделей «знания» этих данных переносятся в собственную модель DeepSeek.
Такая практика не является редкостью в сфере искусственного интеллекта, но скептики обеспокоены тем, использовал ли DeepSeek выходные данные модели OpenAI без полного раскрытия информации. Похоже, это отражается на самосознании DeepSeek-V3.
Ранее пользователи обнаружили, что на вопрос о личности модели она приняла себя за GPT-4.
Высококачественные данные всегда были важным фактором в развитии ИИ. Даже OpenAI не может избежать разногласий по поводу сбора данных. New York Times вынесла решение в первой инстанции. Прежде чем ботинки приземлились, было добавлено новое дело.
Таким образом, DeepSeek также получил публичное признание от Сэма Альтмана и Джона Шульмана.
«(Относительно) легко скопировать то, что, как вы знаете, будет работать. Очень сложно сделать что-то новое, рискованное и сложное, когда вы не знаете, сработает ли это».

Однако команда DeepSeek в техническом отчете R1 дала понять, что не использует выходные данные модели OpenAI, и заявила, что высокая производительность была достигнута за счет обучения с подкреплением и уникальной стратегии обучения.
Например, применяется многоэтапный метод обучения, включающий базовое обучение модели, обучение с подкреплением (RL), тонкую настройку и т. д. Этот многоэтапный метод циклического обучения помогает модели усваивать различные знания и способности на разных этапах.
Экономия денег — это тоже техническая работа, и технология DeepSeek — лучшее решение.
В техническом отчете DeepSeek-R1 упоминается примечательное открытие, которое представляет собой «момент ага», произошедший в процессе нулевого обучения R1. На середине этапа обучения модели DeepSeek-R1-Zero начинает активно переоценивать первоначальные идеи решения проблем и выделять больше времени на оптимизацию стратегии (например, несколько раз опробовать разные решения).
Другими словами, с помощью структуры RL ИИ может спонтанно развивать способности рассуждения, подобные человеческим, и даже превосходить ограничения установленных правил. Мы также надеемся, что это обеспечит направление для разработки более автономных и адаптивных моделей ИИ, таких как стратегии динамической корректировки при принятии сложных решений (медицинская диагностика, разработка алгоритмов).

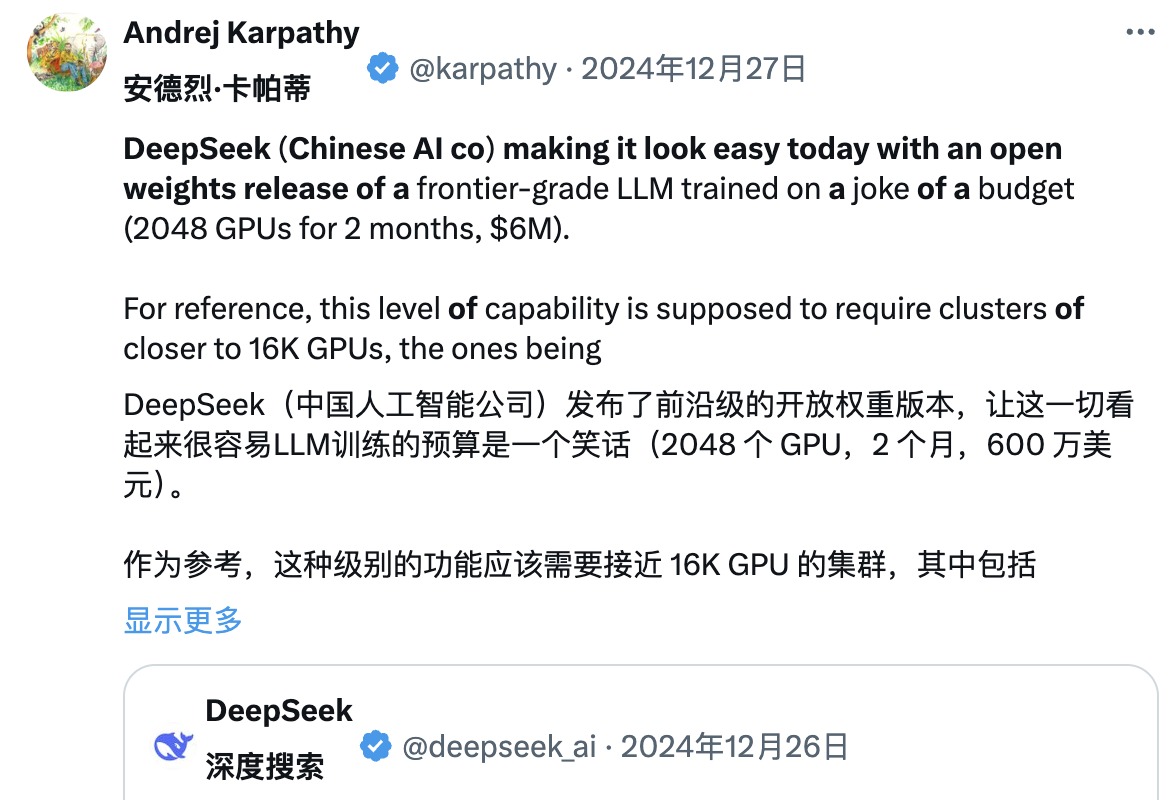
В то же время многие инсайдеры отрасли пытаются глубже проанализировать технический отчет DeepSeek. Андрей Карпати, бывший соучредитель OpenAI, сказал после выпуска DeepSeek V3:
DeepSeek (китайская компания, занимающаяся искусственным интеллектом) сегодня чувствует себя спокойно. Она публично выпустила передовую языковую модель (LLM) и завершила обучение с чрезвычайно низким бюджетом (2048 графических процессоров, продолжительность 2 месяца, стоимость 6 миллионов долларов).
