Red Magic Gaming Tablet 3 Pro: игровой планшет, который можно держать в одной руке, когда вы на улице, и универсальная игровая консоль дома

11 июня компания Red Magic выпустила новое поколение игровых планшетов — Red Magic Gaming Tablet 3 Pro, представляющее собой по-настоящему компактный планшет с флагманской производительностью.
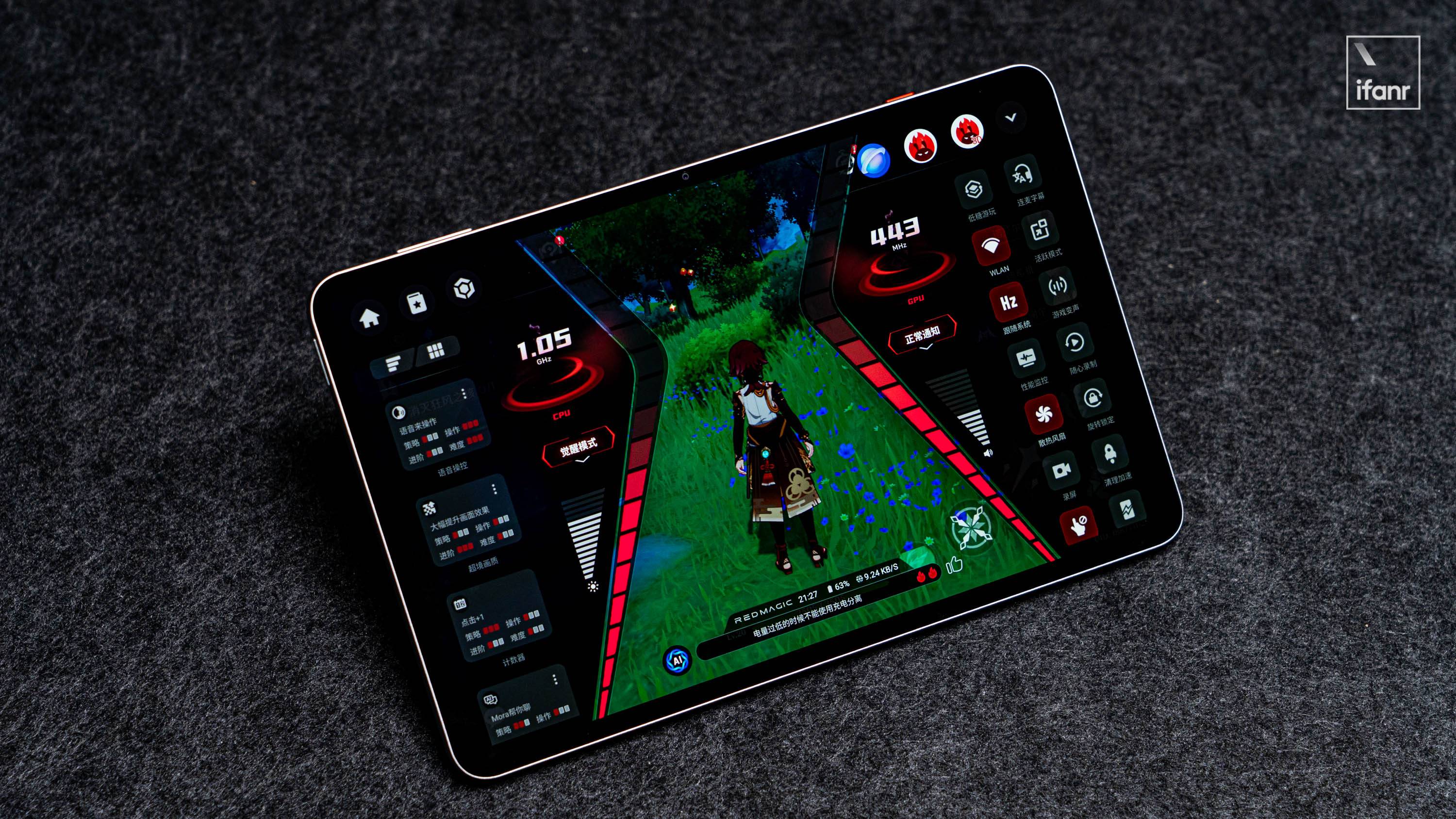
Планшет оснащен мобильной платформой Qualcomm Snapdragon 8 Extreme Edition и чипом Redcore R3 Pro, поддерживает игровое ядро CUBE и оснащен комбинацией памяти LPDDR5T и UFS4.1 Pro. Можно сказать, что это полноценная флагманская конфигурация мобильного телефона. При комнатной температуре его оценка AnTuTu составляет 2945910.
Планшет, созданный на основе флагманской конфигурации двухъядерного процессора, способен достигать сверхвысокого разрешения 2K+120 Гц и сверходновременной обработки кадров в большинстве популярных игр, поддерживает частоту 120 кадров в секунду для Peace Elite, адаптацию высокой частоты обновления 90 Гц для Mingchao и Blade & Soul, адаптацию трассировки лучей 144 Гц для Dark Zone Breakout и адаптацию высокой четкости 144 Гц для Delta Force.