Для справки: для поддержки этой возможности обычно требуется кластер из 16 000 графических процессоров, а большинство современных продвинутых систем используют примерно 100 000 графических процессоров. Например, Llama 3 (параметры 405B) использовала 30,8 миллиона графических часов, тогда как DeepSeek-V3, по-видимому, является более мощной моделью, использующей только 2,8 миллиона графических часов (около 1/11 вычислений Llama 3).
Если эта модель также покажет хорошие результаты в реальных испытаниях (например, рейтинги LLM Arena продолжаются и мой быстрый тест показал хорошие результаты), то это будет очень хорошим примером того, как исследовательские и инженерные возможности могут быть продемонстрированы в условиях ограниченности ресурсов. Впечатляющие результаты.
Означает ли это, что нам больше не нужны большие кластеры графических процессоров для обучения передовому LLM? Не совсем, но это показывает, что вы должны следить за тем, чтобы используемые вами ресурсы не тратились зря, и этот случай показывает, что оптимизация данных и алгоритмов все еще может привести к большому прогрессу. Кроме того, технический отчет также очень интересен и подробен, и его стоит прочитать.
Столкнувшись с разногласиями по поводу использования DeepSeek V3 данных ChatGPT, Карпати заявил, что большие языковые модели по сути не обладают человеческим самосознанием. Сможет ли модель правильно ответить на свою собственную личность, полностью зависит от того, создала ли команда разработчиков специальное самосознание. Осведомленность Обучающий набор, если он не обучен специально, модель будет отвечать на основе наиболее близкой информации в данных обучения.
Кроме того, тот факт, что модель идентифицирует себя как ChatGPT, не является проблемой. Учитывая повсеместное распространение данных, связанных с ChatGPT, в Интернете, этот ответ на самом деле отражает естественный феномен «появления близлежащих знаний».
Джим Фан отметил после прочтения технического отчета DeepSeek-R1:
Самым важным моментом этой статьи является то, что она полностью основана на обучении с подкреплением, без какого-либо участия обучения с учителем (SFT). Этот метод похож на AlphaZero – освоение го и сёги с нуля посредством «холодного старта» и шахмат, без имитации. игра людей-шахматистов.
– Используйте реальные вознаграждения, рассчитанные на основе жестко запрограммированных правил, а не заученные модели вознаграждений, которые можно легко «взломать» с помощью обучения с подкреплением.
– Время обдумывания модели постепенно увеличивается по мере обучения. Это не запрограммированная заранее, а спонтанная функция.
– Появляются саморефлексия и исследовательское поведение.
– Используйте GRPO вместо PPO: GRPO удаляет сеть комментаторов в PPO и вместо этого использует среднее вознаграждение из нескольких образцов. Это простой способ уменьшить использование памяти. Стоит отметить, что GRPO была изобретена командой DeepSeek в феврале 2024 года, а это действительно очень мощная команда.
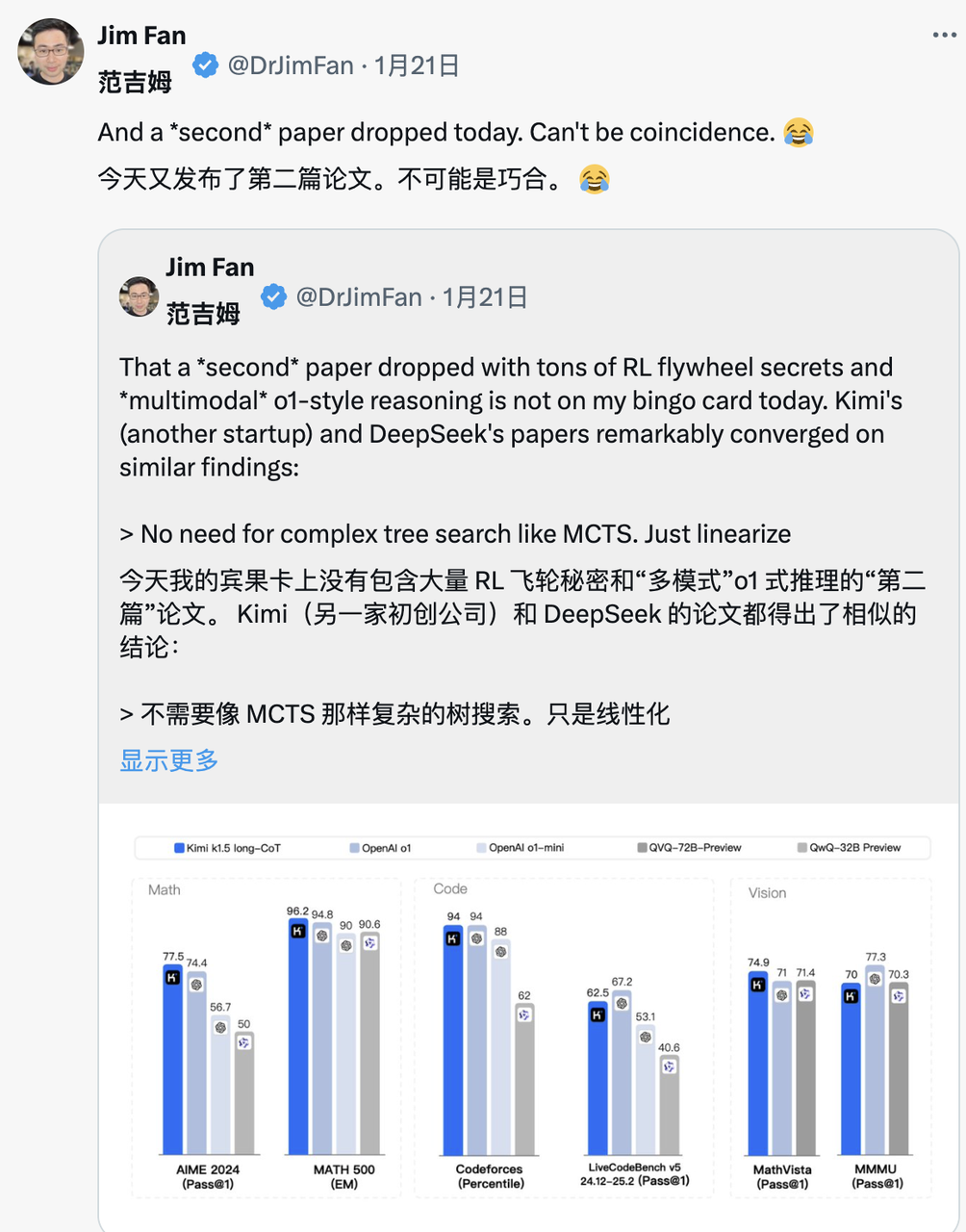
Когда в тот же день Кими также опубликовал аналогичные результаты исследования, Джим Фан обнаружил, что результаты исследований двух компаний достигли одной и той же цели:
- Все они отказались от сложных методов поиска по деревьям, таких как MCTS, и обратились к более простым траекториям линейного мышления, используя традиционные методы авторегрессионного прогнозирования.