Кроме того, на этот раз он также оснащен эмулятором ПК и поддерживает внешние клавиатуры, мыши, контроллеры и мониторы, так что вы можете играть в масштабные игры на планшете дома в режиме консоли.

Что касается аккумулятора, Red Magic Gaming Tablet 3 Pro имеет встроенный аккумулятор емкостью 8200 мАч, поддерживает быструю зарядку 80 Вт и обходной источник питания, и может быть полностью заряжен за 71 минуту с помощью официального комплекта быстрой зарядки USB-C to C мощностью 80 Вт. В то же время он также поддерживает быструю зарядку PD PPS мощностью 50 Вт, а время, необходимое для полной зарядки от 0 до 100 в фактическом максимальном состоянии Вт, также составляет около 70 минут.
Если есть обходной источник питания, он может уменьшить нагрев и потерю заряда батареи во время игры. Однако, сталкиваясь с большим планшетом, было бы лучше, если бы Red Magic мог предоставить дополнительный порт C.

Корпус оснащен 9-дюймовым OLED-экраном с соотношением сторон 16:10, максимальной общей яркостью 1100 нит и динамическим коэффициентом контрастности до 1000000:1, что обеспечивает высокую четкость и прозрачность изображения как для игр, так и для повседневного просмотра.
Передняя часть планшета использует сверхтонкую конструкцию рамки, которая может вместить 9-дюймовый экран в 8-дюймовый корпус, а ширина корпуса может контролироваться до такой степени, что его можно будет обхватить одной рукой. Независимо от того, носите ли вы только небольшую сумку во время путешествия или кладете его в карман брюк, он очень удобен.
Задняя крышка выполнена в популярном плоском дизайне Red Magic с дейтериевой передней панелью. Плоский и не выступающий DECO имеет прозрачную крышку, простирающуюся до нижней части корпуса. Внутри вы можете увидеть логотипы Snapdragon 8 Extreme Edition и Red Magic, а также некоторые детали декора печатной платы. С серебристым корпусом проявляется фирменное чувство технологии Red Magic.
Кнопки сосредоточены на верхней стороне корпуса. Помимо стандартной кнопки питания и кнопки регулировки громкости, Red Magic также оснащен специальным переключателем для входа в игровой режим.

Наконец, давайте взглянем на цену. Red Magic Gaming Tablet 3 Pro доступен в двух цветах: Deuterium Front Transparent Silver Wing и Deuterium Front Transparent Dark Night, с тремя версиями хранилища:
- 12 ГБ + 256 ГБ 3999 юаней
- 16 ГБ + 512 ГБ 4699 юаней
- 24 ГБ + 1 ТБ 5499 юаней
#Добро пожаловать на официальный публичный аккаунт WeChat iFanr: iFanr (WeChat ID: ifanr), где вам будет представлен еще более интересный контент как можно скорее.
iFanr | Исходная ссылка · Просмотреть комментарии · Sina Weibo