- Все избегают использования функций значений, которые требуют дополнительных копий модели, что снижает требования к вычислительным ресурсам и повышает эффективность обучения.
- Все они отказываются от интенсивного моделирования вознаграждений и максимально полагаются на реальные результаты в качестве руководства для обеспечения стабильности обучения.
Но между ними есть и существенные различия:
- DeepSeek использует метод холодного запуска с чистым RL в стиле AlphaZero, Kimi k1.5 выбирает стратегию предварительного нагрева в стиле AlphaGo-Master и использует легкий SFT.
- DeepSeek имеет открытый исходный код под лицензией MIT, и Кими хорошо показывает себя в мультимодальных тестах производительности. Подробности проектирования бумажной системы более обширны и охватывают инфраструктуру RL, гибридные кластеры, песочницы кода и параллельные стратегии.
Однако на этом быстро меняющемся рынке ИИ лидерство часто мимолетно. Другие компании, занимающиеся моделированием, быстро извлекут уроки из опыта DeepSeek и улучшат его, и вскоре, возможно, смогут догнать его.
Инициатор ценовой войны за большие модели
Многие знают, что у DeepSeek есть название «AI Pinduoduo», но они не знают, что смысл этого названия на самом деле проистекает из ценовой войны на крупные модели, которая началась в прошлом году.
6 мая 2024 года DeepSeek выпустила модель MoE с открытым исходным кодом DeepSeek-V2, которая достигла двойного прорыва в производительности и стоимости благодаря инновационным архитектурам, таким как MLA (многоголовый механизм скрытого внимания) и MoE (смешанная экспертная модель).
Стоимость вывода была снижена до всего 1 юаня за миллион токенов, что на тот момент составляло примерно одну седьмую от стоимости Llama3 70B и одну семидесятую от стоимости GPT-4 Turbo. Этот технологический прорыв позволяет DeepSeek предоставлять чрезвычайно экономически эффективные услуги без взимания каких-либо денег, а также создает огромное конкурентное давление на других производителей.
Выпуск DeepSeek-V2 вызвал цепную реакцию. ByteDance, Baidu, Alibaba, Tencent и Zhipu AI последовали этому примеру и значительно снизили цены на свои крупные модели. Последствия этой ценовой войны распространяются даже на Тихий океан, вызывая серьезную обеспокоенность в Кремниевой долине.
Поэтому DeepSeek получил прозвище «Pinduoduo искусственного интеллекта».
Столкнувшись с сомнениями внешнего мира, основатель DeepSeek Лян Вэньфэн ответил в интервью Undercurrent:
«Привлечение пользователей — не наша главная цель. С одной стороны, мы снизили цену, потому что изучаем структуру модели следующего поколения, и стоимость снизилась в первую очередь; с другой стороны, мы также чувствуем, что и API, и ИИ должен быть инклюзивным и доступным каждому».
Фактически, значение этой ценовой войны выходит далеко за рамки самой конкуренции. Более низкие входные барьеры позволяют большему количеству компаний и разработчиков получить доступ к передовому искусственному интеллекту и применять его, а также вынуждают всю отрасль переосмыслить ценовую стратегию. Именно в этот период. В результате DeepSeek начал привлекать внимание общественности и приобрел известность.
Потратив тысячи долларов на покупку конских костей, Лэй Цзюнь переманивает гениальных девушек с искусственным интеллектом
Несколько недель назад DeepSeek также произвела громкую кадровую перестановку.
Как сообщает China Business News, Лэй Цзюнь успешно переманил Луо Фули с годовой зарплатой в десятки миллионов и доверил ей важную задачу руководителя большой модельной команды Xiaomi AI Lab.
Луо Фули присоединилась к DeepSeek, дочерней компании Magic Square Quantitative, в 2022 году. Ее можно увидеть в таких важных отчетах, как DeepSeek-V2 и последняя версия R1.
Позже DeepSeek, когда-то ориентированная на сторону B, также начала раскладывать сторону C и запускать мобильные приложения. На момент публикации мобильное приложение DeepSeek занимает второе место в бесплатной версии Apple App Store, демонстрируя сильную конкурентоспособность.
Серия небольших кульминаций прославила DeepSeek, но в то же время есть и более высокие кульминации. Вечером 20 января была официально представлена сверхкрупномасштабная модель DeepSeek R1 с параметрами 660B.
Эта модель хорошо справляется с математическими задачами. Например, она достигла показателя pass@1 в AIME 2024, что немного превышает показатель OpenAI-o1, равный 97,3% в MATH-500, что эквивалентно OpenAI-o1; .
Например, что касается задач программирования, он получил рейтинг Elo 2029 года на Codeforces, превзойдя 96,3% участников-людей. В таких тестах знаний, как MMLU, MMLU-Pro и GPQA Diamond, DeepSeek R1 набрал 90,8%, 84,0% и 71,5% соответственно, что немного ниже, чем у OpenAI-o1, но лучше, чем у других моделей с закрытым исходным кодом.
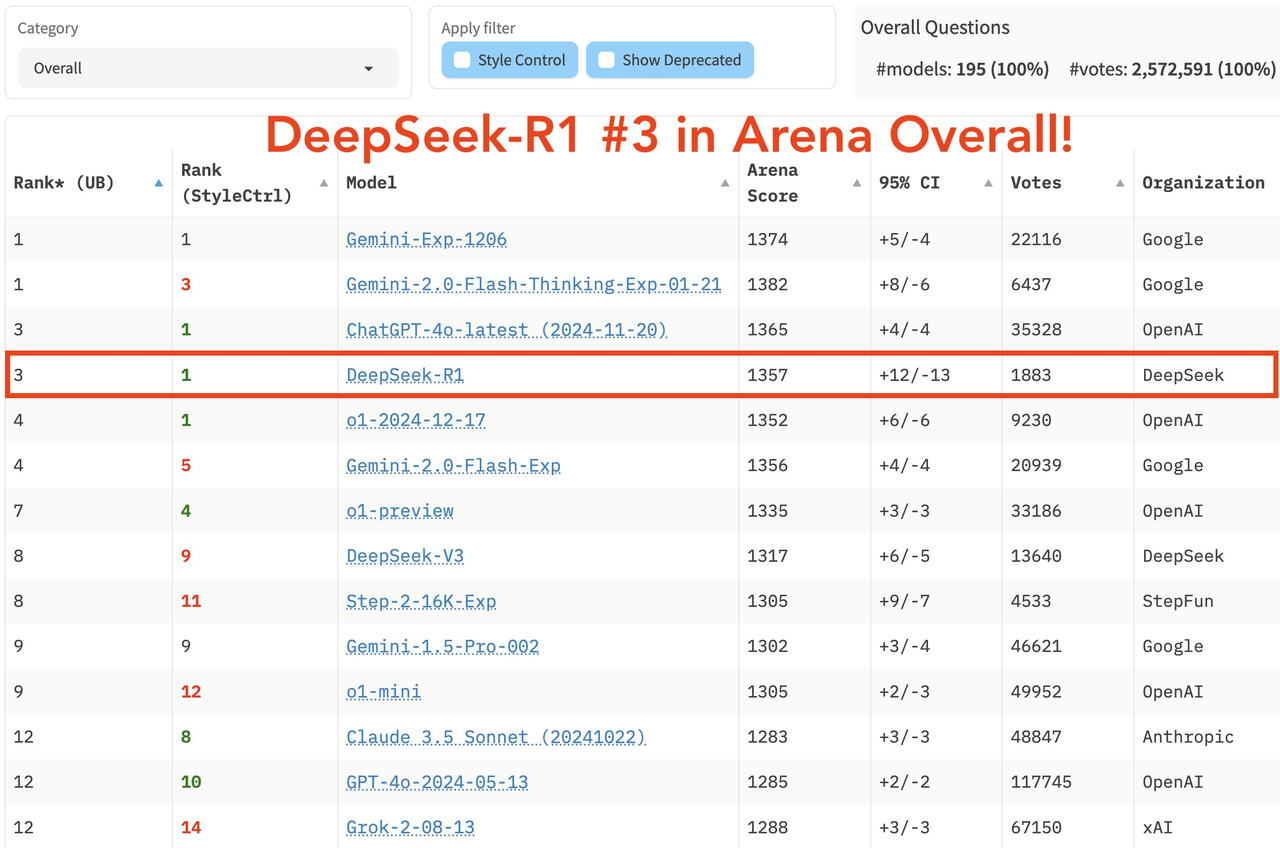
В последнем комплексном списке крупных моделей арены LM Arena DeepSeek R1 занял третье место, уступив o1.
- В областях «Жесткие подсказки» (сложные слова-подсказки), «Кодирование» (умение кодировать) и «Математика» (математические способности) DeepSeek R1 занимает первое место.
- По показателю «Контроль стиля» DeepSeek R1 и o1 разделили первое место.
- В тесте «Жесткая подсказка с контролем стиля» DeepSeek R1 также разделил первое место с o1.
Что касается стратегии открытого исходного кода, R1 использует лицензию MIT, предоставляющую пользователям максимальную свободу использования, и поддерживает дистилляцию моделей, которая позволяет выделить возможности рассуждения в более мелкие модели. Например, модели 32B и 70B достигли эталонного уровня o1-mini. многочисленные возможности Эффект открытого исходного кода даже превосходит Meta, который ранее подвергался критике.
Появление DeepSeek R1 впервые позволяет отечественным пользователям бесплатно использовать модели уровня o1, преодолевая давние информационные барьеры. Ажиотаж, который он вызвал на социальных платформах, таких как Xiaohongshu, можно сравнить с GPT-4 на момент его выпуска.
Выйти к морю и инволютировать
Оглядываясь назад на траекторию развития DeepSeek, можно ясно увидеть ее код успеха. Сила — это основа, но узнаваемость бренда — это ров.
В беседе с «Later» генеральный директор MiniMax Ян Цзюньцзе подробно поделился своими мыслями об индустрии искусственного интеллекта и стратегических изменениях компании. Он выделил два ключевых поворотных момента: во-первых, признание важности технологического брендинга и, во-вторых, понимание ценности стратегии открытого исходного кода.
Ян Цзюньцзе считает, что в сфере искусственного интеллекта скорость технологической эволюции важнее текущих достижений, а открытый исходный код может ускорить этот процесс за счет обратной связи с сообществом. Во-вторых, сильный технологический бренд имеет решающее значение для привлечения талантов и приобретения ресурсов.
Возьмем в качестве примера OpenAI. Несмотря на то, что в более поздний период компания столкнулась с управленческими потрясениями, ее инновационный имидж и дух открытого исходного кода, укоренившийся на раннем этапе, накопили о ней хорошую первую волну впечатлений. Несмотря на то, что в будущем Клод стал технически равным и постепенно поглотил пользователей B-стороны OpenAI, OpenAI все еще далеко впереди среди пользователей C-стороны из-за зависимости пользователей от пути.
В области искусственного интеллекта реальная конкурентная среда всегда глобальна, и выход за границу, инволюция и гласность также являются хорошим путем.

Эта волна выхода на мировой рынок уже вызвала волнения в отрасли. Более ранние версии Qwen, Wall-facing Smart и совсем недавно DeepSeek R1, kimi v1.5 и Doubao v1.5 Pro уже вызвали настоящий переполох за рубежом.
Хотя 2025 год был назван первым годом умных тел и первым годом очков с искусственным интеллектом, этот год также станет важным первым годом для китайских компаний, занимающихся искусственным интеллектом, по выходу на мировой рынок, и выход на глобальный уровень станет неизбежным ключевым словом.
Более того, стратегия открытого исходного кода также является хорошим шагом, привлекающим большое количество технических блоггеров и разработчиков, которые спонтанно станут «водопроводной водой» DeepSeek. Технология во благо не должна быть просто лозунгом. От лозунга «ИИ для всех» к истине. Благодаря инклюзивности технологий DeepSeek встал на более чистый путь, чем OpenAI.
Если OpenAI позволяет нам увидеть силу ИИ, то DeepSeek заставляет нас поверить:
Эта сила в конечном итоге принесет пользу всем.
# Добро пожаловать на официальную общедоступную учетную запись WeChat Aifaner: Aifaner (идентификатор WeChat: ifanr). Более интересный контент будет предоставлен вам как можно скорее.
Ай Фанер | Исходная ссылка · Посмотреть комментарии · Sina Weibo